







1.为什么要进行主成分分析
主成分分析(PCA)是一种多元技术,用于降低数据集的维数,同时尽可能多地保留数据中的信息。
主成分分析的主要目的是为了降维,如果有个非常大的数据矩阵,例如n行m列的数据,直接观察数据信息是不可行的,用降维的方式可以观察到数据中的趋势,例如一个三维数据,就可以降维成二维平面数据,那么PCA分析就是要通过寻找一个最好的方式,使之能够最大还原数据原本的信息,又能是较低维度的数据。
例如如下图:

一个3D数据投影成2D数据,但是我们很难看出来原始数据是什么信息。
再看下图,通过分析原始数据在主成分上的投影,可以更好的捕捉到原始数据的信息,又起到了降维的作用。

如何理解这些呢?后面详细讲述。
2.理解主成分分析背后的原理
降维
当数据只有XY两列的时候,我们可以绘制一个平面图,直观的表示这两个变量之间的关系,但是随着数据量的增加,我们想要理解每个变量之间的关系变得困难。
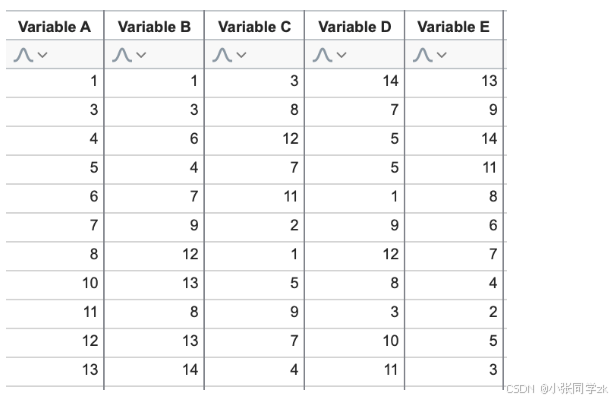
我们可以用下图的方式绘制出ABC变量之间的关系,C代表颜色,然而,即使有了该图,变量A与变量C(以及变量B与变量C)之间的任何关系均不明显。随着变量A(或变量B)的值增加,变量C的值的模式似乎不可预测。
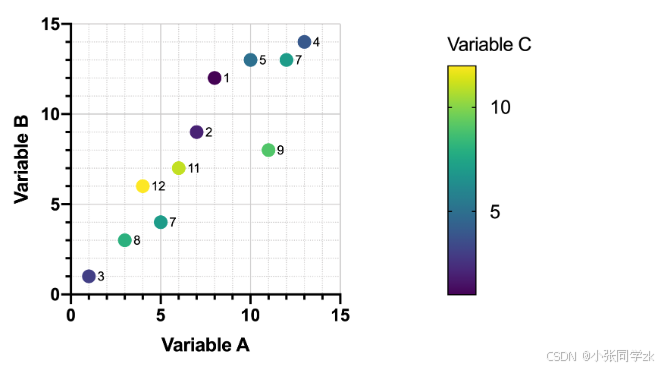
可以向该图中添加一个附加变量,使用其值来确定符号尺寸。在下图中,符号尺寸与变量D的值成比例。然而,随着数据行数的增加,这种图表变得更加难以阅读,关系当然不会显而易见。
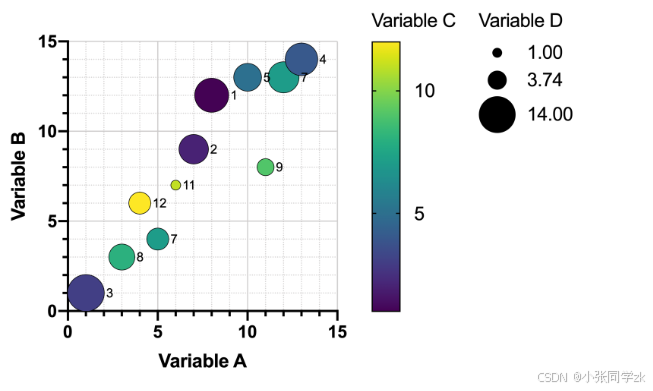 如果数据量更大的话,更加难以在一个图中呈现出所有变量数据。
如果数据量更大的话,更加难以在一个图中呈现出所有变量数据。
因此需要用PCA分析进行降维处理,以更加全面的理解多维数据之间的关系
特征选择和特征提取
在我学习的过程中,难住我的就是如何理解PCA降维,特征选择又是什么意思。经过我的详细理解和琢磨,终于有了一些理解。
