









前言:
本次仅仅是作为一次记录,自从去年使用过香橙派5做了一次数字识别之后,就把它告一段落了,结果在今年做了一个人脸识别的项目的时候,又出现了新的错误,而且伴随着RKNN官方文档的更新,也出现了一些之前没有的错误,这里记录一下,以防后续再次使用的时候,出现问题。
这里就不再从模型训练开始了,直接从.pt文件向onnx文件转换开始。(我的.pt文件直接在云服务器上生成的)
环境准备:
香橙派5:官方的Ubutnu_gnome系统20.04
PC端:采用Ubuntu20.04
正文开始:
将.pt转为.onnx文件
首先将训练好的.pt文件转化为onnx文件
在export.py文件下做如下修改:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
if os.getenv('RKNN_model_hack', '0') != '0':
z.append(torch.sigmoid(self.m[i](x[i])))
continue
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if os.getenv('RKNN_model_hack', '0') != '0':
return z
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)修改为:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x并且将我们生成的.pt文件放在与export文件同一文件目录下
此外,修改第838行的'--opset'的defaut为12,否则后续转rknn文件的时候就会报错
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')而且,我在运行export.py的时候又出了一些错误,经过多方面查证发现需要修改export.py文件的760行的代码,
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape修改为
shape = tuple(y[0].shape)在终端输入
python export.py --weights best.pt --img 640 --batch 1 --include onnx会生成一个.onnx文件在咱们的同级文件夹下。此时并没有像上次那样出现RKNN.anchor文件,就在我以为接下来如果识别会出现超级多的框,但是没有!!!
将.onnx文件转为.rknn文件
这一步需要在装有Ubuntu的PC端完成,首先我去最新的rknn官方文档下载了rknn-toolkit2-master,链接如下:https://github.com/airockchip/rknn-toolkit2
注意,这里千万不能下载成rknn-toolkit!!!,这两个不是一回事!!!
使用conda创建虚拟环境rknn2.0,
conda create -n rknn2.0 python=3.8创建完成后,进入虚拟环境
conda activate rknn2.0进入我们刚才下载好的rknn-toolkit2-master下的rknn-toolkit2,进入packages
cd rknn-toolkit2-master/rknn-toolkit2/packages/下载依赖项
pip install -r requirements_cp38-2.0.0b0.txt -i https://mirror.baidu.com/pypi/simple
之后,再安装对应版本的.whl文件
pip install rknn_toolkit2-2.0.0b0+9bab5682-cp38-cp38-linux_x86_64.whl安装完成后,在终端输入python,输入
from rknn.api import RKNN
如果不出错的话,那么就可以了
接下来,进入 rknn-toolkit2-master/rknn-toolkit2/examples/onnx/yolov5/ 修改test.py以便于生成.rknn文件
ONNX_MODEL = '你自己生成的.onnx'
RKNN_MODEL = '你自己命名的.rknn'
IMG_PATH = './你用来测试的照片.jpg'
CLASSES = ("你自己定义的类别")
然后在CLASSES后面添加
def sigmoid(x):
return 1 / (1 + np.exp(-x))然后将process函数修改为
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs修改完之后,就可以运行了
python test.py
之后会在我们的文档里生成一个.rknn文件,然后在这个文件夹下还是会生成一张带着3到4个框的照片,这里生成的照片并不是非常多的框,如果只是出现了3到4个框,说明这个.rknn文件没问题。这种也是一个正常现象。
香橙派5部署rknn-toolkit-lite2环境
这里一定要注意!!!,我在香橙派5上面部署的rknn-toolikt2.0-beta0(最新版)最终报了一堆错误,哪怕时至今日,我也没有解决,但是我部署rknn-toolkit2-1.4,却跑通了!!!
