







论文:https://arxiv.org/pdf/1911.08947.pdf
文章目录
DBNet属于文本检测算法,目的是 找到图像中文字的位置。
目前文本检测算法分为两类:
- 基于回归:与目标检测算法的方法相似,文本检测方法只有两个类别,图像中的文本视为待检测的目标,其余部分视为背景。
- 基于分割:从像素层面做分类,判断每一个像素点是否属于一个文本目标,得到文本区域的概率图,通过后处理方式得到文本分割区域的包围曲线。
DBNet是基于分割的文本检测算法。
1 基于分割的文本检测
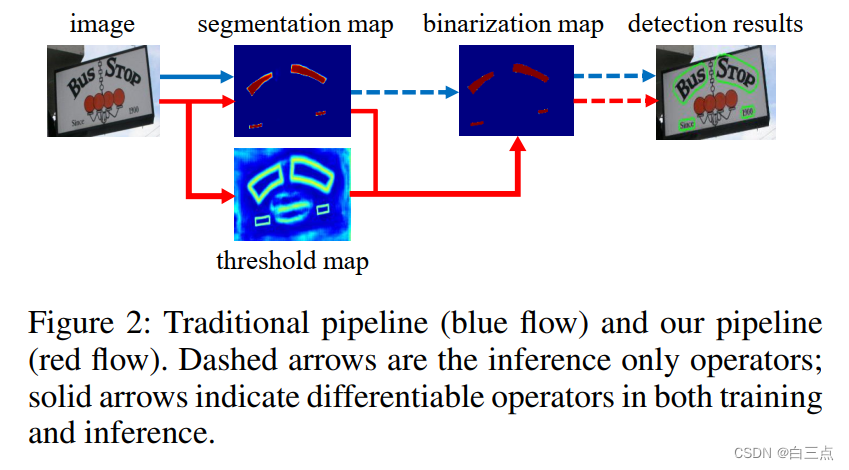
上图蓝色线和红色线展示了两种基于图像分割的文本检测算法思路。
蓝色路线:传统分割方法
- 先输入图像,通过网络输出图片的文本分割结果(一个概率图,每个像素点的值代表着该点正样本的概率)
- 设定一个固定的阈值,将分割网络生成的概率图转换为二值图像
- 使用一些方法,如像素聚类,将像素级的结果转化成检测结果。
但是,这里有一个问题:
标准的二值化操作是不可微的。因此,无法将其写入网络一起训练,自动训练该阈值。
红色路线:即DBNet采用的算法思想,它通过训练threshold map并使用一个近似的可微的二值化函数实现了网络自动训练阈值。之后,文本框可以通过近似二值图和概率图获取。后面会详细总结
2 DBNet
网络结构如下所示:
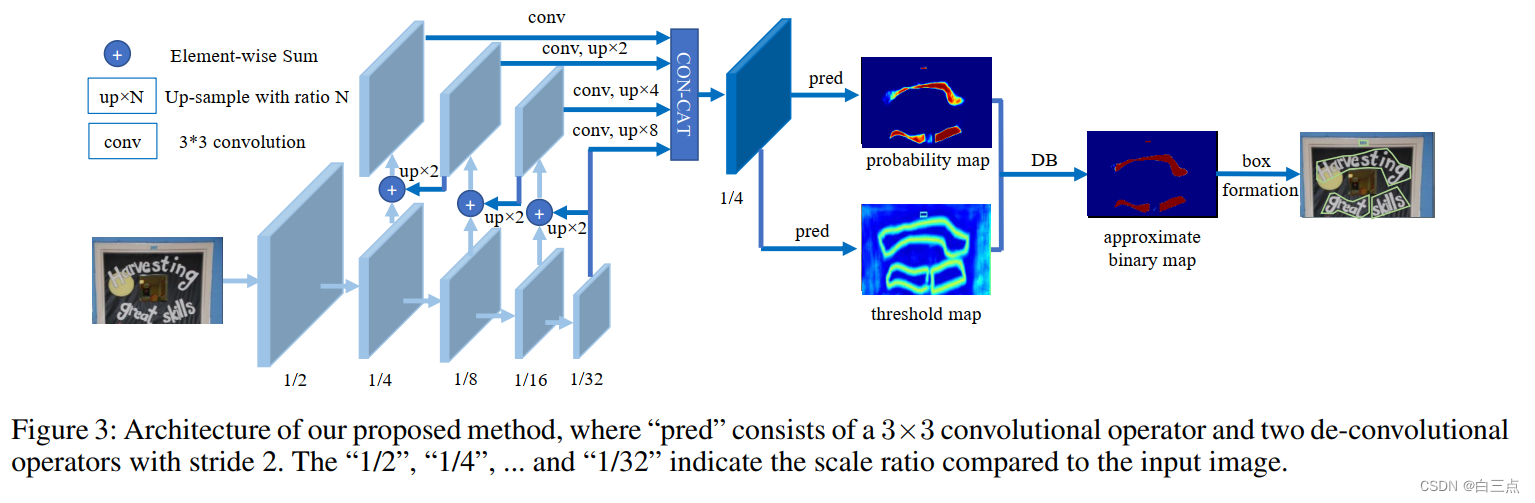
训练过程中:
- 先将图像输入特征提取网络backbone,其中借鉴了FPN的思想。
- 然后利用提取的特征图生成probality map和threshold map。其中,probality map是概率图,threshold map是阈值图。
- 最后,通过概率图和阈值图计算近似二值图。
测试时,可以通过近似二值图得到文本框的位置。
3 backbone
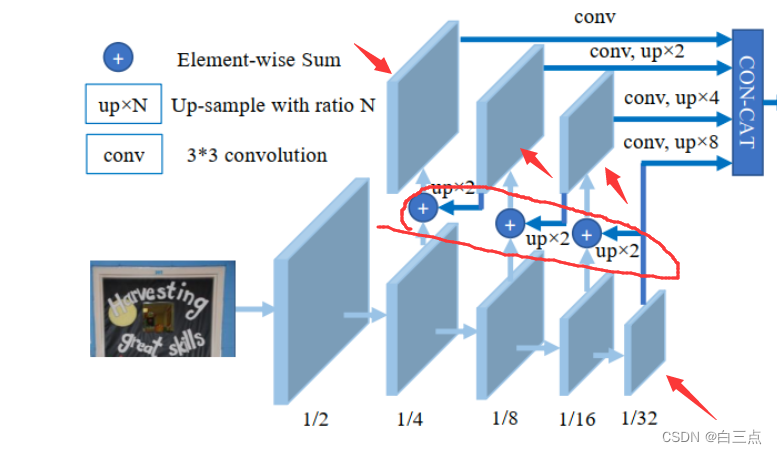