“特征”两个字其实不必去弄懂具体指代的是什么,其实就是一种变量,通过一种关系来表示原始变量。
通过特征选择,首先考虑所有变量,然后基于特定的标准,删除一些变量。其余变量可能会经历多轮附加选择,选择出来的一些特征能够更加全面的表示原始数据。
PCA对原始变量进行线性组合来导出新的特征集(在PCA中,我们称这些新特征为主成分,或PC)。
PCA真正重要的部分是如何去定义PC,即如何去寻找主成分,将原始数据投影到低维空间(主成分上),同时最小化信息损失。就是鱼的那个图,如何进行投影,使我们能够观测出原始的数据模样,又起到降维的作用。这其实就是PCA主要干的事。
投影
假如有这样的两列数据
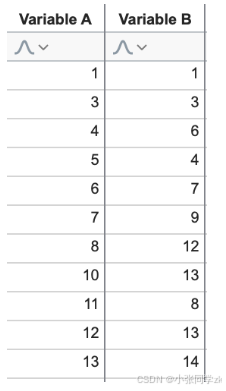
这是在二维平面上的表示方法
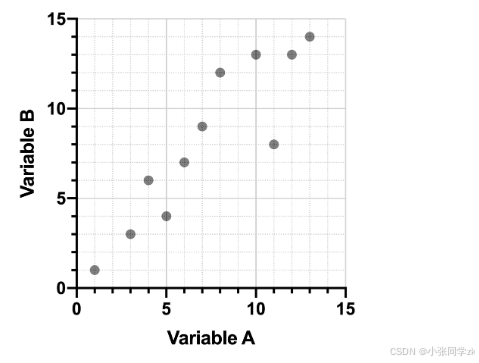
将数据投影到X轴上如下图
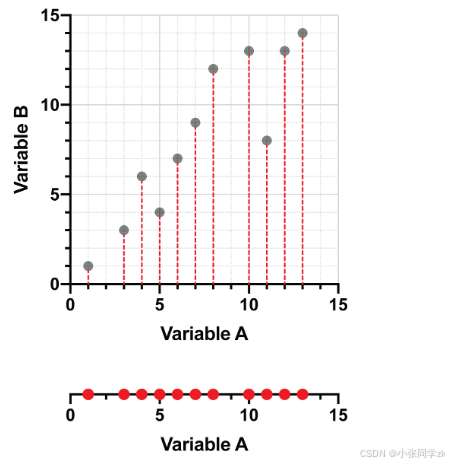
将数据投影到Y轴,如下图:
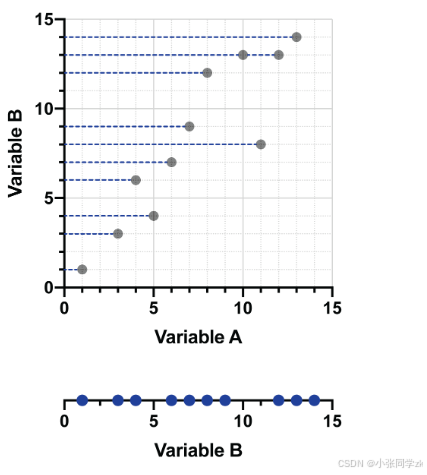
通过投影来减少数据的维度信息。但是投影到X轴,会损失数据B的信息,投影到Y轴会损失数据A的信息,因此要找到一种最佳的线,使两个数据损失的信息最少。
投影到其他线上
线性回归是将点投影到线上的一种极其常见的方法。通常,以最小化点线之间垂直距离的平方和的方式执行回归。考虑以下两张图表:
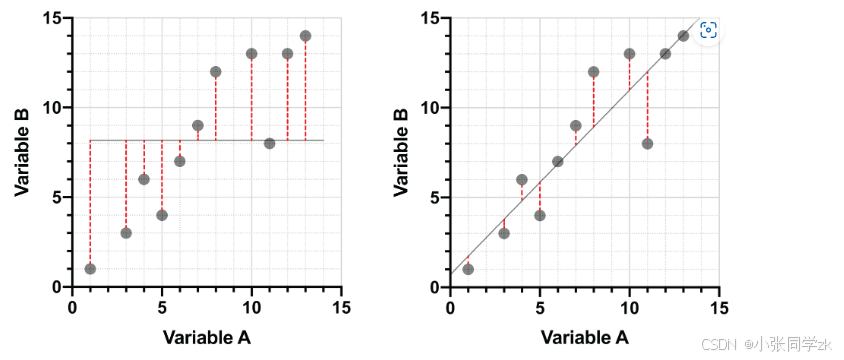
左边图表上,点与线之间的垂直距离过大,这是一条拟合不良的线。右边图表上,已最小化垂直距离,这是数据的最佳拟合线,且是沿Y方向上的投影,也可以沿X方向上投影。
还有一种更好的投影方式,是同时最小化两个方向上的投影,如下图
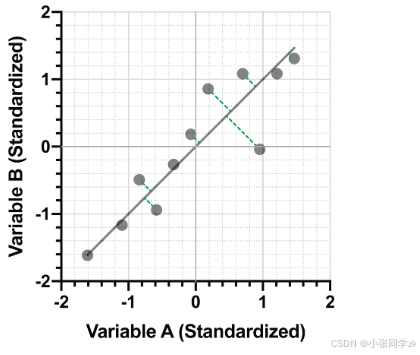
