





 UNIMO是一种统一模态预训练架构,旨在同时处理单模态和多模态任务。它通过大规模的自由文本语料库和图像集进行学习,使用跨模态对比学习(CMCL)将文本和视觉信息整合到同一语义空间,增强了模型在文本和视觉理解上的性能。实验表明,UNIMO在单模态和多模态下游任务上表现出色,证明了其统一模态学习的优势。
UNIMO是一种统一模态预训练架构,旨在同时处理单模态和多模态任务。它通过大规模的自由文本语料库和图像集进行学习,使用跨模态对比学习(CMCL)将文本和视觉信息整合到同一语义空间,增强了模型在文本和视觉理解上的性能。实验表明,UNIMO在单模态和多模态下游任务上表现出色,证明了其统一模态学习的优势。
现有的预训练方法或侧重于单模态任务,或侧重于多模态任务,不能有效地相互适应,只能利用单模态数据或有限的多模态数据。作者提出了统一模态预训练体系架构UNIMO,可以有效地适应单模态和多模态的理解生成任务。UNIMO利用大规模自由文本语料库和图像集来提高视觉文本理解能力,利用跨模态对比学习(CMCL)将文本和视觉信息整合到统一语义空间中,形成一个由图像和文本组成的“图像-文本对”语料库。UNIMO借助丰富的非配对单模态数据,通过允许文本视觉知识在统一语义空间中相互增强,从而学习到更泛化的表示。实验结果表明,UNIMO在单模态和多模态下游任务上总体表现最好。

