









单链表
邻接表用的多 存储树和图 new()速度慢 数组模拟
模板
0代表头节点
const int N = 100010;
// 0表示头节点 使得所有节点操作一致 不用考虑是否为头节点或尾结点
// ne[0] 表示第一个节点
int e[N], ne[N], idx = 1;
void insert(int k, int x)
{
// 当前元素赋值为x
e[idx] = x;
// 当前元素的后继是第k个元素的后继
ne[idx] = ne[k];
// 第k个元素的后继是当前元素
ne[k] = idx++;
}
void remove(int k, int x)
{
// 第k个元素的后继赋值为第k个元素后继的后继
ne[k] = ne[ne[k]];
}
单链表
代码
0代表头节点
即使是一个字符 也建议用数组来存 忽略空格换行的影响
#include<iostream>
using namespace std;
const int N = 100010;
// 0表示头节点 使得所有节点操作一致 不用考虑是否为头节点或尾结点
// ne[0] 表示第一个节点
int e[N], ne[N], idx = 1;
void insert(int k, int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
void remove(int k)
{
ne[k] = ne[ne[k]];
}
int main()
{
int m;
scanf("%d", &m);
//即使是一个字符 也建议用数组来存 忽略空格换行的影响
char op[2];
int k, x;
while (m--)
{
scanf("%s", op);
if (op[0] == 'H')
{
scanf("%d", &x);
insert(0, x);
}
else if (op[0] == 'D')
{
scanf("%d", &k);
remove(k);
}
else
{
scanf("%d%d", &k, &x);
insert(k, x);
}
}
for (int i = ne[0]; i != 0; i = ne[i]) printf("%d ", e[i]);
return 0;
}
双链表
模板
const int N = 100010;
int e[N], l[N], r[N], idx;
// 初始化 0头节点 1尾节点
void init()
{
r[0] = 1, l[1] = 0, idx = 2;
}
// 在第k个元素后插入一个元素
void insert(int k, int x)
{
e[idx] = x;
// 插入元素的前驱是第k个元素
l[idx] = k;
// 插入元素的后继是第k个元素的后继
r[idx] = r[k];
// 第k个元素的后继的前驱是当前插入的元素
l[r[k]] = idx;
// 第k个元素的后继是当前插入的元素
r[k] = idx++;
}
// 删除第k个元素
void remove(int k)
{
// 第k个元素的前驱的后继是第k个元素的后继
r[l[k]] = r[k];
// 第k个元素的后继的前驱是第k个元素的前驱
l[r[k]] = l[k];
}
双链表

- 之所以在 “D”, “IL”, “IR” 要用 k+1 的原因是 双链表的起始点是2,而不是1. 所以,每个插入位置k的真实位置应该为 k-1+2 = k+1。
- 0, 1 节点的作用是边界。0为左边界,1为右边界。他俩在这里有点类似保留字的作用。正因如此,我们的idx也是从2开始
- 最后遍历输出结果的
for (int i = r[0]; i != 1; i = r[i])。从r[0]开始是因为 0 为左边界,而终止条件 i==1是因为1为右边界(如果碰到,说明已经遍历完毕)
代码
#include <iostream>
using namespace std;
const int N = 100005;
int l[N], r[N], e[N], idx;
void insert(int k, int x)
{
e[idx] = x;
// 插入元素的前驱是第k个元素
l[idx] = k;
// 插入元素的后继是第k个元素的后继
r[idx] = r[k];
// 第k个元素的后继的前驱是当前插入的元素
l[r[k]] = idx;
// 第k个元素的后继是当前插入的元素
r[k] = idx++;
}
void remove(int k)
{
// 第k个元素的前驱的后继是第k个元素的后继
r[l[k]] = r[k];
// 第k个元素的后继的前驱是第k个元素的前驱
l[r[k]] = l[k];
}
int main()
{
int m;
cin >> m;
// 0为头节点,1为头尾节点
l[1] = 0, r[0] = 1, idx = 2;
while (m--)
{
string op;
int k, x;
cin >> op;
if (op[0] == 'L')
{
cin >> x;
insert(0, x);
}
else if (op[0] == 'R')
{
cin >> x;
insert(l[1], x);
}
else if (op[0] == 'D')
{
cin >> k;
// idx不是从1开始的,从2开始的,所以要加1
remove(k + 1);
}
else if (op == "IL")
{
cin >> k >> x;
insert(l[k + 1], x);
}
else
{
cin >> k >> x;
insert(k + 1, x);
}
}
for (int i = r[0]; i != 1; i = r[i]) printf("%d ", e[i]);
return 0;
}
栈
模板
// tt表示栈顶
int stk[N], tt = 0;
// 向栈顶插入一个数
stk[ ++ tt] = x;
// 从栈顶弹出一个数
tt -- ;
// 栈顶的值
stk[tt];
// 判断栈是否为空
if (tt > 0) not empty
{
}
模拟栈

