







1 介绍
FCOS是一个Anchor Free模型,基于FCN的逐像素目标检测算法,实现了无提议(Proposal free)的解决方案,并且提出了中心度Center ness的思想。
2 优势
- 通过去除Anchor,完全避免了Anchor的复杂运算,节省了训练过程中大量的内存占用,将总训练内存占用空间减少了2倍左右。
- FCOS的性能优于现有的一阶段检测器
- FCOS可用作二阶段检测器Faster RCNN中的RPN,并且很大程度上都要优于RPN。
- FCOS解决了目标框重叠问题。
3 网络原理
结构图如下:
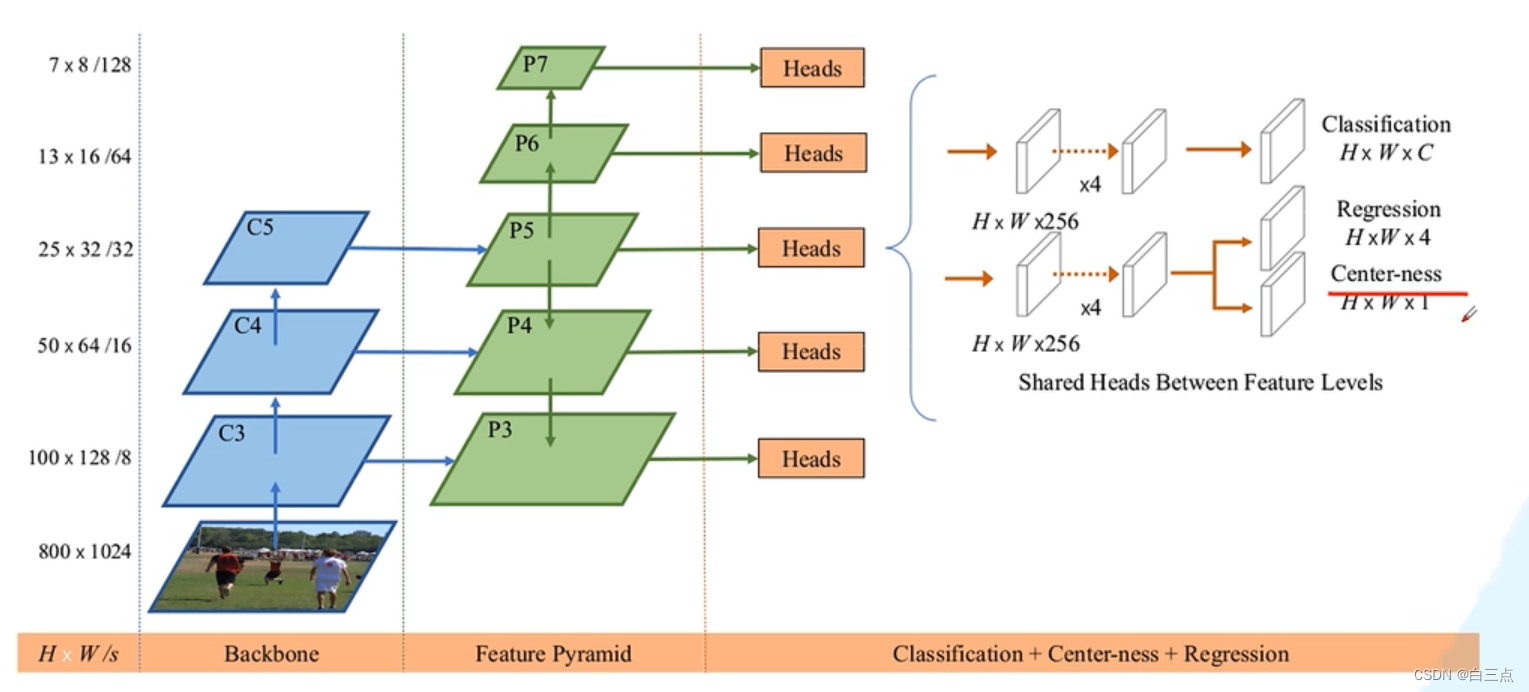
可以看到分为三部分:
- Backbone:提取特征
- Feature Pyramid:采用FPN思想,进行多尺度融合,解决目标框重叠问题。