图1:统一模态学习必要性的示例。
如图1所示,仅凭图像中的视觉信息很难正确回答问题。然而,如果我们将视觉信息和描述棒球比赛背景的文本信息联系起来,就很容易根据文本信息确定视觉问题的正确答案。同时,视觉信息也有助于理解文本所描述的场景。
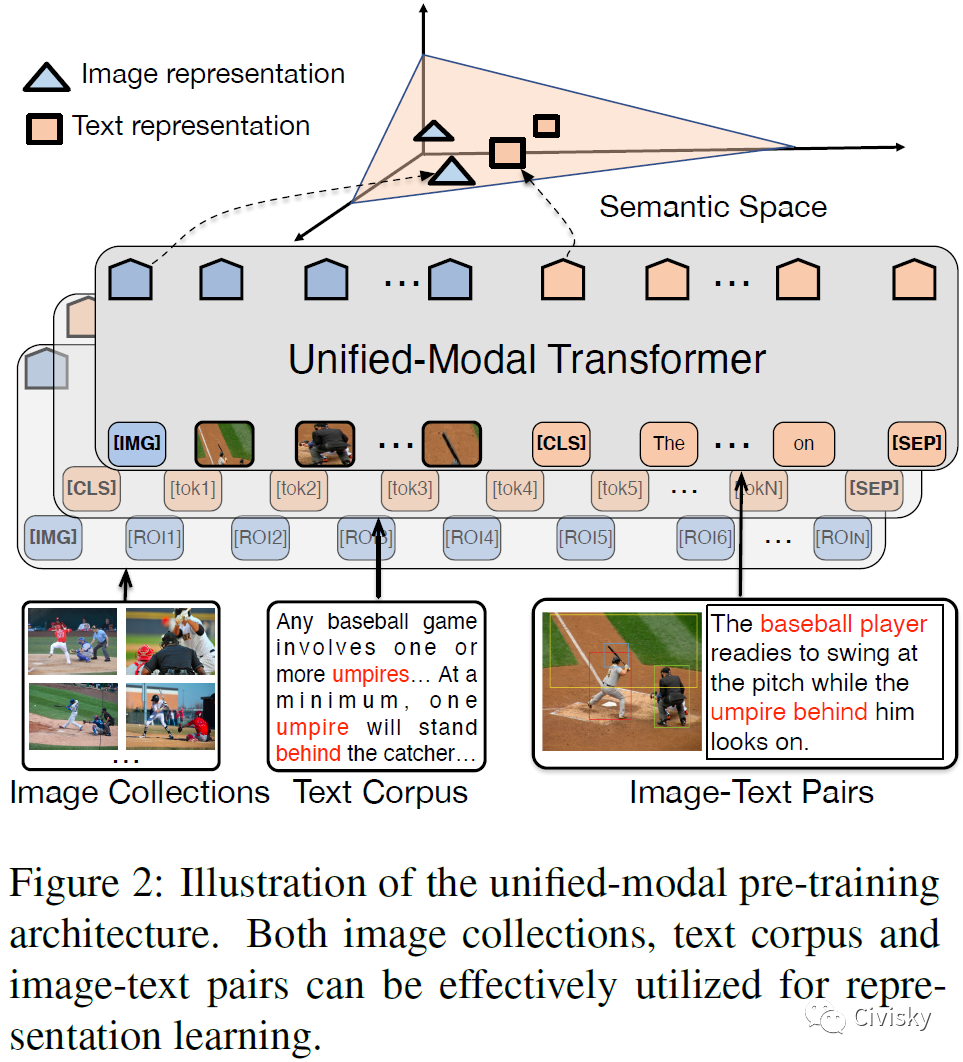
图2:统一模态预训练体系架构。图像集、文本语料库、图像-文本对都可以有效地用于表征学习。
如图2所示,作者提出了统一模态体系架构UNIMO,旨在用一个模型处理多场景、多模态的文本、视觉、视觉-语言数据。UNIMO采用多层自注意力Transformers来学习文本视觉数据的统一语义表征。
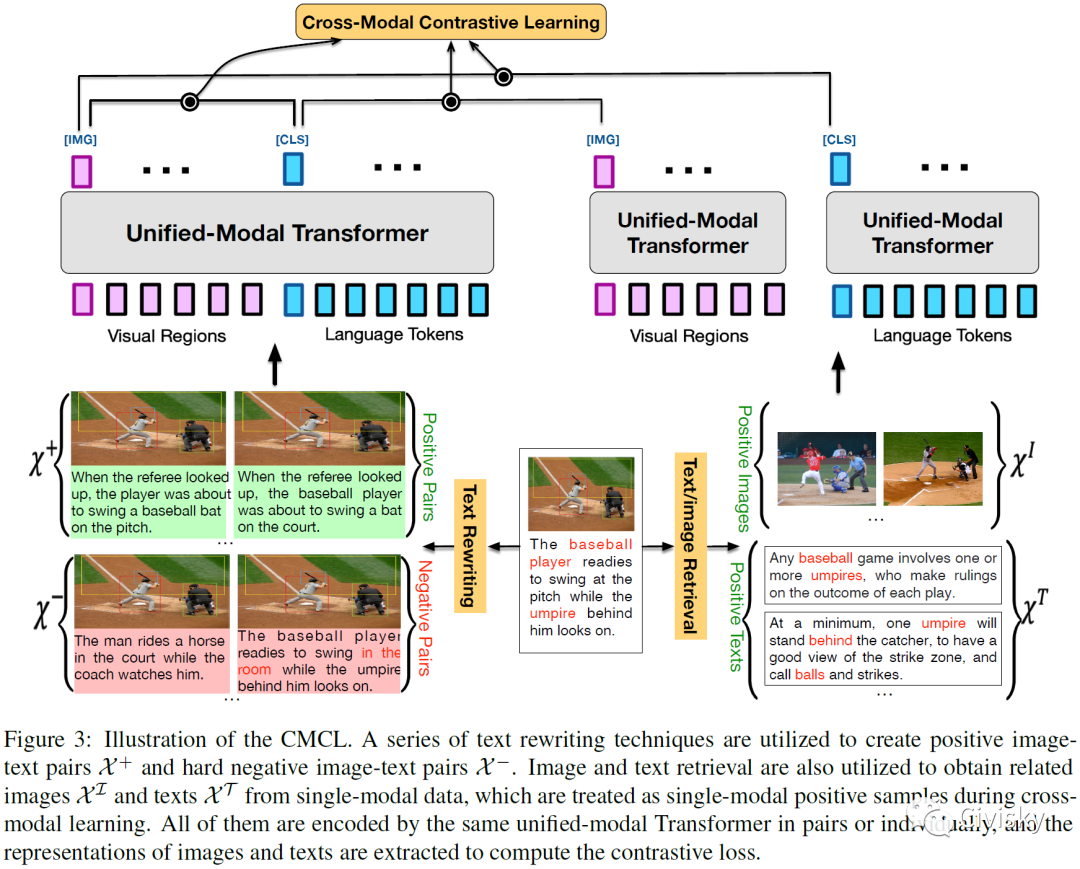
图3:跨模态对比学习(CMCL)。
如图3所示,为了促进视觉和语言在不同层面上的语义对齐,作者设计了几种新颖的文本重写技术,在单词、短语或句子层面对图像原始标题进行重写,并创建正、负图像文本对。作者利用图像文本检索技术从单模态数据中获取相关的图像和文本,在跨模态学习时将其作为单模态正样本处理。
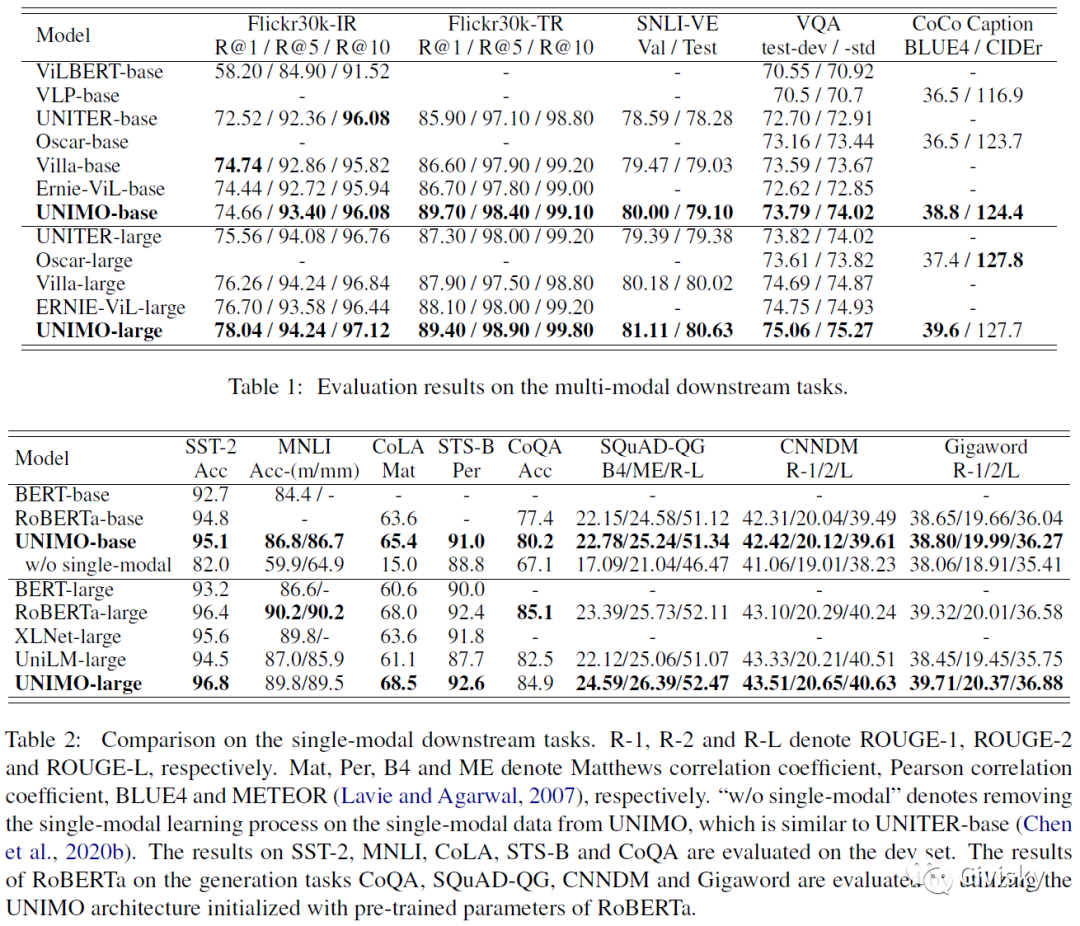
表1:多模态下游任务评估结果。表2:单模态下游任务评估结果。
