







卷积神经网络识别车辆(迁移模型)
此为本人Python与机器学习第一学期大作业技术文档,在此分享给大家!源代码见个人的资源处,已经上传到CSDN
卷积神经网络识别车辆
模型介绍
对于模型的选择,我们这里选择了resnet50的迁移学习模型,以及自己建立了一个卷积神经网络模型,下面为两模型的介绍。
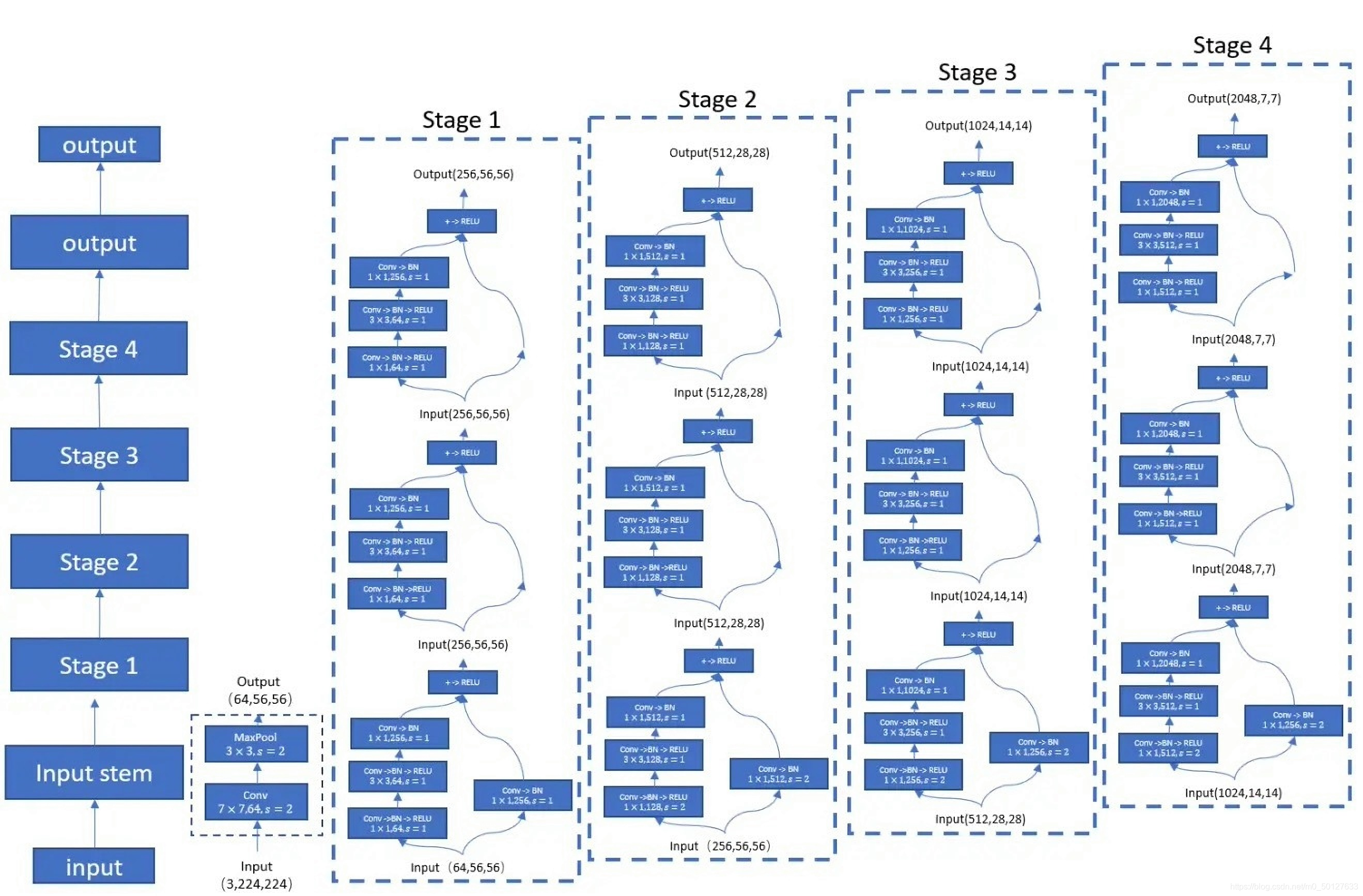
resnet50
resnet的结构图如下,根据网上查询到的资料得知,ResNet50是一个经典的特征提取网络结构,其网络中包含了 49 个卷积层、一个全连接层。Resnet50网络结构可以分成七个部分,第一部分不包含残差块,主要对输入进行卷积、正则化、激活函数、最大池化的计算。第二、三、四、五部分结构都包含了残差块。在 Resnet50 网 络 结 构 中 , 残 差 块 都 有 三 层 卷 积 , 那 网 络 总 共 有1+3×(3+4+6+3)=49个卷积层,加上最后的全连接层总共是 50 层,这也是Resnet50 名称的由来。网络的输入为 224×224×3,经过前五部分的卷积计算,输出为 7×7×2048,池化层会将其转化成一个特征向量,最后分类器会对这个特征向量进行计算并输出类别概率。
参考:https://zhuanlan.zhihu.com/p/373691921
自建模型
对于自建模型主要是参考了下面的博文以及课程:
[1] https://blog.csdn.net/qq_25426559/article/details/122263705
[2] https://blog.csdn.net/qq_40421671/article/details/85319887
此模型的卷积神经网络的结构如下图所示,


可以看到图中有三个卷积层和两个全连接层,其中整个模型的激活函数都只用了relu函数,池化层的核均为2x2的。卷积层的卷积核风别为5x5、4x4、3x3的。输出层与隐层之间存在dropout层以防止过拟合。
程序介绍
在编程方面,此模型和预测混凝土的模型一样也进行了实例化,实例化主要分为数据预处理``模型训练``绘图``模型评价``模型保存与加载五部分,程序的整体架构图下所示,具体代码可见代码文件。

编程详细
-
导入必要库
import torch import torch.nn as nn from torch.nn import Sequential import torchvision from matplotlib import pyplot as plt import torch.nn.functional as F from torch.utils.data import DataLoader, random_split import torchvision.transforms as transforms from tqdm import tqdm import torchvision.models as models import numpy as np from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score, recall_score, f1_score -
定义类与初始化
class CNN_Vir: def __init__(self, path, classes, batch_size=32, epochs=20, lr=0.001, device="gpu", opt=0, lossf=0, model_type=0, load=False): self.model_type = model_type #数据集路径 self.path = path # 车辆标签 self.classes = classes # 批量 self.batch_size = batch_size # 迭代次数 self.epochs = epochs # 学习率 self.lr = lr # 加载器与数据集 self.train_loader, self.test_loader ,\ self.train_dataset, self.test_dataset = self.pre_data() self.model = None self.device = device self.opt = opt self.lossf = lossf self.epoch_loss = [] self.load = load -
数据预处理模块