我这里记录一下成功的做法吧,我也不知道为啥用最新版的却出错了。
在香橙派5上下载1.4版本的rknn-toolkit2
(或者可以从刚才的github仓库那边找到commit,找到1.4版本,点击一下browse file)
香橙派5安装miniconda
如果是刚装的系统,那么香橙派5是没有conda的,所以必须先去下载一个miniconda,我是直接在清华大学镜像网上下载的miniconda
在下载之前,先要找到自己合适的版本,用下面的指令查看一下内核版本和处理器信息
uname -a然后选择版本安装即可,我这里安装的是Miniconda3-py39_24.1.2-0-Linux-aarch64.sh,安装完成后,使用下面的命令运行一下就可以进入安装过程了。
sh Miniconda3-py39_24.1.2-0-Linux-aarch64.sh一直按住键盘上的下箭头 ,直到出现下面所示的界面,选择yes
Please answer 'yes' or 'no':'
>>> yes
-- 填入yes
然后这里是选择安装路径,直接点击回车就好
Miniconda3 will now be installed into this location:
/root/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/miniconda3] >>>
此时会提示是否默认进入终端就进入conda虚拟环境,yes就是默认进入就是(base)环境
Preparing transaction: done
Executing transaction: done
installation finished.
Do you wish to update your shell profile to automatically initialize conda?
This will activate conda on startup and change the command prompt when activated.
If you'd prefer that conda's base environment not be activated on startup,
run the following command when conda is activated:
conda config --set auto_activate_base false
You can undo this by running `conda init --reverse $SHELL`? [yes|no]
[no] >>> yes
安装完成之后,重启皆可,输入conda -V查看是否能用。
然后创建虚拟环境rknn1.4,配置一下板端的环境
conda create -n rknn1.4 python=3.9这里一定要设置为3.9或者3.7因为在rknn-toolkit-lite2下安装.whl文件都是3.9或者3.7版本的,没有3.8版本的了。之前还有,现在没有了,应该是官方更新了。
安装完之后,进入example/onnx/yolov5文件夹下,新建demo.py
import os
import urllib
import traceback
import time
import datetime as dt
import sys
import numpy as np
import cv2
from rknnlite.api import RKNNLite
#RKNN_MODEL = 'yolov5s-640-640.rknn'
RKNN_MODEL = 'new_face.rknn'
#DATASET = './dataset.txt'
QUANTIZE_ON = True
OBJ_THRESH = 0.25
NMS_THRESH = 0.45
IMG_SIZE = 640
'''CLASSES = ("person", "bicycle", "car", "motorbike ", "aeroplane ", "bus ", "train", "truck ", "boat", "traffic light",
"fire hydrant", "stop sign ", "parking meter", "bench", "bird", "cat", "dog ", "horse ", "sheep", "cow", "elephant",
"bear", "zebra ", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite",
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife ",
"spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza ", "donut", "cake", "chair", "sofa",
"pottedplant", "bed", "diningtable", "toilet ", "tvmonitor", "laptop ", "mouse ", "remote ", "keyboard ", "cell phone", "microwave ",
"oven ", "toaster", "sink", "refrigerator ", "book", "clock", "vase", "scissors ", "teddy bear ", "hair drier", "toothbrush ")
'''