代码
#include<iostream>
using namespace std;
const int N = 100010;
int top, stk[N];
int main()
{
string op;
int m, x;
cin >> m;
while (m--)
{
cin >> op;
if (op == "push") cin >> x, stk[++top] = x;
else if (op == "pop") top--;
else if (op == "empty") cout << (top > 0 ? "NO" : "YES") << endl;
else cout << stk[top] << endl;
}
return 0;
}
表达式求值
思路:
- 对于不同的运算操作,有不同的优先级,首先预处理 不同运算符的优先级,加法减法的小于乘法和除法的,可以用哈希表进行存储。
- 接着遍历字符串,如果是数字,则依次遍历下去,把一串数字当作一个十进制数存到操作数栈中,这里用到了双指针。
- 如果当前字符是 ‘(’,则存入运算符栈中,如果是 ‘)’,则计算一对括号内的元素,通过
eval()函数实现计算功能,接着把 ‘(’ 弹出栈。 - 如果当前字符是其他的运算符,则按照四则运算的优先级进行计算,此时要判断栈是否为空,运算符栈顶的优先级是否大于当前运算符的优先级:如果是,则进行计算,否则当前运算符入栈。
- 如果最后运算符栈不为空,则继续进行计算,最后操作数中只剩下一个数,也就是表达式的结果。
代码
#include <iostream>
#include <cstring>
#include <stack>
#include <unordered_map>
using namespace std;
stack<int> nums;
stack<char> ops;
void eval()
{
int b = nums.top(); nums.pop();
int a = nums.top(); nums.pop();
char op = ops.top(); ops.pop();
int x;
if (op == '+') x = a + b;
else if (op == '-') x = a - b;
else if (op == '*') x = a * b;
else x = a / b;
nums.push(x);
}
int main()
{
string str;
cin >> str;
unordered_map<char, int> pr{{'+', 1}, {'-', 1}, {'*', 2}, {'/', 2}};
for (int i = 0; i < str.size(); i++)
{
char c = str[i];
if (isdigit(c))
{
int x = 0, j = i;
while (j < str.size() && isdigit(str[j]))
x = x * 10 + str[j++] - '0';
i = j - 1;
nums.push(x);
}
else if (c == '(') ops.push(c);
else if (c == ')')
{
while (ops.top() != '(') eval();
ops.pop();
}
else
{
while (ops.size() && ops.top() != '(' && pr[ops.top()] >= pr[c]) eval();
ops.push(c);
}
}
while (ops.size()) eval();
cout << nums.top() << endl;
return 0;
}
队列
普通队列
// hh 表示队头,tt表示队尾
int q[N], hh = 0, tt = -1;
// 向队尾插入一个数
q[ ++ tt] = x;
// 从队头弹出一个数
hh ++ ;
// 队头的值
q[hh];
// 判断队列是否为空
if (hh <= tt) not empty
{
}
模拟队列

#include<iostream>
using namespace std;
const int N = 100010;
int hh, tt = -1, q[N];
int main()
{
int m, x;
string op;
cin >> m;
while (m--)
{
cin >> op;
if (op == "push") cin >> x, q[++tt] = x;
else if (op == "pop") hh++;
else if (op == "empty") cout << (hh <= tt ? "NO" : "YES") << endl;
else cout << q[hh] << endl;
}
return 0;
}
单调栈
模板
常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
单调栈

