







自从 ChatGPT 横空出世以来,自然语言处理(Natural Language Processing,NLP) 研究领域就出现了一种消极的声音,认为大模型技术导致 NLP “死了”。在某乎上就有一条热门问答,大家热烈地讨论了这个问题。

有人认为 NLP 的市场肯定有,但 NLP 的研究会遇到麻烦,因为大模型的训练建立在海量数据与超高算力之上,普通研究者难以获取这样的资源,只能做些应用研究;也有人认为大模型为 NLP 打开了一片新天地,NLP 的研究整体上会再上一个新台阶。
看看专家们怎么说,上海交通大学 ACM 班创办人俞勇教授等几位 AI 学界大咖认为,不了解过去,就无法理解当下。NLP 技术的发展历经了几十年,期间经历了多次重大技术革新,如果我们的讨论脱离历史发展,那是没有意义的。
所以俞勇教授等大佬们决心为 NLP 技术编写一本在历史和现代之间更加平衡的教科书——《动手学自然语言处理》,这本书将为我们讲透 NLP 的经典技术,梳理整个领域的发展脉络,启发我们思考 NLP 的未来。

购买链接:https://item.jd.com/14544280.html
本书介绍自然语言处理的原理和方法及其代码实现,是一本着眼于自然语言处理教学实践的图书。
本书分为3个部分。第一部分介绍基础技术,包括文本规范化、文本表示、文本分类、文本聚类。第二部分介绍自然语言的序列建模,包括语言模型、序列到序列模型、预训练语言模型、序列标注。第三部分介绍自然语言的结构建模,包括成分句法分析、依存句法分析、语义分析、篇章分析。本书将自然语言处理的理论与实践相结合,提供所介绍方法的代码示例,能够帮助读者掌握理论知识并进行动手实践。
本书适合作为高校自然语言处理课程的教材,也可作为相关行业的研究人员和开发人员的参考资料。

本书将 NLP 的知识分为三部分,分别是基础、序列、结构。
第一步:基础
从最基础的自然语言处理技术入手,讲解了文本规范化、文本表示、文本分类和文本聚类等内容。通过学习这些基础知识,读者可以了解如何将文本转化为计算机可以理解和处理的形式,以及如何对文本进行分类和聚类,为后续的学习打下坚实的基础。
第二步:序列
书中深入探讨了自然语言的序列建模技术,包括语言模型、序列到序列模型、预训练语言模型和序列标注等内容。
通过学习这些内容,读者将了解对文本序列进行概率建模的方法。书中还介绍了预训练语言模型将语言模型和序列到序列模型在大量数据上进行预训练,获取通用语言学知识的过程。
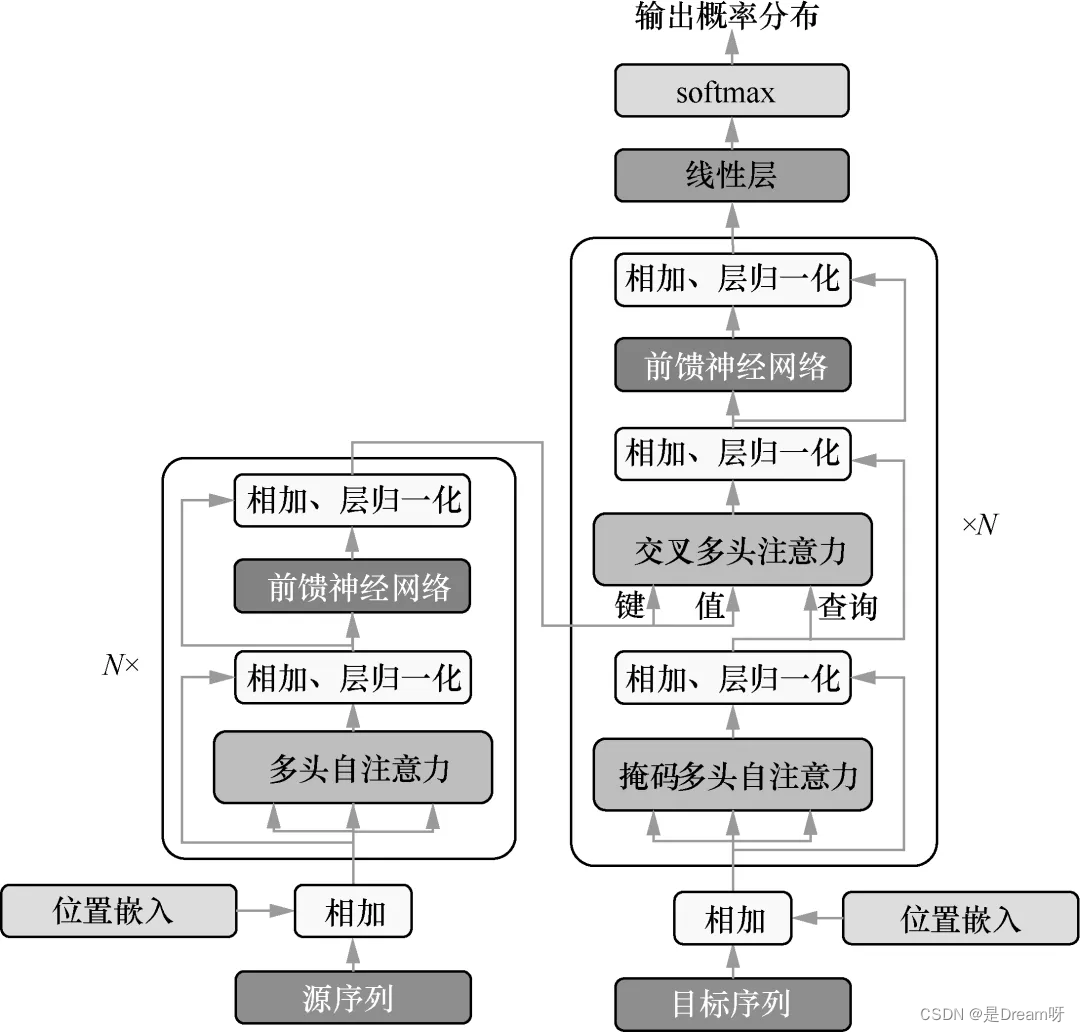
这部分内容是本书的重点,涵盖了当前应用最广泛的自然语言处理技术。读者可以学习到构成大模型的基础技术,包括循环神经网络、注意力机制、Transformer 模型。书中对这些知识点给出了详尽的代码说明,帮助读者全盘消化掌握。
第三步:结构
书中探讨了自然语言文字序列背后更为复杂的结构,包括句法结构、语义结构和篇章结构等内容。
学习这些知识,读者可以了解句子中词语之间的连接关系、文本表达含义的结构化表示,以及多个句子如何组合形成段落和文章,从而更深入地理解和应用自然语言处理技术。
这部分内容曾经是自然语言处理的主流技术,也很有可能是未来自然语言处理的重要发展方向,读者可以在这里探索将来的发展机会。