#预处理数据 返回两个loader 和数据集 def pre_data(self): # 一系列的图片预处理可以由此定义一个对象来处理 if self.model_type == 0: size = 32 else: size = 224 transform = transforms.Compose([ transforms.Resize((size, size)), # 将图片转为tensor transforms.ToTensor(), # 调整图片大小 # 在图片的中间区域进行裁剪 transforms.CenterCrop(size), transforms.RandomHorizontalFlip(p=0.5), # 图片的标准化处理均值和标准差均设为0.5 transforms.Normalize( mean=[0.5, 0.5, 0.5], std=[0.2, 0.2, 0.2] ) ]) # 读取所有图像,利用transform处理 full_data = torchvision.datasets.ImageFolder(root=self.path, transform=transform) # 设置训练集和测试集比例 # 这里train_size是一个长度矢量,并非是比例,我们将训练和测试进行8/2划分 train_size = int(len(full_data) * 0.8) test_size = len(full_data) - train_size # 数据集划分 train_dataset, test_dataset = random_split(full_data, [train_size, test_size]) # 设置数据加载器 train_loader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=self.batch_size, shuffle=True) #返回加载器 return train_loader, test_loader, train_dataset, test_dataset -
模型模块
#自建模型 def cnn_tr(self): # 设置卷积神经网络 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # 二维卷积层 self.conv1 = nn.Conv2d(3, 20, 5, 1) # 二维卷积层 self.conv2 = nn.Conv2d(20, 40, 4, 1) # 二维卷积层 self.conv3 = nn.Conv2d(40, 60, 3, 1) # 全连接层 self.dense = Sequential( nn.Linear(1 * 1 * 60, 400), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(400, 10), ) # N = (W - F + 2P)/S + 1 def forward(self, x): x = F.relu(self.conv1(x)) # 220x220x20 x = F.max_pool2d(x, 2, 2) # 110x110x20 x = F.relu(self.conv2(x)) # 107x107x40 x = F.max_pool2d(x, 2, 2) # 53x53x40 x = F.relu(self.conv3(x)) # 51x51x60 x = F.max_pool2d(x, 2, 2) # 25x25x60 #降维处理 x = x.view(-1, 1 * 1 * 60) x = self.dense(x) return x # 训练 cnn = CNN() if self.device == "gpu": cnn = cnn.cuda() # 利用gpu训练 else: cnn = cnn if self.load: return cnn # 损失函数 if self.lossf == 0: lossF = nn.CrossEntropyLoss() elif self.lossf == 1: lossF = nn.NLLoss2d() elif self.lossf == 2: lossF = nn.NLLLoss2d() # 优化器 if self.opt == 0: optimizer = torch.optim.Adam(cnn.parameters(), lr=self.lr) elif self.opt == 1: optimizer = torch.optim.Adagrad(cnn.parameters(), lr=self.lr) elif self.opt == 2: optimizer = torch.optim.NAdam(cnn.parameters(), lr=self.lr) elif self.opt == 3: optimizer = torch.optim.SGD(cnn.parameters(), lr=self.lr) # 设置这个可以防止利用gpu时报错 torch.backends.cudnn.enable = True torch.backends.cudnn.benchmark = True #定义初始损失 loss_pth = -float("inf") i_pth = 0 epoch_loss = [] # 训练 for epoch in range(self.epochs): running_loss = 0.0 running_correct = 0.0 print("Epochs [{}/{}]".format(epoch, self.epochs)) # 批量训练 for data in tqdm(self.train_loader): X_train, y_train = data #转为gpu格式 X_train, y_train = self.get_variable(X_train), self.get_variable(y_train) outputs = cnn(X_train) #_表示真正的值,predict表示标签值 _, predict = torch.max(outputs.data, 1) optimizer.zero_grad() loss = lossF(outputs, y_train) loss.backward() optimizer.step() #记录损失值与成功个数 running_loss += loss.item() running_correct += torch.sum(predict == y_train.data) epoch_loss.append(running_loss) self.epoch_loss = epoch_loss self.model = cnn def model_resent50(self): my_resnet50 = models.resnet50(pretrained=True) # 由于预训练的模型中的大多数参数已经训练好了,因此先将模型参数的自动梯度求解设为false for param in my_resnet50.parameters(): param.requires_grad = False # 将resnet50最后一层输出的类别数,改为ant-bee数据集的类别数,修改后改成梯度计算会恢复为默认的True fc_inputs = my_resnet50.fc.in_features my_resnet50.fc = nn.Sequential(nn.Linear(fc_inputs, 10)) # 以上操作相当于固定网络全连接层之前的参数,只训练全连接层的参数 # 损失函数 if self.lossf == 0: lossF = nn.CrossEntropyLoss() elif self.lossf == 1: lossF = nn.NLLLoss() elif self.lossf == 2: lossF = nn.NLLLoss2d() # 优化器 if self.opt == 0: optimizer = torch.optim.Adam(my_resnet50.parameters()) elif self.opt == 1: optimizer = torch.optim.Adagrad(my_resnet50.parameters()) elif self.opt == 2: optimizer = torch.optim.NAdam(my_resnet50.parameters()) elif self.opt == 3: optimizer = torch.optim.SGD(my_resnet50.parameters(), lr=self.lr) if self.device == "gpu": my_resnet50 = my_resnet50.cuda() if self.load: return my_resnet50 my_resnet50.train() epoch_loss = [] for epoch in range(self.epochs): losses = [] for inputs, outputs in tqdm(self.train_loader): optimizer.zero_grad() # 前向传播 inputs = self.get_variable(inputs) outputs = self.get_variable(outputs) results = my_resnet50(inputs) # loss计算 loss = lossF(results, outputs) losses.append(loss.item()) # 梯度计算 loss.backward() # 参数更新 optimizer.step() epoch_loss.append(torch.tensor(losses).mean().item()) print("epoch: {0} Loss: {1}".format(epoch, epoch_loss[epoch])) self.model = my_resnet50 self.epoch_loss = epoch_loss -
类型转换函数
# 返回可自动梯度求导的变量 # 这里这样设置是为了使用gpu def get_variable(self, x): x = torch.autograd.Variable(x) if self.device == "gpu": return x.cuda() elif self.device == "cpu": return x else: return x.cuda() if torch.cuda.is_available() else x -
主程序模块
#主程序 def run(self): if self.model_type == 0: self.cnn_tr() elif self.model_type == 1: self.model_resent50() -
绘图模块