思路:
用一个栈来维护某一元素前面的元素,如果栈顶元素不小于当前元素,不断出栈。结束这个操作后如果栈非空,则栈顶元素就是当前元素左边第一个小于它的元素,否则就找不到。最后把当前元素入栈。
#include<iostream>
using namespace std;
const int N = 100010;
int top, stk[N], n, a[N];
int main()
{
cin >> n;
for (int i = 0; i < n; i++) cin >> a[i];
for (int i = 0; i < n; i++)
{
// 栈不空的前提下如果栈顶元素不小于当前元素,出栈
while (top && stk[top] >= a[i]) top--;
// 不空,则找到了答案
if (top) cout << stk[top] << ' ';
// 空则没有找到
else cout << -1 << ' ';
// 当前元素入栈
stk[++top] = a[i];
}
return 0;
}
单调队列
模板
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
154.滑动窗口
#include<iostream>
using namespace std;
const int N = 1000010;
int a[N], q[N], n, k;
int main()
{
scanf("%d%d", &n, &k);
for (int i = 0; i < n; i++) scanf("%d", &a[i]);
int hh = 0, tt = -1;
for (int i = 0; i < n; i++)
{
// 判断队头是否滑出窗口, 队列存储下标
if (hh <= tt && i - k + 1 > q[hh]) hh++;
// 比当前元素大的时候 往前遍历
while (hh <= tt && a[q[tt]] >= a[i]) tt--;
// 在队尾加入当前元素
q[++tt] = i;
// 第k个数及以后才输出,队头存储的就是所求元素的下标
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
printf("\n");
hh = 0, tt = -1;
for (int i = 0; i < n; i++)
{
// 判断队头是否滑出窗口, 队列存储下标
if (hh <= tt && i - k + 1 > q[hh]) hh++;
// 比当前元素小的时候 往前遍历
while (hh <= tt && a[q[tt]] <= a[i]) tt--;
// 在队尾加入当前元素
q[++tt] = i;
// 第k个数及以后才输出
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
return 0;
}
Trie树
高效地存储和查找字符串集合的数据结构,适用于字符串不太复杂的情况。其形状是一个以0为根节点的树,查询和插入的效率都比较高,有插入和查询两种操作。Trie树通常用一个二维数组来存储,第一维表示节点的数量,第二维表示节点的状态数。
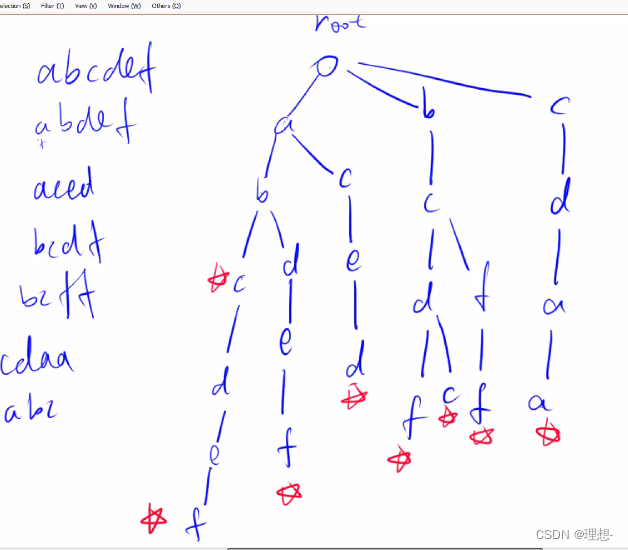
Trie字符串统计

代码:
#include <iostream>
using namespace std;
const int N = 100005;
// son存储trie树,以0为根节点的树,cnt存储字符串个数
int son[N][26], cnt[N], idx;
char str[N];
void insert(char* str)
{
// 祖宗节点
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a';
// 子节点不存在就创建
if (!son[p][u]) son[p][u] = ++idx;
// 往下遍历trie树
p = son[p][u];
}
// 该字符串个数加一
cnt[p]++;
}
int query(char* str)
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - 'a';
// 子节点不存在表示不包含当前字符串,返回0
if (!son[p][u]) return 0;
// 往下遍历trie树
p = son[p][u];
}
// 返回字符串个数
return cnt[p];
}
int main()
{
int n;
cin >> n;
while (n--)
{
char op[2];
scanf("%s%s", op, str);
if (op[0] == 'I') insert(str);
else printf("%d\n", query(str));
}
return 0;
}
最大异或对