把这三步走好,读者就摸透了 NLP 技术,可以在工作中大显身手了。
NLP 的研究方法也许会改变,但是 NLP 的应用市场会更加广阔。学习 NLP 不仅要追踪热门技术,也要透彻了解 NLP 发展的来龙去脉,《动手学自然语言处理》就可以很好地帮助读者通盘掌握 NLP。
本书最大的特色就是理论与实践紧密结合,提供了大量的配套学习资源。我们来看一下究竟可以获得哪些资源:纸书 + 可以扫码观看的理论视频课 + 配套课件方便教学 + 课后习题 + 配套代码(可在线运行也可离线运行)+ 配套代码实战课 + 针对高校教师的师资培训计划。
这几乎就是背靠一个强大的后勤军团,读者根本不用担心学习中会遇到困难,只要将这些资源善加利用,定能啃透 NLP 技术。
如书名中的“动手学”所示,本书给读者提供了极其便利的学习环境,每一章都由一个 Python Notebook 组成, Notebook 中包括概念定义、理论分析、方法讲解和可执行代码。读者可根据自己的需要学习理论,或者动手实践。

本书深度整合了自然语言处理的理论精髓与实战智慧,内容讲解深入浅出、代码实例丰富易学,为培养自然语言处理领域的实战型人才提供了坚实的理论基石与丰富的实战资源,是渴望学习自然语言处理的读者必备的入门宝典。
——文继荣 中国人民大学高瓴人工智能学院执行院长、信息学院院长
在智能化浪潮下,懂技术、知应用的实战型人工智能人才的重要性日益凸显。本书以深入浅出的理论讲解为基础,辅以清晰明了的代码解析,帮助读者将自然语言处理的理论与实战融会贯通,值得广大读者深度研读。
——周明 澜舟科技创始人,ACL 原主席,CCF 原副理事长,微软亚洲研究院原副院长
学习自然语言处理需要将理论与实战相结合。本书凭借其详尽的理论阐述、可运行的代码实例以及配套的习题与教学资源,构建了一座连接理论与实战的桥梁。无论是新手还是老手,均可使用本书深化对自然语言处理的理解并提升实战能力。
——邱锡鹏 复旦大学计算机科学技术学院教授
本书具有两大亮点。一是以序列和结构为主线来组织自然语言处理的关键技术。序列、结构和语义是语言文字的3个重要属性,语言文字是离散符号的序列,文本又由带有语义信息的结构组成。二是以指导动手实战为目标,每个章节均提供可执行代码,并加以解读。本书非常适合作为自然语言处理领域的高校教材,也适合作为工程师的常备工具书。
——李磊 卡内基梅隆大学计算机科学学院助理教授
本书作为一本全面且系统的自然语言处理教材,深入浅出地讲解了自然语言处理的基本概念和关键方法,无论是学生还是行业人士,都能够通过本书有效掌握自然语言处理的知识体系并进行动手实战。
——杨笛一 斯坦福大学计算机科学系助理教授
第 1章 初探自然语言处理 1
1.1 自然语言处理是什么 1
1.2 自然语言处理的应用 2
1.3 自然语言处理的难点 3
1.4 自然语言处理的方法论 4
1.5 小结 5
第 一部分 基础
第 2章 文本规范化 8
2.1 分词 8
2.1.1 基于空格与标点符号的分词 8
2.1.2 基于正则表达式的分词 9
2.1.3 词间不含空格的语言的分词 12
2.1.4 基于子词的分词 13
2.2 词规范化 17
2.2.1 大小写折叠 17
2.2.2 词目还原 18
2.2.3 词干还原 19