这是标准化的数据,相对于原始数据只是进行了平移,使得点云的“中心”位于原点(0,0)。数据在X和Y方向的比例也发生了变化,但由于两组的标准差相似(变量A标准差为3.90,变量B标准差为4.45),散点图的整体形状并无太大变化。
使用标准化数据,现在让我们看看如何将这些点投影到一条线上,同时使得点和线之间的水平和垂直距离最小化。由于我们对数据进行了标准化处理(即X和Y方向的方差相同),因此与最小化点和线之间的垂直距离相同。
通过最小化点和线之间的垂直距离,得到了最佳的拟合曲线,使得标准化数据在拟合线上的投影数据的方差最大,这就是PCA分析的关键。
•最小化原始数据投影到拟合线上造成的信息损失
•最大化原始数据投影到拟合线上的方差
下图更加清晰,标准数据点和拟合线之间的垂直:
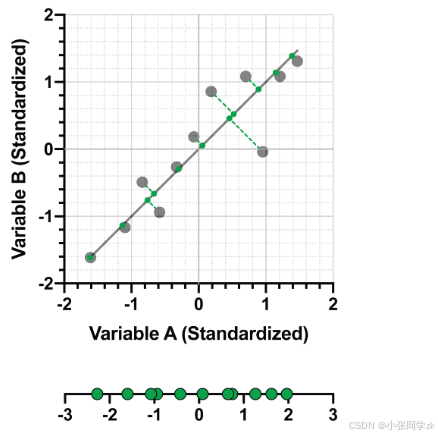
下图的拟合线的投影距离就很大,并且投影数据更接近于聚集在线上
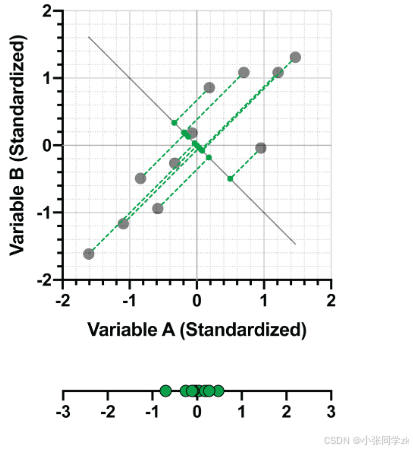
最小化数据点和拟合线之间的垂直距离相当于最大化数据矩阵在拟合线上的方差。
PCA主要做的就是:通过将数据投影到低维度上来说明数据中最大的方差。
是在有很多变量的情况下进行PCA。只有两个变量时,就不需要降维了,以上只是举例分析。
3.PCA分析的步骤
首先对数据矩阵进行标准化
![]()
其中,xstd是标准化值,xi是原始值,x̄是变量的平均值,sx是变量的标准偏差。实际上,该方法转换数据的方式是每个变量的平均值为零,标准偏差为1。随后,每个变量的方差为1,因为方差只是标准偏差的平方:
![]()
这一步对于确保PCA的结果得到正确解释非常重要,因为PCA对原始变量的方差非常敏感。
在确定如何最好地降低数据集的维度时,PCA要确定哪些变量“最为重要”,就是哪些变量呈现最大的方差。
如果原始变量的方差彼此相差很大,分析结果会偏向方差较大的变量,而忽略方差较小的变量。
PCA分析
