







1 时空编码器(Encoder)
下图就是时空编码器。由多层堆叠组成,每层包含两个基本模块:时间趋势感知多头自注意力模块和空间动态图卷积模块。前者用于建模时间维度上的交通数据动态,后者则捕捉空间维度上的相关性。
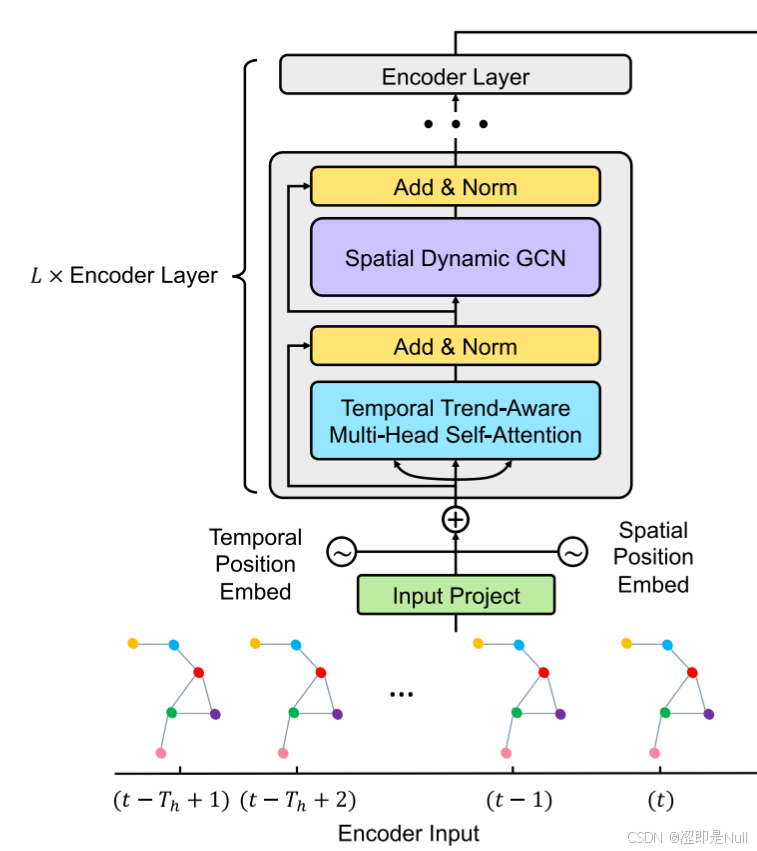
1.1 时间趋势感知多头自注意力
传统的多头自注意力通过线性投影将 Q,K,V 投射到不同的表示子空间后进行注意力计算,并最终将结果拼接后投射到输出。但它最初是为处理离散数据(如词汇)设计的,未能充分考虑连续数据中的局部趋势信息。因此,简单地将其应用于交通信号序列可能导致不匹配问题。例如,下图中,传统自注意力可能错误地将点A与B匹配,而忽略了它们的局部趋势完全不同。
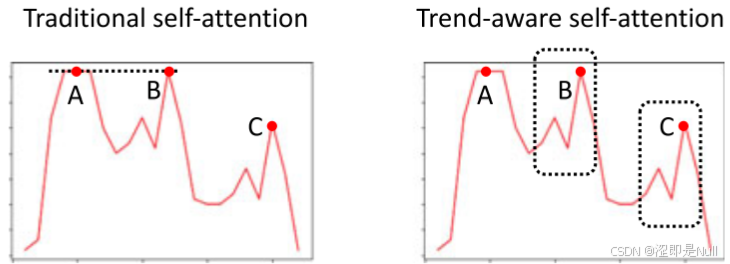
为了解决这一问题,本文设计了时间趋势感知多头自注意力机制,通过使用 1D 卷积替代 Q 和 K 的线性投影,从而结合局部上下文信息:
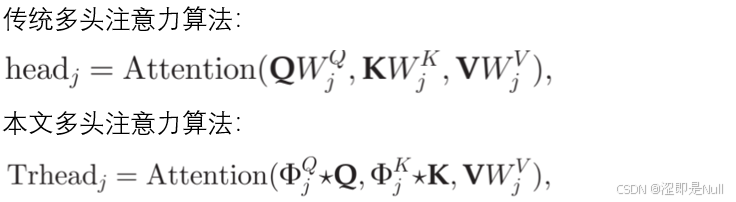
公式中,Φ 为卷积核参数,∗ 代表卷积操作。
class MultiHeadAttentionAwareTemporalContex_q1d_k1d(nn.Module):
def __init__(self, nb_head, d_model, num_of_weeks, num_of_days, num_of_hours, points_per_hour, kernel_size=3, dropout=.0):
super(MultiHeadAttentionAwareTemporalContex_q1d_k1d, self).__init__()
assert d_model % nb_head == 0
······
# 用于查询(Query)和键(Key)的1D卷积
self.conv1Ds_aware_temporal_context = clones(
nn.Conv2d(d_model, d_model, (1, kernel_size), padding=(0, self.padding)),
2
)
······
def forward(self, query, key, value, mask=None, query_multi_segment=False, key_multi_segment=False):
······
# 对查询和键执行1D卷积操作
query, key = [
l(x.permute(0, 3, 1, 2)).contiguous().view(nbatches, self.h, self.d_k, N, -1).permute(0, 3, 1, 4, 2)
for l, x in zip(self.conv1Ds_aware_temporal_context, (query, key))
]
# 对值(Value)执行线性变换
value = self.linears[0](value).view(nbatches, N, -1, self.h, self.d_k).transpose(2, 3)