2.3 分句 19
2.4 小结 20
第3章 文本表示 22
3.1 词的表示 22
3.2 稀疏向量表示 24
3.3 稠密向量表示 25
3.3.1 word2vec 25
3.3.2 上下文相关词嵌入 30
3.4 文档表示 30
3.4.1 词-文档共现矩阵 31
3.4.2 TF-IDF加权 31
3.4.3 文档的稠密向量表示 33
3.5 小结 33
第4章 文本分类 35
4.1 基于规则的文本分类 35
4.2 基于机器学习的文本分类 36
4.2.1 朴素贝叶斯 36
4.2.2 逻辑斯谛回归 42
4.3 分类结果评价 45
4.4 小结 47
第5章 文本聚类 49
5.1 k均值聚类算法 49
5.2 基于高斯混合模型的最大期望值算法 53
5.2.1 高斯混合模型 53
5.2.2 最大期望值算法 53
5.3 无监督朴素贝叶斯模型 57
5.4 主题模型 60
5.5 小结 61
第二部分 序列
第6章 语言模型 64
6.1 概述 64
6.2 n元语法模型 66
6.3 循环神经网络 67
6.3.1 循环神经网络 67
6.3.2 长短期记忆 73
6.3.3 多层双向循环神经网络 76
6.4 注意力机制 80
多头注意力 83
6.5 Transformer模型 85
6.6 小结 91
第7章 序列到序列模型 93
7.1 基于神经网络的序列到序列模型 93
7.1.1 循环神经网络 94
7.1.2 注意力机制 96
7.1.3 Transformer 98
7.2 学习 101
7.3 解码 106
7.3.1 贪心解码 106
7.3.2 束搜索解码 107
7.3.3 其他解码问题与解决技巧 110
7.4 指针网络 111
7.5 序列到序列任务的延伸 112
7.6 小结 113
第8章 预训练语言模型 114
8.1 ELMo:基于语言模型的上下文相关词嵌入 114
8.2 BERT:基于Transformer的双向编码器表示 115
8.2.1 掩码语言模型 115
8.2.2 BERT模型 116
8.2.3 预训练 116
8.2.4 微调与提示 117
8.2.5 BERT代码演示 117
8.2.6 BERT模型扩展 121
8.3 GPT:基于Transformer的生成式预训练语言模型 122
8.3.1 GPT模型的历史 122
8.3.2 GPT-2训练演示 123
8.3.3 GPT的使用 125
8.4 基于编码器-解码器的预训练语言模型 128
8.5 基于HuggingFace的预训练语言模型使用 129
8.5.1 文本分类 129
8.5.2 文本生成 130
8.5.3 问答 130
8.5.4 文本摘要 131
8.6 小结 131
第9章 序列标注 133
9.1 序列标注任务 133
9.1.1 词性标注 133
9.1.2 中文分词 134
9.1.3 命名实体识别 134
9.1.4 语义角色标注 135
9.2 隐马尔可夫模型 135
9.2.1 模型 135
9.2.2 解码 136
9.2.3 输入序列的边际概率 137
9.2.4 单个标签的边际概率 138
9.2.5 监督学习 139
9.2.6 无监督学习 139