- Classfication+Center-ness+Regression:实现相应的检测功能,具体在后面介绍
下面一个个介绍:
3.1 Backbone
这里的特征提取网络可以根据需求定义,比如RetNet,AlexNet等等…
原文图中以ResNet50为例,原图尺寸为3*800*1024。c3-c5的特征层,分辨率相当于原图的1/8、1/16和1/32。
3.2 Feature Pyramid
3.2.1 过程
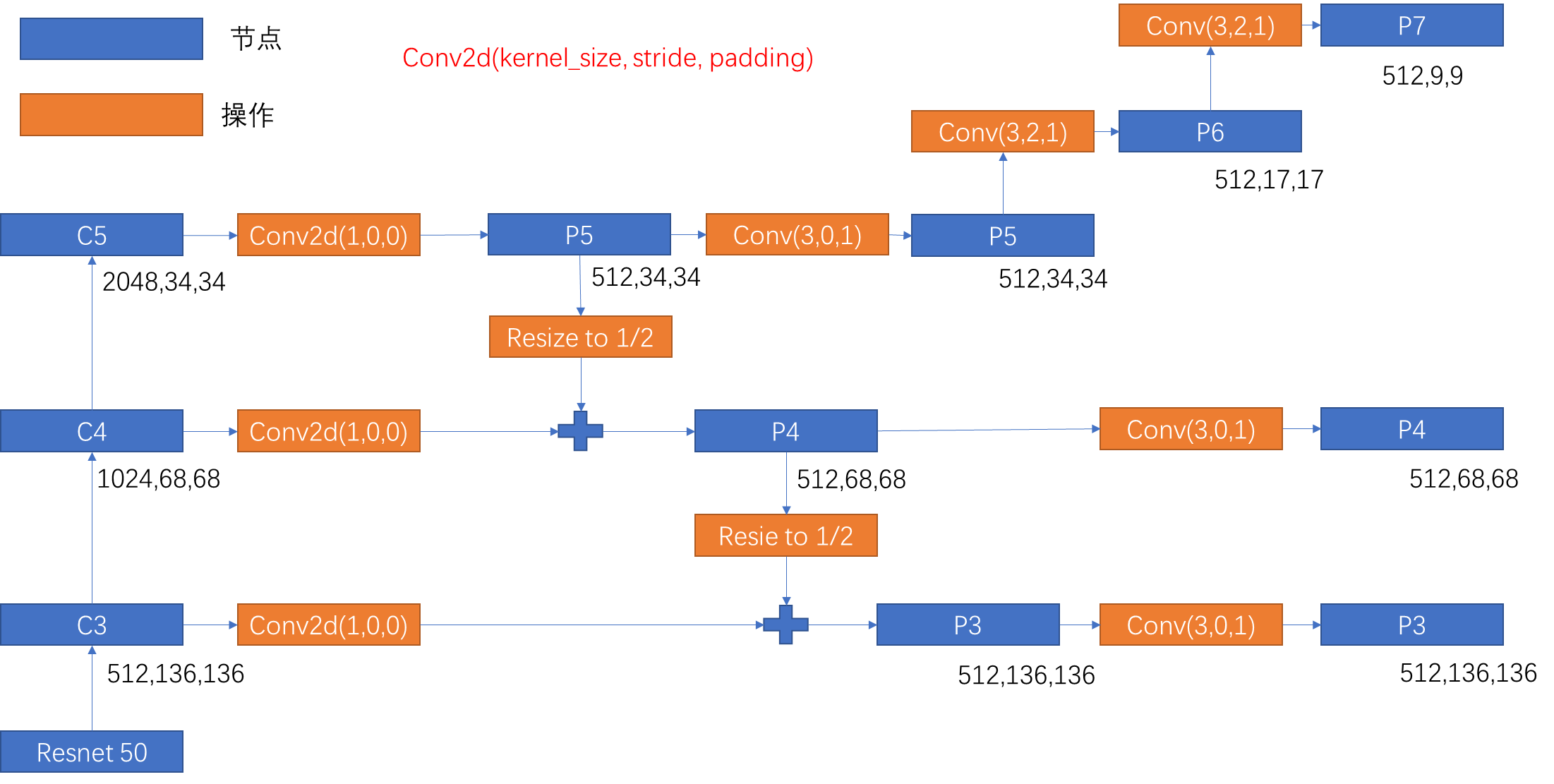
这里采用FPN的思想。根据代码来看,具体操作及变化如上图所示。最终,P3-P7每一层经过卷积操作都输出一个Headers,相当于检测头,用于后面网络实现检测功能。**所有检测头的权重是共享的,即P3到P7共用一个Head。
3.2.2 目标框重叠问题

问题描述:如图右侧,网球拍和人的中心点在同一网格内,那么该网格的类别究竟是哪一个?