# 应用自注意力
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
x = x.transpose(2, 3).contiguous().view(nbatches, N, -1, self.h * self.d_k) # 重新调整输出形状
return self.linears[-1](x)
1.2 空间动态卷积
传统的图卷积运算结构是静态的,即给定一个图 G,对应的权重矩阵 A 是一个常数。然而,对于交通网络来说,节点之间的相关性很可能会随着时间的推移而变化,简单地将 GCN 应用于交通网络将无法捕捉到这种动态。因此,本文参考了论文 DGCN(Dynamic Graph Convolution Net),自适应地调整节点之间的相关强度。
但与论文 DGCN 的计算方式上存在些许区别。回忆在论文 DGCN 中,先计算出了残差拉普拉斯矩阵 Lres 用于提供长期的全局图结构约束,然后计算出了动态邻接矩阵 Ld,最后 Lres 和 Ld 点乘同时保留 Ld 的动态变化性和 Lres 的全局稳定性。在计算顺序上,本文与 DGCN 大致相同。下面是计算上的区别:

本文的计算公式中,Zt 代表多头自注意力的输出结果,St 代表不同节点之间的相关强度(相当于论文 DGCN 的 Ld) ,A是一个静态权重矩阵(相当于论文 DGCN 的 Lres)。所以,本文的动态图卷积相对于论文 DGCN,相当于添加了多头自注意力。
# 1. 动态权重计算St
spatial_attention = self.SAt(x) # 动态权重矩阵(batch, T, N, N)
spatial_attention = spatial_attention.reshape((-1, num_of_vertices, num_of_vertices)) # (b*T, n, n)
# 2. 图卷积计算
x = x.permute(0, 2, 1, 3).reshape((-1, num_of_vertices, in_channels)) # (b*t,n,f_in)
return F.relu(self.Theta(torch.matmul(self.sym_norm_Adj_matrix.mul(spatial_attention), x)).reshape(
(batch_size, num_of_timesteps, num_of_vertices, self.out_channels)).transpose(1, 2))2 时空解码器(Decoder)
时空解码器以自回归方式生成输出序列,包括两个时间趋势感知多头注意力模块和一个空间动态图卷积模块。第一个模块捕捉解码器序列中的相关性,采用因果卷积避免未来信息泄露。第二个模块捕捉解码器序列与编码器输出之间的相关性。
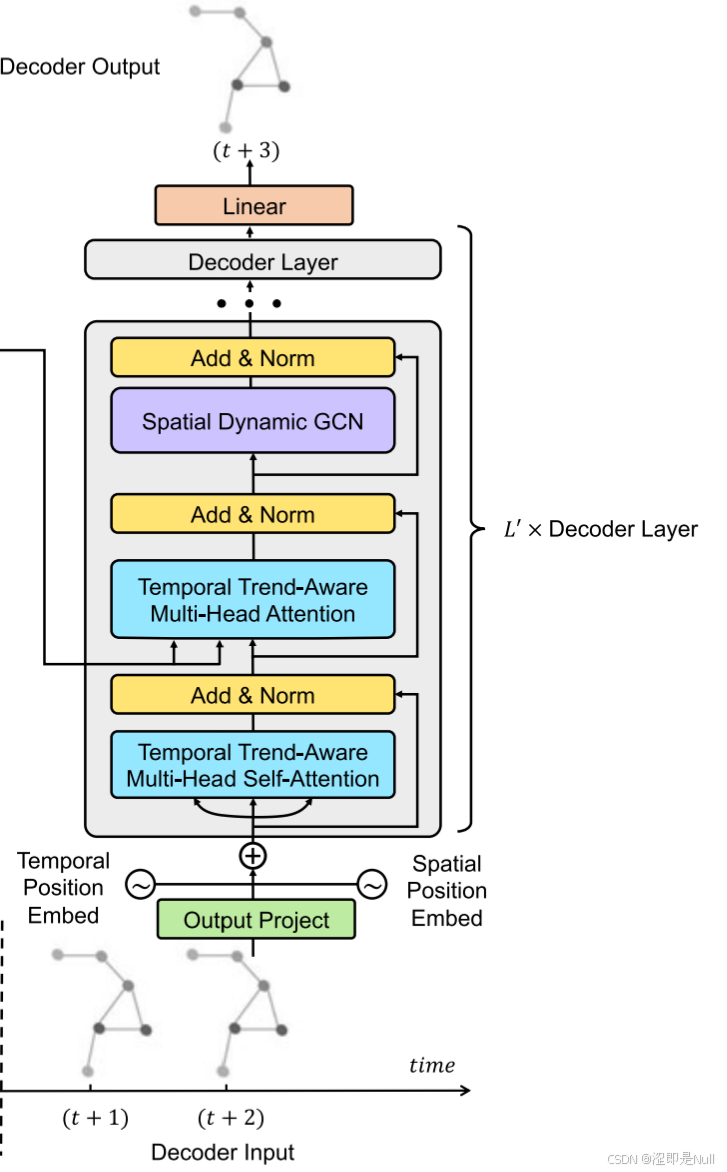
3 周期性处理
本文考虑了交通数据中两种周期模式:全局周期性(如每周的固定模式)和局部周期性(如连续几天的特定模式)。为捕捉这两种模式,在历史记录之外引入了两类额外的数据源:
- 全局周期张量(Global Periodic Tensor):捕捉固定时间间隔内、过去几周的交通数据。例如,要预测星期一早上 7:00 到 11:00 的交通状况,可以使用过去三周星期一的相同时间段数据。
- 局部周期张量(Local Periodic Tensor):捕捉过去几天的相同时间段的交通数据。例如,预测今天早上 7:00 到 11:00 的交通状况,可以使用过去两天的相同时间段数据。
将全局周期张量 Xg、局部周期张量 Xl 与历史记录张量 X 进行拼接后,形成输入张量,输入维度为 N × C × (w · Tp + d · Tp + Th)。
在使用周期性处理时,要使用数据集 PEMS04_rdw。
nohup python -u train_ASTGNN.py --config configurations/PEMS04_rdw.conf --cuda=1 > pems04_rdw.out &4 位置嵌入
位置嵌入(Positional Embedding)是一种将位置信息编码并融入模型输入的技术。它主要用于处理序列数据(如交通流量数据在时间和空间序列上的信息),特别是在基于 Transformer 架构的模型中。因为 Transformer 架构本身没有像循环神经网络(RNN)那样对序列顺序的内在感知,位置嵌入可以为模型提供位置线索,让模型知道输入数据的顺序和位置相关信息。
4.1 时间位置嵌入(Temporal Position Embedding)
自注意力机制本身对输入的顺序不敏感,而时间序列建模任务中,时间的邻近性往往起到关键作用。例如,下午 5:00 的交通流量与下午 5:30 的相关性更强,而与下午 4:00 的相关性较弱。通过为序列中的每个元素添加固定的相对位置嵌入(Fixed Positional Embedding),可以引入顺序偏置:
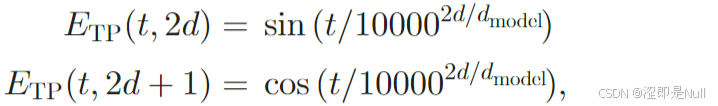
公式中,t 代表输入序列中每个元素的时间位置(或时间步)的索引。例如,对于一个时间序列,t 可以是从 1 到 Th 的整数,表示该元素在序列中的相对位置。d 表示嵌入向量的维度索引。位置嵌入矩阵通常是一个 维的向量(64维),每个维度的值用一个独特的函数来计算。偶数维使用正弦函数,奇数维使用余弦函数。奇偶维度交错使用三角函数,可以使得同一位置 t 在不同维度上有互补的信息,保证每个位置都拥有唯一且连续的表示。
这种表示可以帮助模型更好地捕捉时间序列中的周期性模式和邻近性信息。例如,对于 t 较接近的元素,它们的位置嵌入值会更加相似,从而让模型感知邻近性。而随着维度越高,对应的三角函数值就变化的越缓慢,就越能捕捉到更远的位置信息。
引入时间位置嵌入有助于模型更好地识别全局周期张量 Xg、局部周期张量 Xl 与历史记录张量 X 之间的相对位置关系,即便它们只是简单地连接在一起。
# 构造位置编码矩阵
pe = torch.zeros(max_len, d_model)