如表1所示,作者将UNIMO和ViLBERT、VLP、UNITER、Oscar、Villa、ERNIE-ViL多模态预训练模型进行了比较,结果表明,UNIMO总体上取得了最好的成绩。如表2所示,UNIMO在语言理解和生成任务上比BERT、RoBERTa、XLNet和UniLM预训练模型有更好的或相当的表现。UNIMO不仅在多模态任务上取得了最好的成绩,而且在单模态任务上也取得了很好的成绩,这证明了统一模态体系架构的优越性。
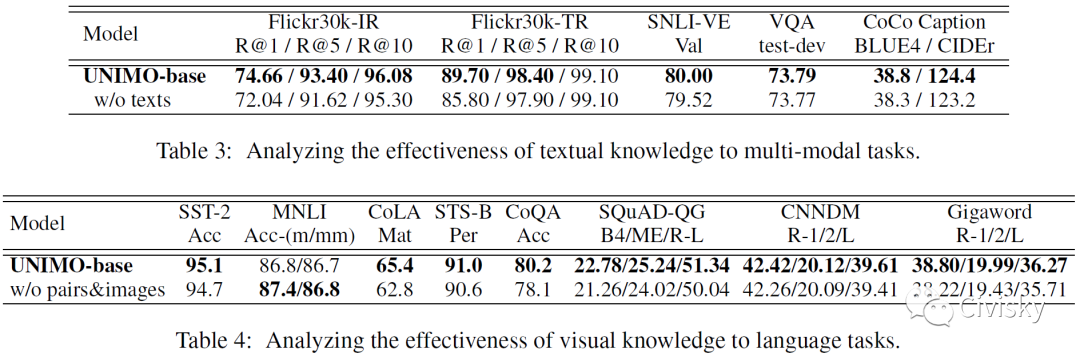
表3:文本知识对多模态任务的有效性分析。表4:视觉知识对语言任务的有效性分析。
UNIMO有助于文本知识和视觉知识在统一语义空间中相互增强。文本知识有助于视觉语言多模态任务的完成,视觉知识也有助于语言任务的完成。

表5:用于预训练的图像-文本对、图像集和文本语料库。
表6:UNIMO的超参数。

表7:UNIMO的预训练过程。

图5:文本检索示例。绿色表示准确的视觉信息,而红色表示错误的信息。

图6:图像检索示例。蓝色表示被基线模型忽略,但被UNIMO准确识别的重要信息。
总结
UNIMO能够利用大规模的非配对文本语料库和图像集进行跨模态学习,有助于文本知识和视觉知识在统一语义空间中相互增强。UNIMO适用于单模态和多模态的理解生成任务,并且在单模态和多模态下游任务上都优于以前的方法。


















 2885
2885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