•主成分是原始数据(标准化)的线性组合
•这些线性组合表示数据可以投影到的线
•存在许多可以投影数据的可能线
•主成分的确定方法是数据方差最大化
数据方差最大化确定主成分
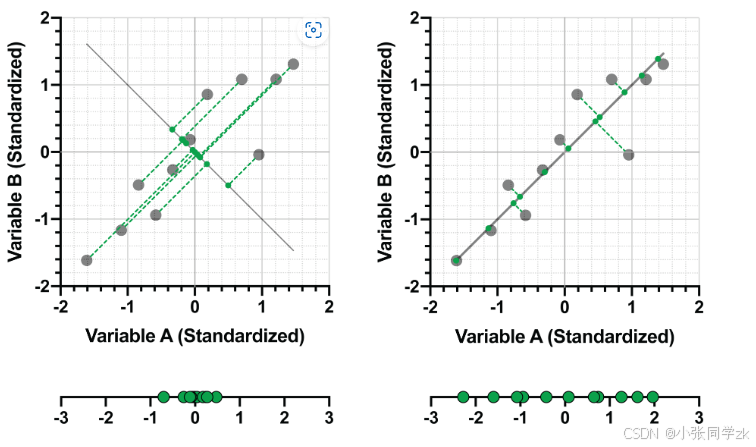
正如前面所说那条最佳的线性拟合线,就是该数据矩阵的第一个主成分,上面图片左图,一条未能很好的将距离最小化以及方差最大化的线。右图,表示了数据矩阵最佳拟合线的图表。在上述示例的右图中,线(我们称之为PC1的“第一主成分”)可以表示为两个(标准化)变量的线性组合。对于本示例:
PC1=0.707*(变量A)+0.707*(变量B)
特别注意:这种线性组合的系数可以用矩阵表示,在本表格中称为“特征向量”。该矩阵通常是PCA的结果
因此,可以使用更少的变量来近似得到(“重建”)原始数据(降维)。下列表格示出了将变量A和变量B的值插入该等式时的结果值:
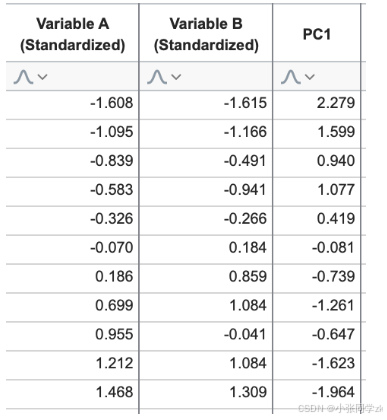
PC1的这些值称为PC1的“评分”,代表投影的数据在此PC上的位置(见上文右图中的数字线,并将其与第三列中的值进行比较)。
确定了可以将原始数据进行最佳的投影的拟合线,那么第一部分的图像,就能够看的更加清晰。
没有投影好的图像
投影好的图像
确定第二个主成分
第二个主成分是用来补充第一个主成分未充分说明的额外信息(方差)。第二个主成分是和第一个主成分正交的向量,以此来补充额外的信息。如下图的右图
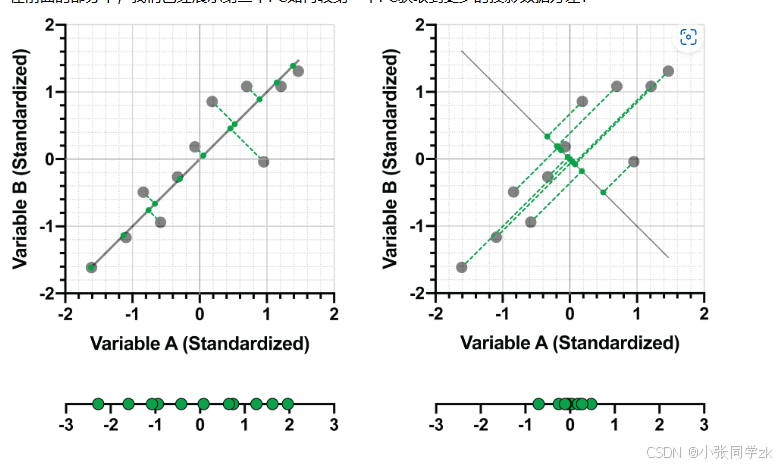
PC1=0.707*(变量A)+0.707*(变量B)
PC2=-0.707*(变量A)+0.707*(变量B)
这种线性组合的系数可以用矩阵表示
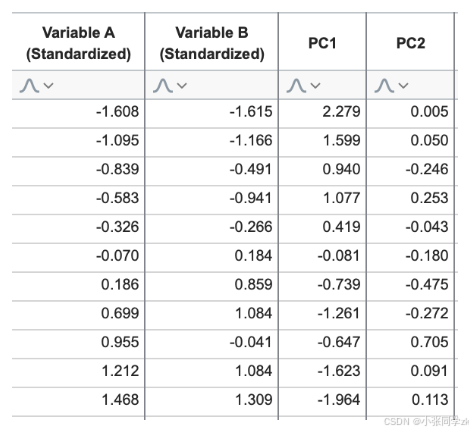
如果原始数据包含更多变量,则可以简单地重复该过程:
•找到一条将该线上的投影数据方差最大化的线。这是第一个PC