如上图,相加部分借鉴了FPN的思想:https://blog.csdn.net/weixin_51691064/article/details/130274488
而箭头指向的四个卷积是可变形卷积:https://blog.csdn.net/weixin_51691064/article/details/130277558
假设输入src_img为WxH,输出的Feature map是W/4xH/4
4 probability map和threshold map
训练时,网络输出的概率图,阈值图和通过DB操作得到的二值图与训练集相应的形成的特征图进行损失的计算。
测试时,对网络输出的概率图进行后处理,就可以得到框的位置。
这里里面有几个问题:
- 由训练集标真实签如何得到对应的概率图label
- 由训练集真实标签如何得到对应的阈值图label
- 后处理是怎么做的(第7章总结)
- DB如何做的(第5节总结)
4.1 概率图label的生成
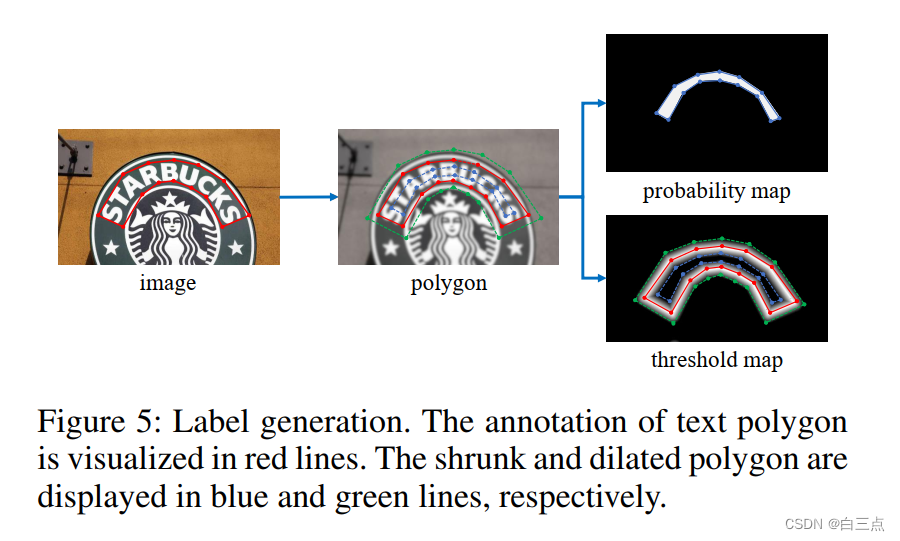
如图,红色为原始区域G,通过收缩得到蓝色区域Gs,通过扩张得到绿色区域Gd。
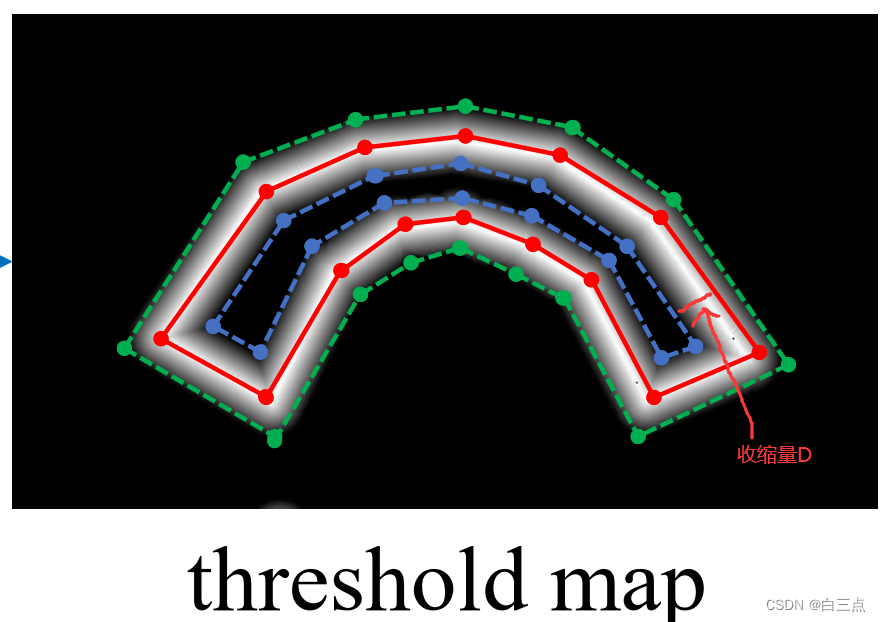
概率图使用蓝色区域,蓝色区域内为1,蓝色外为0。
收缩量D,参考Vatti clipping算法的偏移系数D的计算方式得到:
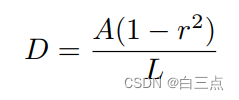
其中A为原始区域面积。L是原始区域周长。r是收缩系数,一般设置为0.4。
4.2 阈值图的生成
- 首先蓝色区域扩张为红色Gd。扩张量与4.1中收缩量一致。并将绿色和蓝色之间作为文本边界区域。
- 计算边界区域每一个点到红色边界的归一化距离(距离/偏移量D)。比如:
=====================================================================
假设一点P,其到红色边界的距离d,经过归一化后的值Value,其再图中的意义如下:
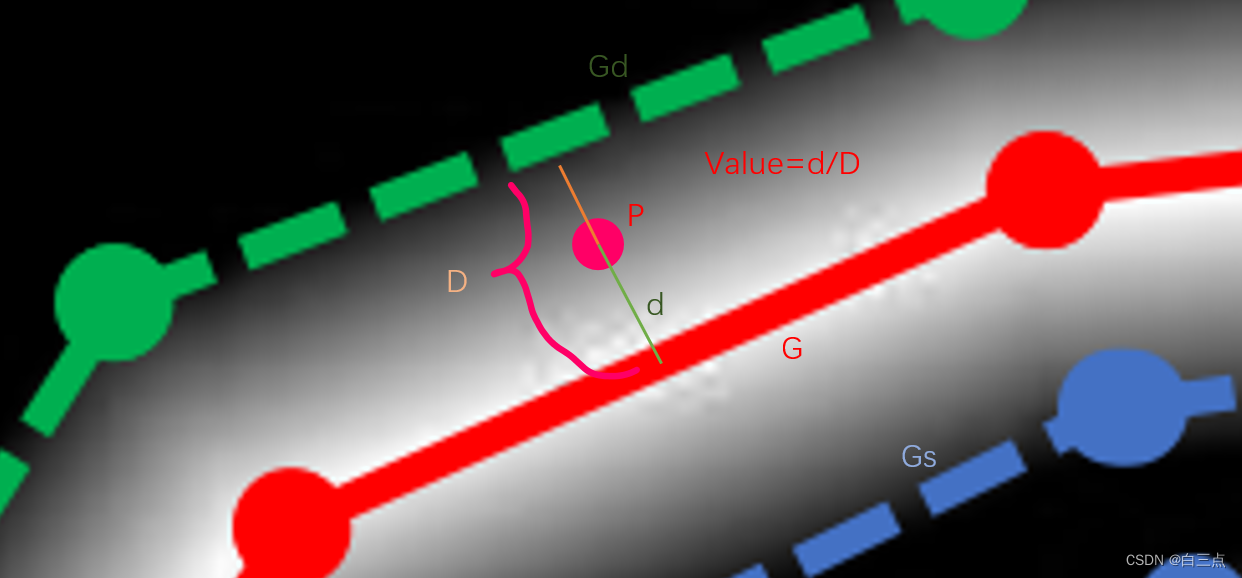
===================================================================== - 用1减得到的归一化后距离。此时值在红色线为1,向Gs和Gd方向递减,在Gs和Gd为0。
至此,得到了概率图label和二值图label。
5 DB
5.1 传统二值化(SB)
对于一个WxH的概率图,设置一个阈值t,对每个位置(i, j)概率超过阈值设置为1,否则设置为0:
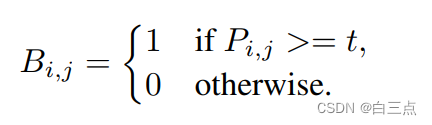
但是该操作是不可微的,无法放入网络进行学习。
5.2 可微的二值化
DB,即可微分二值化,解决了上面的问题。通过概率图P和阈值图T通过该操作可以得到二值图B。每个点的计算公式:
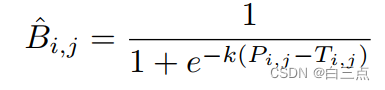
其中k是一个超参数,原文中设置为50。
到这里,我们有了概率图,阈值图和二值图,接下来就是进行损失计算。
6 损失计算
训练时需要计算损失。
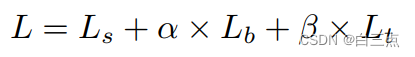
损失函数分为三部分:
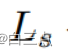 为概率图损失
为概率图损失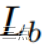 为二值图损失
为二值图损失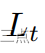 为阈值图损失
为阈值图损失
6.1 概率图损失和二值图损失
这里概率图损失和二值图损失采用的是二值交叉熵损失:
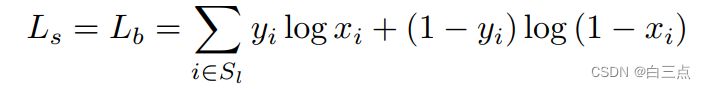
这里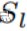 是采样得到的样本,正负样本为1:3。
是采样得到的样本,正负样本为1:3。