9.2.7 部分代码实现 141
9.3 条件随机场 146
9.3.1 模型 146
9.3.2 解码 147
9.3.3 监督学习 148
9.3.4 无监督学习 149
9.3.5 部分代码实现 149
9.4 神经序列标注模型 154
9.4.1 神经softmax 154
9.4.2 神经条件随机场 154
9.4.3 代码实现 155
9.5 小结 156
第三部分 结构
第 10章 成分句法分析 160
10.1 成分结构 160
10.2 成分句法分析概述 161
10.2.1 歧义性与打分 161
10.2.2 解码 162
10.2.3 学习 162
10.2.4 评价指标 163
10.3 基于跨度的成分句法分析 163
10.3.1 打分 164
10.3.2 解码 165
10.3.3 学习 170
10.4 基于转移的成分句法分析 173
10.4.1 状态与转移 173
10.4.2 转移的打分 174
10.4.3 解码 175
10.4.4 学习 176
10.5 基于上下文无关文法的成分句法分析 177
10.5.1 上下文无关文法 177
10.5.2 解码和学习 178
10.6 小结 179
第 11章 依存句法分析 181
11.1 依存结构 181
11.1.1 投射性 182
11.1.2 与成分结构的关系 182
11.2 依存句法分析概述 184
11.2.1 打分、解码和学习 184
11.2.2 评价指标 184
11.3 基于图的依存句法分析 185
11.3.1 打分 185
11.3.2 解码 186
11.3.3 Eisner算法 186
11.3.4 MST算法 191
11.3.5 高阶方法 194
11.3.6 监督学习 194
11.4 基于转移的依存句法分析 195
11.4.1 状态与转移 196
11.4.2 打分、解码与学习 196
11.5 小结 198
第 12章 语义分析 200
12.1 显式和隐式的语义表示 200
12.2 词义表示 201
12.2.1 WordNet 201
12.2.2 词义消歧 203
12.3 语义表示 204
12.3.1 专用和通用的语义表示 204
12.3.2 一阶逻辑 205
12.3.3 语义图 205
12.4 语义分析 206
12.4.1 基于句法的语义分析 206
12.4.2 基于神经网络的语义分析 207
12.4.3 弱监督学习 209
12.5 语义角色标注 209
12.5.1 语义角色标注标准 209
12.5.2 语义角色标注方法 211
12.6 信息提取 211
12.7 小结 212
第 13章 篇章分析 213
13.1 篇章 213
13.1.1 连贯性关系 213
13.1.2 篇章结构 214
13.1.3 篇章分析 215
13.2 共指消解 215
13.2.1 提及检测 216
13.2.2 提及聚类 216
13.3 小结 220
总结与展望 221
参考文献 223
中英文术语对照表 228
附 录 234
















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