思路:
把每一个整数看作一个二进制数来处理,按照字符串的形式插入到trie树中。要求找到一个异或后尽可能大的树,则要尽量使参与异或运算的两个数对应的位一个为0一个为1。在查询的过程中查找对应位不一样的数,如果有,则选择对应位不一样的数,否则选择对应位一样的数。
代码
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010, M = 31 * N;
int a[N], son[M][2];
int n, idx;
void insert(int x)
{
int p = 0; //
for (int i = 31; i >= 0; i--)
{
int u = x >> i & 1; // 取二进制数的某一位的值
if (!son[p][u]) son[p][u] = ++idx; // 如果下标为p的点的u(0或1)这个儿子不存在,那就创建
p = son[p][u];
}
}
int query(int x)
{
int p = 0, ret = 0;
for (int i = 31; i >= 0; i--)
{
int u = x >> i & 1;
// 找对应位不一样的数,如果有则继续查找
if (son[p][!u])
{
p = son[p][!u];
ret = ret * 2 + !u;
}
// 退而求其次
else
{
p = son[p][u];
ret = ret * 2 + u;
}
}
return ret;
}
int main()
{
cin >> n;
int res = 0;
for (int i = 0; i < n; i++)
{
scanf("%d", &a[i]);
insert(a[i]);
int t = query(a[i]);
res = max(res, t ^ a[i]);
}
cout << res << endl;
return 0;
}
并查集
并查集可以快速判断两个元素是否在同一个集合内,并查集支持两种操作:
- 查询,查询元素的祖先节点,这里用到了路径压缩算法
- 合并,合并两个元素到一个集合中,把一个元素的祖先的父节点赋值为另一个元素的祖先
合并集合
代码:
#include <iostream>
using namespace std;
const int N = 100005;
int p[N];
int n, m;
// 查询祖宗节点
int find(int x)
{
// 路径压缩
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 合并集合
void merge(int a, int b)
{
// 同一个祖先 不需要合并
if (find(a) == find(b)) return;
// a的祖先的父亲是b的祖先 操作可以互换
p[find(a)] = find(b);
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化并查集
for (int i = 1; i <= n; i++) p[i] = i;
while (m--)
{
char op[2];
int a, b;
scanf("%s%d%d", op, &a, &b);
if (op[0] == 'M') merge(a, b);
else cout << (find(a) == find(b) ? "Yes" : "No") << endl;
}
}
连通块中点的数量

思路:
需要单独维护一个数组用来存储集合元素个数。在合并集合中,如果两个元素不在一个集合内,就把元素个数相加。
#include <iostream>
using namespace std;
const int N = 100005;
int p[N], cnt[N];
int n, m;
// 查询祖宗节点
int find(int x)
{
// 路径压缩
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 合并集合
void merge(int a, int b)
{
// 同一个祖先 不需要合并
if (find(a) == find(b)) return;
// a的祖先的祖先是b的祖先 操作可以互换
cnt[find(b)] += cnt[find(a)];
p[find(a)] = find(b);
}
int main()
{
scanf("%d%d", &n, &m);
// 初始化并查集
for (int i = 1; i <= n; i++) p[i] = i, cnt[i] = 1;
while (m--)
{
char op[5];
int a, b;
scanf("%s", op);
if (op[0] == 'C')
{
scanf("%d%d", &a, &b);
merge(a, b);
}
else if (op[1] == '1')
{
scanf("%d%d", &a, &b);
printf(find(a) == find(b) ? "Yes\n" : "No\n");
}
else
{
scanf("%d", &a);
printf("%d\n", cnt[find(a)]);
}
}
return 0;
}
堆
基本概念:一棵完全二叉树
- 小根堆
- 大根堆
基本操作
- 插入一个数
- 求集合中的最小值
- 删除最小值
- 删除任意一个元素
- 修改任意一个元素

模板
// h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1
// ph[k]存储第k个插入的点在堆中的位置
// hp[k]存储堆中下标是k的点是第几个插入的
void heap_swap(int a, int b)
{
swap(ph[hp[a]], ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
// 向下调整,大的元素放下面
void down(int i)
{
int t = i;
// i与左右节点最小值交换 (如果存在的话)
if (i * 2 <= len && h[i * 2] < h[t]) t = i * 2;
if (i * 2 + 1 <= len && h[i * 2 + 1] < h[t]) t = i * 2 + 1;
if (i != t)
{
heap_swap(i, t);
down(t);
}
}
//向上调整,小的元素放上面
void up(int i)
{
while (i / 2 && h[i] < h[i / 2])
{
heap_swap(i, i / 2);
i /= 2;
}
}
// 初始化堆 O(n)的复杂度
for (int i = n / 2; i; i--) down(i);
堆排序