CLASSES = ("sqy","smy","sms","rs","zyf","qft","sq")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[199, 371], [223, 481], [263, 428], [278, 516], [320, 539], [323, 464], [361, 563], [402, 505], [441, 584]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes, fps):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
fps: int.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
# ==================================
# 如下为改动部分,主要就是去掉了官方 demo 中的模型转换代码,直接加载 rknn 模型,并将 RKNN 类换成了 rknn_toolkit2_lite 中的 RKNNLite 类
# ==================================
rknn = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = rknn.load_rknn(RKNN_MODEL)
# Init runtime environment
print('--> Init runtime environment')
# use NPU core 0 1 2
ret = rknn.init_runtime(core_mask=RKNNLite.NPU_CORE_0_1_2)
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Create a VideoCapture object and read from input file
# If the input is the camera, pass 0 instead of the video file name
cap = cv2.VideoCapture(0)
# Check if camera opened successfully
if (cap.isOpened()== False):
print("Error opening video stream or file")
# Read until video is completed
while(cap.isOpened()):
start = dt.datetime.utcnow()
# Capture frame-by-frame
ret, img = cap.read()
if not ret:
break
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
img = np.expand_dims(img,0)
# Inference
#print('--> Running model')
outputs = rknn.inference(inputs=[img])
#print('done')
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
duration = dt.datetime.utcnow() - start
fps = round(1000000 / duration.microseconds)
# draw process result and fps
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
cv2.putText(img_1, f'fps: {fps}',
(20, 20),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 125, 125), 2)
if boxes is not None:
draw(img_1, boxes, scores, classes, fps)
# show output
cv2.imshow("post process result", img_1)
# Press Q on keyboard to exit
if cv2.waitKey(25) & 0xFF == ord('q'):
break
# When everything done, release the video capture object
cap.release()
# Closes all the frames
cv2.destroyAllWindows()
在这里呢,我已经实现了实时视频,大家如果要用的,适当修改即可
新的坑
原来不会出错的地方,现在出错了,可能是官方更新之后,出现的问题
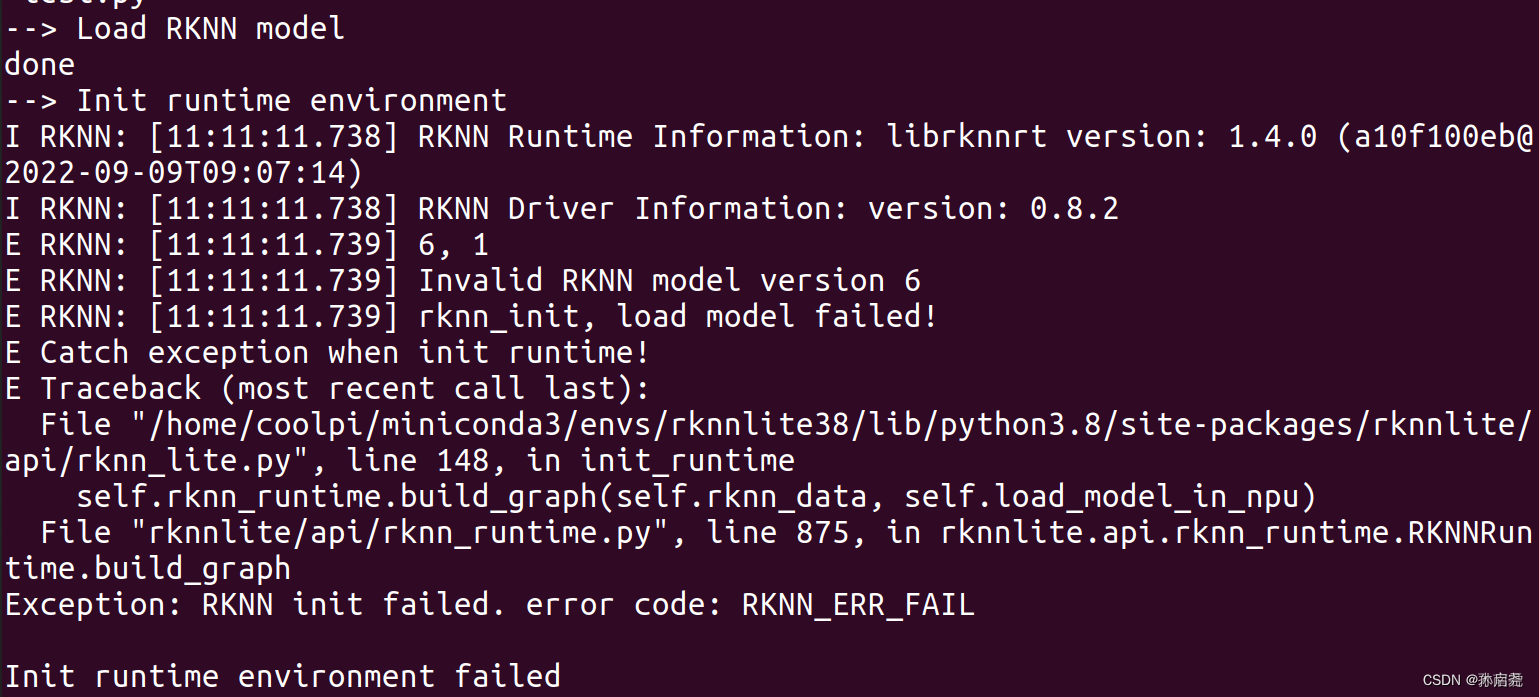
这时候,我参考大佬的文章传送门知道,需要用RKNPU来解决这个问题
下载RKNPU![]() https://github.com/rockchip-linux/rknpu2
https://github.com/rockchip-linux/rknpu2
执行如下命令
sudo cp rknpu2-master/runtime/RK3588/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/librknnrt.so
再次运行,即可















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