•找到一条将该线上的投影数据方差最大化的线,并与先前识别的每个PC正交。这是下一个PC
想象该过程在二维空间中如何以非常直接的方式起作用。另外,也可以了解三维空间中的三条线如何能够以90°角全部相交(考虑一个3D图表的X、Y、Z轴;这些轴均以直角彼此相交)。然而,随着原始数据维度的增加,可能的PC数量也随之增加,将该过程可视化的能力变得非常复杂(试着在6维空间中将一条与其他5条线相交的线可视化,所有这些线必须以90度角相交……)。
还好,为一个数据集识别所有后续PC的过程与识别前两者是相同的。最后,您会看到PC的排列顺序,第一个PC“解释”数据的最大方差量,第二个PC“解释”第二大方差量,依此类推。下一部分讨论了如何呈现该“解释方差”的数量,以及可以根据该信息做出什么决策来实现PCA的目标,那就是:降维。
非您进入计算数值的必要矩阵代数,否则查找“特征值”或“特征向量”的严格定义无法得出关于这些数值表示什么的合理解释。相反,让我们回到我们的数据可视化表示和为其识别的第一个主成分:
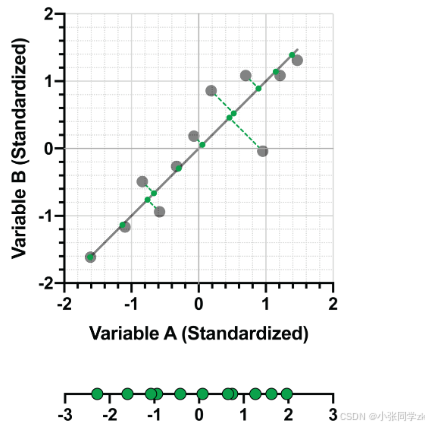
给出该PC,作为线性组合:
PC1=0.707*(变量A)+0.707*(变量B)
变量A的系数为0.707,变量B的系数为0.707,这两个系数共同表示PC1的特征向量。简言之,这些数值表示第一个主成分的“方向”,就像斜率代表回归线的方向一样。从上图的坐标点(0,0)开始,可以看出线的“方向”在变量A轴上向右0.707,在变量B轴上向上0.707。在这两点之间所画的直线就是PC1。
特别注意:特征向量(例如,所有向量)既有方向又有尺寸(例如,长度)。向量在二维空间中的方向可以由两个数值定义 - 向量在第一维方向上的成分以及向量在第二维方向上的成分。随着维度的增加,向量将需要更多数值来对其进行全面描述,与原始数据矩阵的维度匹配。在PCA中,单个特征向量对每个原始变量均有一个数值。