#include<iostream>
using namespace std;
const int N = 100010;
int h[N], n, m, len;
void down(int i)
{
int t = i;
// i与左右节点最小值交换 (如果存在的话)
if (i * 2 <= len && h[i * 2] < h[t]) t = i * 2;
if (i * 2 + 1 <= len && h[i * 2 + 1] < h[t]) t = i * 2 + 1;
if (i != t)
{
swap(h[i], h[t]);
down(t);
}
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) scanf("%d", &h[i]);
len = n;
// 初始化堆 O(n)的复杂度
for (int i = n / 2; i; i--) down(i);
while (m--)
{
printf("%d ", h[1]);
h[1] = h[len];
len--;
down(1);
}
return 0;
}
模拟堆

思路:
本题的堆为小根堆,有以下五种操作:
-
插入一个数,修改堆的大小
len++,在堆的末尾增加一个数h[len] = x,再往上调整up(len) -
输出堆的最小值,
h[1] -
删除当前集合最小值,把最小值与末尾互换,修改堆的小,再从1开始向下调整
-
删除第k个插入的数,注意是第k个插入的数,而不是堆中的第k个数,依次需要用额外的数据结构存储第k个插入的数的信息:
ph[k]存储第k个插入的点在堆中的下标hp[k]存储堆中下标是k的点是第几个插入的
k = ph[k]获取第k个插入的点在堆中的下标,删除之后要对堆进行调整,由于不知道第k个插入的数的大小关系,不知道要向下还是向上调整,所以调整的时候可以先向下调整,再向上调整,但这两步操作最终只有一个操作执行。 -
修改第k个插入的数,获取第k个插入的数的下标,将当前的点修改,再进行上下调整即可。
#include <iostream>
using namespace std;
const int N = 100005;
// h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1
// ph[k]存储第k个插入的点在堆中的下标
// hp[k]存储堆中下标是k的点是第几个插入的
// len表示堆的大小
// m表示当前元素是第几个插入的
int h[N], hp[N], ph[N], len, m;
void heap_swap(int a, int b)
{
swap(ph[hp[a]], ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