传统的是一种解决办法是:遇到该情况,默认分配给体积小的,如上图的网球拍。
但是这样就无法对人进行预测,这里FCOS采用FPN结构解决了这个问题:
FPN会采用多个特征图,其中高层特征层的特征图更加关注语义信息,容易忽略小目标。而低层特征图更加关注几何信息,对大目标检测不好。因此,这里用高层特征图预测大目标,如P7预测人体,而低层特征图预测小目标,如P3预测网球拍。
该文章的正样本匹配规则也有利于目标框重叠问题的缓解,后面介绍。
3.3 Classfication+Center-ness+Regression
该部分有三个分支:
- Classification:HxWxC,在预测特征图的每个位置上都会预测C个score参数(C是类别个数)。
- Regression:HxWx4,特征图每个位置预测4个参数(l ,t, r, b),其中l是与目标左侧的距离,r是与目标右侧的距离,t是与目标上侧的距离,b是与目标下侧的距离。注意,全都是在特征图上。
- Center-ness:HxWx1,特征图每个位置预测1个参数,反映的是特征图上的某一点距离目标中心的远近程度,它的值域在0~1之间,距离目标中心越近center-ness越接近于1。
下面分别详细介绍:
3.3.1 Classification
3.3.2 Regression
HxWx4,特征图每个位置预测4个参数(l ,t, r, b),其中l是与目标左侧的距离,r是与目标右侧的距离,t是与目标上侧的距离,b是与目标下侧的距离。
这里解决两个问题:
- 测试时,使用预测得到的参数转化为原图尺度上的bbox坐标
- 训练时,训练集中利用真实的GT,得到regresion参数,用以损失的计算
这两个是逆问题,以1来总结:
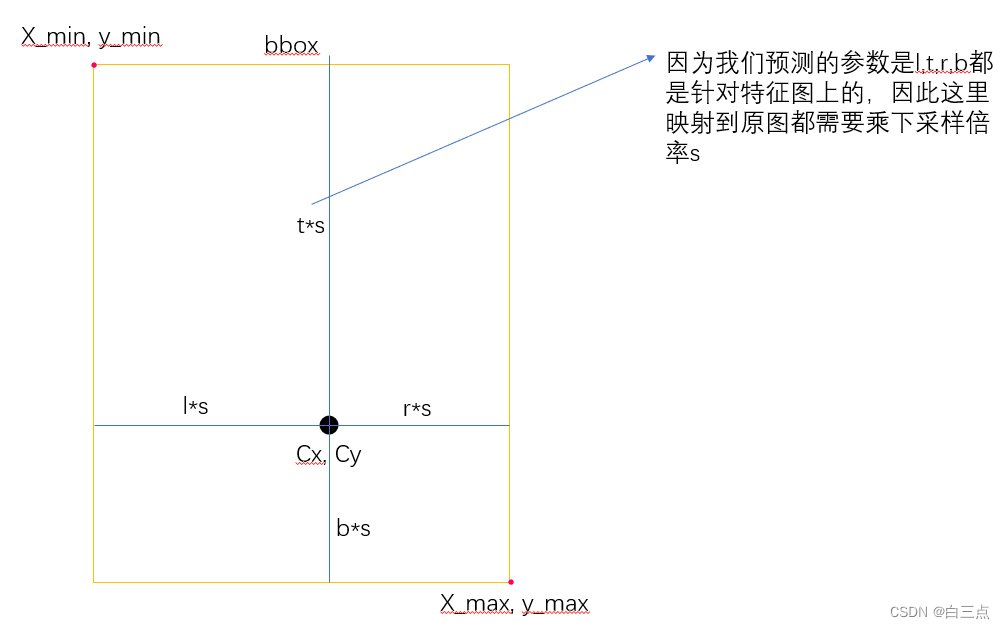
如上图所示,预测的Regression参数是(l, t, r, b),特征图相对原图下采样了s倍,特征图上某个网格点映射回原图的坐标是(Cx, Cy),这样Xmin, Xmax, Ymin,Ymax的坐标如何计算就很明显了:
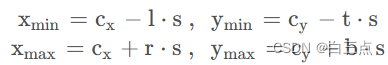
问题2就是把问题1中的公式逆着使用,得到四个regersion参数
3.3.3 Center-ness(中心度)
HxWx1,预测特征图上每个 位置都有一个参数 ,反映的是特征图上的某一点距离目标中心的远近程度,它的值域在0~1之间,距离目标中心越近center-ness越接近于1。
训练时,我们直接预测得到参数与训练集标签中的该值进行损失计算。那么训练集真实标签中的Center-ness值如何得到的呢:

假设,l*, r*, t*, b*是真实bbox坐标计算得到的regression参数(如何计算上面介绍了)。那么,我们用下面的公式来计算:
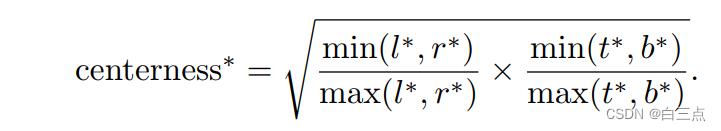
至于为何采用这个公式?