为什么特征向量以这些奇怪的十进制值结束,而非像1和1这样简单的数值?归根结底是勾股定理。在前述示例中,PC1是从特征向量穿过坐标(0,0)和坐标(0.707,0.707)的直线。如果我们要确定连接这两点的直线的长度(也称为向量的尺寸),我们会发现它等于1!
d = √[(0.707-0)2+(0.707-0)2]=1
*请注意,数值0.707是一个舍入值,因此上述等式只偏离了一点点
事实上,这是一个适用于所有PC特征向量的属性。特征向量的长度始终为1,这可以通过求特征向量值的平方和来进行验证。
特征向量表示每个主成分的方向,特征值表示主成分所解释的方差量
对于为单个数据集确定的一组PC,具有较大特征值的PC会比具有较小特征值的PC解释更多的方差。以此方式,可以认为特征值是伴随特征向量方向的PC的长度。请注意,在某些情况下,使用载荷(loading)描述原始变量与PC之间的关系
那么PC1和PC2的特征值是多少呢,就是使用线性组合和标准化数据为PC1和PC2计算的“评分”。
计算“PC1评分”和“PC2评分”列的标准偏差,然后计算这些数值的平方,就得到了特征值,分别为1.902和0.098
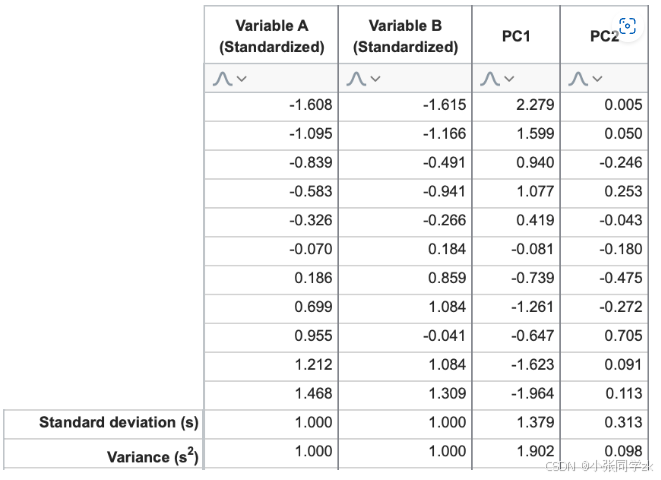
如果使用标准化数据进行分析,所有PC的特征值之和将等于原始变量的总数。为什么?
请记住,标准化数据会导致每个变量的方差等于1。通过扩展,数据集中的总方差等于变量的总数。每个PC“解释”一个等于其特征值的方差量,但不改变数据中的总方差量。由于将数据投影到新PC上不会消除任何方差,因此所有PC的解释方差之和必须等于总方差。因此,特征值之和=解释方差之和=总方差=原始变量数。
后面会写一个详细的Python代码计算PCA分析
本文主要参考:
GraphPad Prism 10 Statistics Guide - 主成分分析 (graphpad-prism.cn)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