// 向下调整
void down(int i)
{
int t = i;
if (2 * i <= len && h[2 * i] < h[t]) t = 2 * i;
if (2 * i + 1 <= len && h[2 * i + 1] < h[t]) t = 2 * i + 1;
if (t != i)
{
heap_swap(i, t);
down(t);
}
}
// 向上调整
void up(int i)
{
while (i / 2 && h[i] < h[i / 2])
{
heap_swap(i, i / 2);
i /= 2;
}
}
int main()
{
int n, k, x;
string op;
cin >> n;
while (n--)
{
cin >> op;
if (op == "I")
{
cin >> x;
len++;
m++;
ph[m] = len, hp[len] = m;
h[len] = x;
up(len);
}
else if (op == "PM") cout << h[1] << endl;
else if (op == "DM")
{
heap_swap(1, len);
len--;
down(1);
}
else if (op == "D")
{
cin >> k;
// 获取第k个插入元素的下标
k = ph[k];
heap_swap(k, len);
len--;
down(k), up(k);
}
else
{
cin >> k >> x;
// 获取第k个插入元素的下标
k = ph[k];
h[k] = x;
down(k), up(k);
}
}
return 0;
}
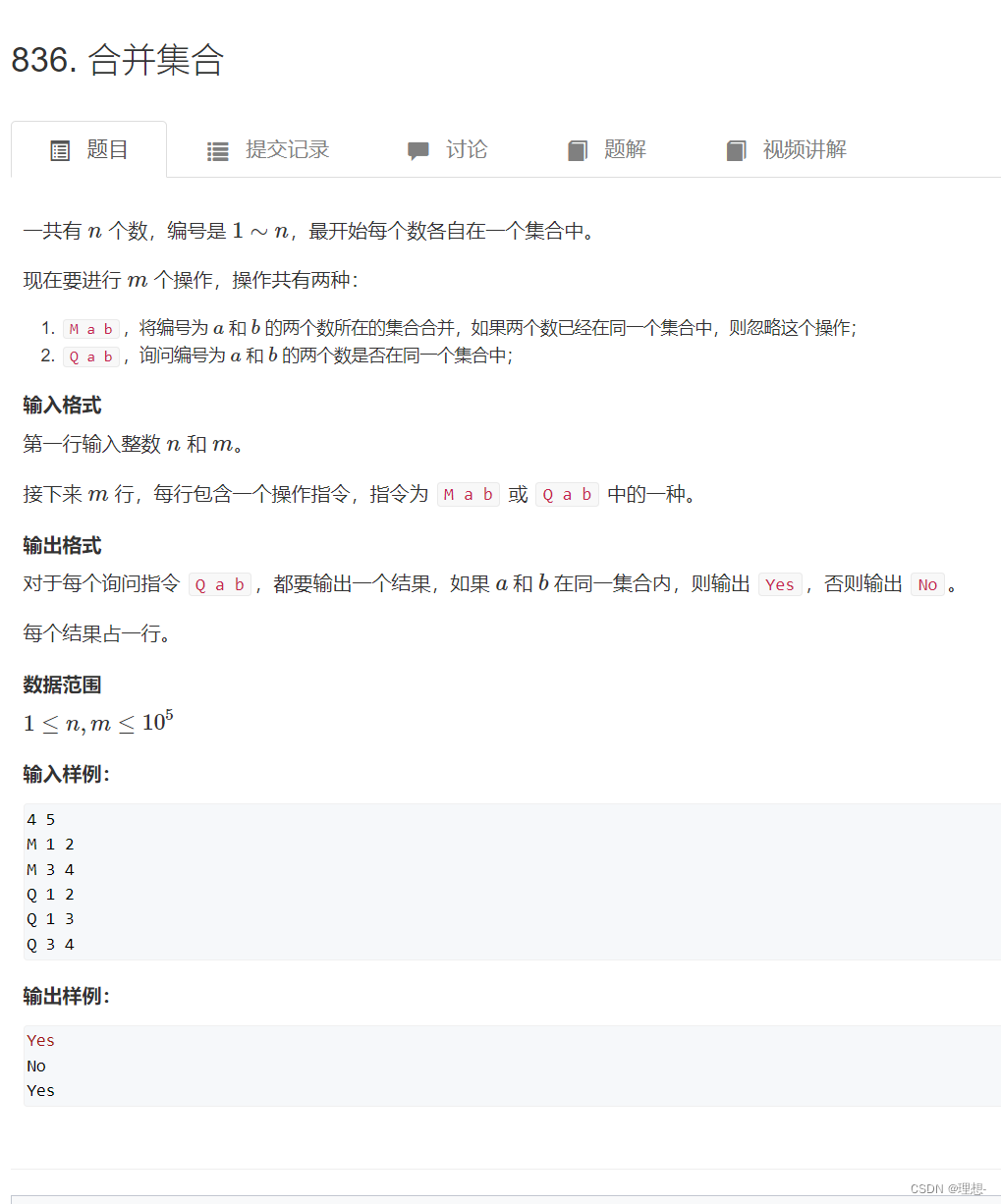
Hash表
模板
//(1) 拉链法 邻接表
// h[]存储头指针 初始化为-1,e[]存储节点的值,ne[]存储下一个元素的指针
int h[N], e[N], ne[N], idx;
// 向哈希表中插入一个数
void insert(int x)
{
// 这样写是防止x是负数
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
// 在哈希表中查询某个数是否存在
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
//(2) 开放寻址法
int h[N];
// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x)
{
t ++ ;
if (t == N) t = 0;
}
return t;
}
模拟散列表