先看左右偏差部分: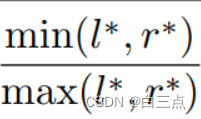
现在,假设右偏移比较小(即r*<l*),那么该公式应该表示为r*/l*。我们中心点越靠近右侧,那么r*越小,l*越大,导致该公式越小,越接近于0。越靠近中心,r*和l*越接近,越接近于1。当左偏移比较小时同理。
上下偏差部分与左右偏差是一致的,也不再多说了。
3.4 后处理
在网络后处理部分筛选高质量bbox时,会将预测的目标class score与center-ness相乘再开根,然后根据得到的结果对bbox进行排序,只保留分数较高的bbox。
这样做的目的是筛掉那些目标class score低且预测点距离目标中心较远的bbox,最终保留下来的就是高质量的bbox。
这里每个网格都有C个class score,使用最高的那个
4 损失函数
我们再了解一下损失函数,上面网络预测有三个分支:Classfication,Center-ness,Regression。因此,损失也是三部分,如下图所示:
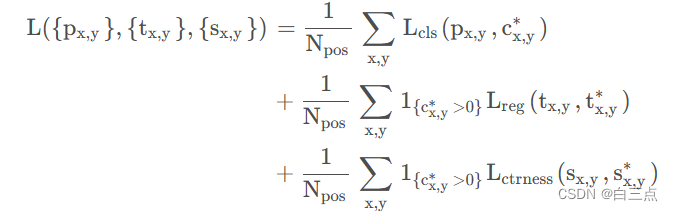
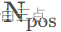 是匹配到的正样本的数量。
是匹配到的正样本的数量。
一行一部分,我们分别总结一下:
4.1 分类损失
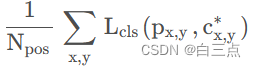
其中,分类损失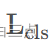 采用二值交叉熵损失配合Focal Loss,所有正样本和负样本都参与。
采用二值交叉熵损失配合Focal Loss,所有正样本和负样本都参与。
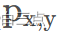 代表在特征图(x,y)点处预测的每个类别的score。
代表在特征图(x,y)点处预测的每个类别的score。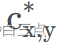 代表在特征图(x,y)点对应的真实类别标签。
代表在特征图(x,y)点对应的真实类别标签。
4.2 定位损失
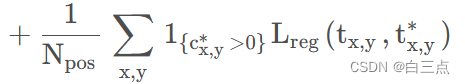
其中,定位损失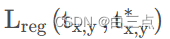 giou_loss,计算损失时只有正样本参与。
giou_loss,计算损失时只有正样本参与。
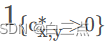 当在(x,y)点为正样本时为1,否则为0。
当在(x,y)点为正样本时为1,否则为0。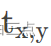 表示在特征图(x,y)点处预测的regression信息,
表示在特征图(x,y)点处预测的regression信息,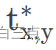 表示在特征图(x,y)点对应的regression参数。
表示在特征图(x,y)点对应的regression参数。
4.3 center-ness损失
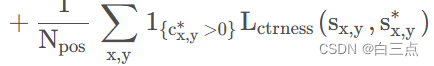
其中,center-ness损失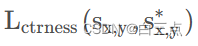 采用二值交叉熵损失,计算时只有正样本参与。
采用二值交叉熵损失,计算时只有正样本参与。
 表示在特征图(x,y)点处预测的center-ness,
表示在特征图(x,y)点处预测的center-ness, 表示在特征图(x,y)点对应的真实center-ness。
表示在特征图(x,y)点对应的真实center-ness。
上面定位损失和center-ness损失只用到了正样本,这里就又又出现了一个新的疑问:如何区分正负样本。
5 正负样本匹配
这里正负样本匹配并不知直接说在bbox框内即为正样本,否则都为负样本。而是采用sub-box,在sub-box内都是正样本,不在都是负样本,如下图所示:
有左侧原图img,目标框bbox,中心坐标周围形成的举行sub-box。右侧特征图feature_mmap,原图映射到特征图的sub-box。

假设中心坐标是(x,y),那么sub-box计算公式如下:
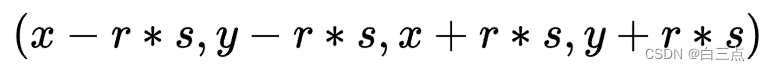 其中,s是特征图相对原图的下采样倍率。r是超参数控制距离GT中心的远近,COCO数据集中设置为1.5。
其中,s是特征图相对原图的下采样倍率。r是超参数控制距离GT中心的远近,COCO数据集中设置为1.5。
具体该公式是什么含义,从上面的图中很容易看出,就是以中心点为中心,在周围形成一个限定区域,大小与取得的超参数r有关。
一个思考:正负样本究竟是如何应用到损失计算中的?
