







一、前言
因为是第一篇,所以这里记录一点基础:
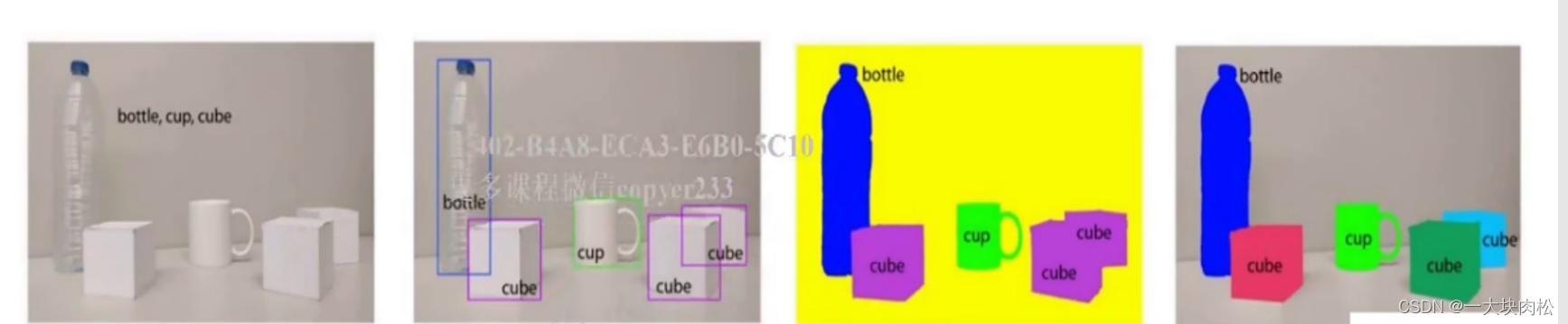
分类、检测、分割的区别:
(1)图像分类:只需要指明图像中相应目标所属的类别就可以;
(2)目标检测:需要定位到目标所处的位置,用矩形框表示;
(3)目标分割:a. 语义分割:需要找到当前目标所占的区域,去除背景区域,其他目标的区域;b. 实例分割:不仅需要区分不同语义的目标,而且对于同一类别的目标也需要划分出不同的实例;
下面这张图像就对应了上述的情况(图像来源)
接下来都是学习目标检测系列的网络(深度学习)
二、分类
1.Two-Stage目标检测算法
代表:
R-CNN
Fast-RCNN
Faster-RCNN
Mask-RCNN
2.One-Stage目标检测算法
代表:
YOLO系列
SSD系列
3.二者的区别
二者的最大区别在于是否包含RPN(候选区域目标推荐)的过程,即Two-Stage在进入网络前,需要先进行候选框的操作,分为两个阶段完成。
三、R-CNN(Region with CNN features)
1.总体
分为两个阶段:
第一阶段:目标候选框Object Proposals
第二阶段:proposal缩放后放入CNN网络

上图,R-CNN目标检测算法的步骤:
(1)利用Selective Search方法,在输入图像上选出2000个候选框
(2)将生成的所有候选框,每一个候选框resize之后(即所有的候选框都resize成相同尺寸),传入CNN网络,利用CNN提取特征,输出特征图;
(3)将特征图送入SVM二分类器,判断目标是否属于该类别;
(4)Bounding box regression,根据监督学习训练回归器,调整候选框的大小;
2.详细讲解上面的步骤
整个R-CNN结构分散,可以分为几个部分:候选框的生成、CNN网络、分类器、回归框,这几个部分都是需要单独训练,所以RCNN并不端到端的目标检测。
(1)Selective Search具体的过程:
- 使用一种过分割方法,将图像分割成比较小的区域;
- 计算所有邻近区域之间的相似性(可能属于同一个目标);
- 将相似性比较高的区域合并到一起;
- 计算合并区域和邻近区域的相似性;
- 迭代合并,聚合到2000张候选框,就可以停下来;
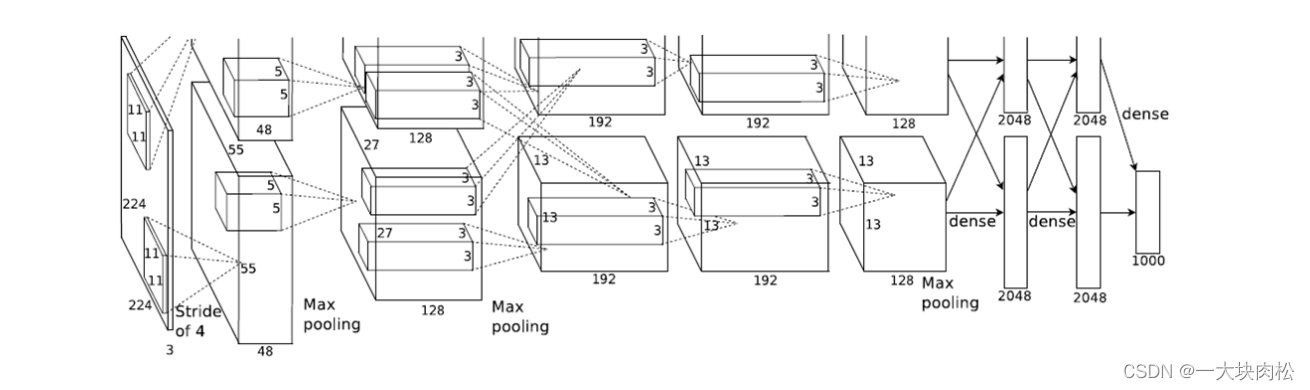
(2)CNN网络:
预训练的CNN网络,利用AlexNet网络,使用五个卷积层和两个全连接层,对输入的候选框进行特征提取,最终输出的是一个特征向量。
(3)分类:
R-CNN在每张图片上抽取了2000个候选框,resize之后送入网络中,输出特征,然后利用SVM进行类别判断并产生相应的分数,因为候选框有2000个,所以必然有很多的框是重叠的,因此针对每一个类别,需要计算IoU,采用非极大值抑制(NMS),剔除部分重叠区域。
(4)回归
定位框回归,输入的是第五个池化层输出的特征图,人工标注的框,然后进行训练,将特征图的框去拟合真实的框














 7711
7711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