拉链法
#include<iostream>
#include <cstring>
using namespace std;
const int N = 100003;
int h[N], e[N], ne[N], idx;
int n;
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx++;
}
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x) return true;
return false;
}
int main()
{
scanf("%d", &n);
memset(h, -1, sizeof h);
char op[2];
int x;
while (n--)
{
scanf("%s%d", op, &x);
if (op[0] == 'I') insert(x);
else printf(find(x) ? "Yes\n" : "No\n");
}
return 0;
}
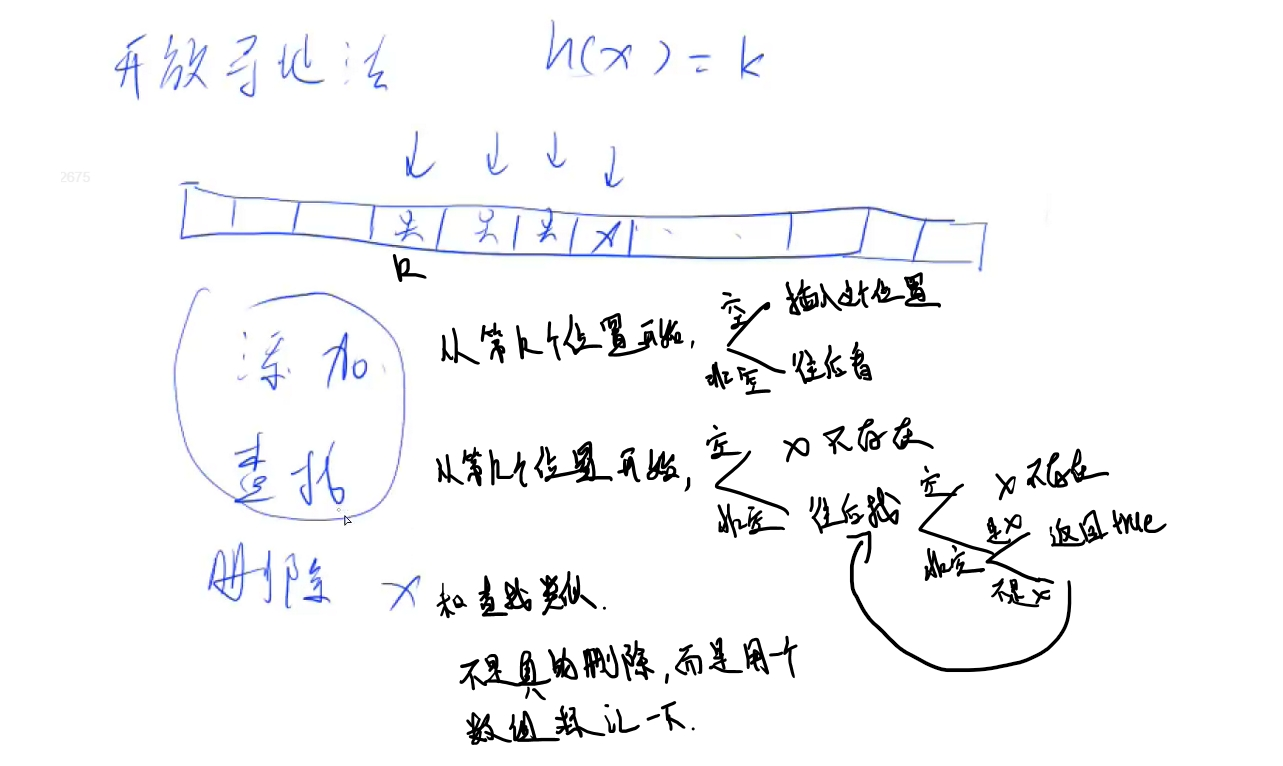
开放寻址法,范围2~3倍
#include<iostream>
#include <cstring>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f; // 范围2~3倍 质数
int h[N];
int n;
// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置
int find(int x)
{
int k = (x % N + N) % N;
while (h[k] != null && h[k] != x)
{
k++;
if (k == N) k = 0;
}
return k;
}
int main()
{
scanf("%d", &n);
// memset 按字节赋值 后八位
memset(h, 0x3f, sizeof h);
char op[2];
int x;
while (n--)
{
scanf("%s%d", op, &x);
int k = find(x);
if (op[0] == 'I') h[k] = x;
else printf(h[k] != null ? "Yes\n" : "No\n");
}
return 0;
}
字符串哈希
核心思想: 将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧: 取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
注意: 字符串从1的位置开始存。前
l
l
l 位字符串的哈希值是
h
[
l
]
h[l]
h[l],前
r
r
r 位字符串的哈希值是
h
[
r
]
h[r]
h[r],则
l
∼
r
l \sim r
l∼r 之间字符串(包含端点)的哈希值可以表示为:
h
[
l
∼
r
]
=
h
[
1
∼
r
]
−
h
[
1
∼
l
−
1
]
∗
P
r
−
l
+
1
\begin{aligned} h[l \sim r] &= h[1 \sim r] - h[1 \sim l - 1] * P ^{r - l + 1} \end{aligned}
h[l∼r]=h[1∼r]−h[1∼l−1]∗Pr−l+1


模板
typedef unsigned long long ull;
ull h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ull get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
代码
#include<iostream>
using namespace std;
typedef unsigned long long ull;
const int N = 100005, P = 131;
ull h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
char str[N];
int n, m;
// 计算子串 str[l ~ r] 的哈希值
ull get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%d%d%s", &n, &m, str + 1);
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
while (m--)
{
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
if (get(l1, r1) == get(l2, r2)) cout << "Yes" << endl;
else cout << "No" << endl;
}
return 0;
}















 2158
2158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