可能是制作训练标签时,所有特征图网格点映射到原图。如果,其中原图中某点在sub-box中,特征图对应的该点为正样本,参与分类损失,定位损失和center-ness损失计算,否则为负样本参与分类损失计算。
6 参考文章
https://blog.csdn.net/qq_37541097/article/details/124844726
https://zhuanlan.zhihu.com/p/121782634
7 代码解读
这里重点总结一下:
- 损失函数
- 文章中不太明白的地方,如是如何公用一个head的
7.1 Head
Head部分的生成代码在model/head.py中,forward如下:
def forward(self, inputs): # input p3-p7
cls_logits=[] # list contains five [batch_size,class_num,h,w]
cnt_logits=[] # list contains five [batch_size,1,h,w]
reg_preds=[] # list contains five [batch_size,4,h,w]
for index, P in enumerate(inputs): # P3, P4, P5, P6, P7
cls_conv_out=self.cls_conv(P)
reg_conv_out=self.reg_conv(P)
cls_logits.append(self.cls_logits(cls_conv_out))
if not self.cnt_on_reg:
cnt_logits.append(self.cnt_logits(cls_conv_out))
else:
cnt_logits.append(self.cnt_logits(reg_conv_out))
reg_preds.append(self.scale_exp[index](self.reg_pred(reg_conv_out)))
return cls_logits, cnt_logits, reg_preds
上面中,for循环遍历的是P3-P7层,每一次循环都输出三个特征层,分别代表分类,定位,和Center-ness。输出结果添加到列表cls_logits,cnt_logits,reg_preds中。最终将三个列表返回。
之后利用这三个列表进行计算损失:
out = self.fcos_body(batch_imgs)
targets = self.target_layer([out, batch_boxes, batch_classes])
losses = self.loss_layer([out, targets])
return losses
从上面看可以看出,共用一个Head,其实是P3-P7各自生成的代表分类,定位,Center-ness的特征层合并到一起去计算损失。
7.2 损失函数
主代码在model/loss.py中,forward如下:
def forward(self,inputs):
'''
inputs list
[0]preds: ....
[1]targets : list contains three elements [[batch_size,sum(_h*_w),1],[batch_size,sum(_h*_w),1],[batch_size,sum(_h*_w),4]]
'''
preds , targets = inputs
cls_logits,cnt_logits,reg_preds=preds
cls_targets,cnt_targets,reg_targets=targets # [batch_size, num_w, 1], [batch_size, num_w, 1], [batch_size, num_w, 4]
mask_pos=(cnt_targets > -1).squeeze(dim=-1) # [batch_size,sum(_h*_w)]
cls_loss=compute_cls_loss(cls_logits,cls_targets,mask_pos).mean() # []
cnt_loss=compute_cnt_loss(cnt_logits,cnt_targets,mask_pos).mean()
reg_loss=compute_reg_loss(reg_preds,reg_targets,mask_pos).mean()
if self.config.add_centerness:
total_loss=cls_loss+cnt_loss+reg_loss
return cls_loss,cnt_loss,reg_loss,total_loss
else:
total_loss=cls_loss+reg_loss+cnt_loss*0.0
return cls_loss,cnt_loss,reg_loss,total_loss
这里cls_targets是根据训练集标签生成的类别特征,FPN生成的Head共有num_w个窗口,窗口不包含物体为0,包含物体为类别标签。
cnt_targets是Center-ness特征,不包含物体为-1,包含为计算的center-ness值。
reg_targets是回归位置参数特征,不包含物体为-1,包含为计算的回归参数。
mask_pos为掩码,(cnt_targets > -1).squeeze(dim=-1)即为包含物体的窗口为True,否则为False。
下面三个函数计算三种损失
















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