for pos in range(max_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000 ** ((2 * i) / d_model)))
pe[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1)) / d_model)))
# 引入时间位置嵌入
x = x + self.pe[:, :, :x.size(2), :]4.2 空间位置嵌入(Spatial Position Embedding)
在交通网络中,不同的交通监测点(如道路传感器)所处的位置不同,其交通流量模式可能受到周边道路布局、城市功能区分布等因素的影响。位置嵌入可以帮助模型区分不同监测点的数据,从而更好地捕捉交通流量在空间上的变化规律。例如,位于商业区的监测点在工作日白天可能交通流量较大,而位于住宅区的监测点早晚高峰流量模式可能不同。位置嵌入能够将这些空间位置差异信息传递给模型,使模型能够学习到基于位置的交通流量特征。
在这种情况下,可以采用几种可能的方法在图上对空间异质性进行建模。一种直接的方法是对每个节点的独特空间异质性进行独热编码。但是,高维稀疏特征不仅会导致高昂的计算成本,还会丢失图结构信息。另一种方法是采用无监督图嵌入方法,如 DeepWalk,来学习空间节点的表示。虽然它们可以保留图上邻居之间的相似性,但大多不适合特定的监督任务。
因此,为了在明确建模空间异质性的同时反映图结构信息,首先为每个节点分配一个额外的嵌入向量,得到一个初始空间位置嵌入矩阵 Esp(0)。然后通过一个图卷积层进行平滑处理(Laplacian Smoothing),得到最终的空间位置嵌入矩阵 Esp。
最终,时间位置嵌入矩阵 Etp 和空间位置嵌入矩阵 Esp 将分别添加到原始表示 X(0)。这是目前在交通预测任务中首次显式考虑空间异质性的尝试。
# 1. 获取每个节点的索引
x_indexs = torch.LongTensor(torch.arange(num_of_vertices)).to(x.device) # (N,)
# 2. 根据节点索引获取节点嵌入
embed = self.embedding(x_indexs).unsqueeze(0) # (N, d_model)->(1,N,d_model)
# 3. 如果配置了 GCN 平滑处理,则逐层平滑嵌入
if self.gcn_smooth_layers is not None:
for _, l in enumerate(self.gcn_smooth_layers):
embed = l(embed) # (1,N,d_model) -> (1,N,d_model)
# 4. 将嵌入与输入特征相加
x = x + embed.unsqueeze(2) # (B, N, T, d_model)+(1, N, 1, d_model)
return self.dropout(x)
















 1591
1591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