这里采样的作用是平衡正负样本,使用的是困难样本挖掘技术OHEM。
6.2 阈值损失
阈值损失采用L1 loss损失:
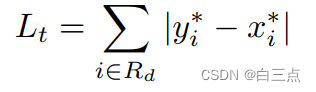
其中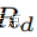 是标注框经过D偏移量扩充后得到的Gd里所有的像素。
是标注框经过D偏移量扩充后得到的Gd里所有的像素。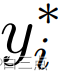 是通过4.2节中训练集真实标签计算出的阈值图中的第i个点的值。
是通过4.2节中训练集真实标签计算出的阈值图中的第i个点的值。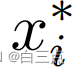 是网络输出的阈值图中第i个点的值。
是网络输出的阈值图中第i个点的值。
7 后处理
通过预测的概率图进行文本框的生成:
- 设置一个固定阈值,对概率图进行二值化
- 通过二值图得到连通区域
- 连通区域采用Vatti clipping算法的偏移系数D’进行扩张得到最终文本框,偏移系数计算公式如下:
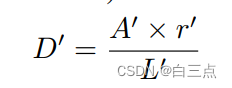
其中A’是连通区域面积。L’是连通区域周长。r’是放缩系数,一般设置为1.5。
8 参考
OCR专栏:
https://blog.csdn.net/qq_36816848/category_12113641.html
DBNet文章:
https://blog.csdn.net/yewumeng123/article/details/127503815
https://zhuanlan.zhihu.com/p/368035566
https://blog.csdn.net/michaelshare/article/details/108811236

















 7201
7201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