#绘图 def draw(self, type="iter"): if self.epoch_loss: plt.title("loss vs. Number of Training Epochs") plt.xlabel("Training Epochs") plt.ylabel("Loss") plt.plot(range(self.epochs), self.epoch_loss, label="train") plt.xticks(np.arange(0, self.epochs)) plt.legend() plt.show() else: raise "Please train first!" -
评价模块
#模型评价 def evaluate(self): from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score, recall_score, f1_score from tqdm import tqdm label_t = torch.Tensor() predicted_t = torch.Tensor() self.model.eval() for i, data in enumerate(tqdm(self.test_loader), 0): inputs, labels = data inputs = self.get_variable(inputs) labels = self.get_variable(labels) outputs = self.model(inputs) image, predicted = torch.max(outputs, 1) labels = labels.cpu() predicted = predicted.cpu() label_t = torch.cat((label_t, labels), 0) predicted_t = torch.cat((predicted_t, predicted), 0) acc = accuracy_score(label_t, predicted_t) p = precision_score(label_t, predicted_t, average='macro') r = recall_score(label_t, predicted_t, average='macro') f1score = f1_score(label_t, predicted_t, average='macro') print('The testing set Accuracy of the network is:', acc) print('The testing set Precision of the network is:', p) print('The testing set Recall of the network is:', r) print('The testing set F-score of the network is:', f1score) -
模型保存与加载模块
#保存训练模型 def save(self, name="model.pth"): torch.save(self.model.state_dict(), name) #加载模型 def load_model(self, name="model.pth"): checkpoint = torch.load(name) if self.model_type == 0: self.model = self.cnn_tr() self.model.load_state_dict(checkpoint) elif self.model_type == 1: self.model = self.model_resent50() self.model.load_state_dict(checkpoint) if self.device == "gpu": self.model = self.model.cuda() -
定义对象
#定义数据集路径 path = "./train/" #车辆种类 classes = ["bus", "family sedan", "fire engine", "heavy truck", "jeep", "minibus", "racing car", "SUV", "taxi", "truck"] test = CNN_Vir(path, classes, device="gpu", model_type=1, epochs=3, batch_size=32, lossf=1) test.run() test.evaluate()
模型讨论
模型训练参数的选择
我们的模型中大多数参数是可以改变的,下表为对应的可变参数以及其对应可选择项,
| 参数 | 值/可选项 |
|---|---|
| batch_size | 默认为32 |
| epochs迭代次数 | 默认为20 |
| 学习率 | 默认为0.001 |
| 设备 | 默认为gpu |
| 优化器 | Adam/Adagrad/NAdam/SGD |
| 损失函数 | 交叉熵/负对数似然函数/图片负对数似然函数损失 |
| 模型选择 | resent50/自建模型 |
参数详细说明:
model = CNN_Vir(path, classes, batch_size=32, epochs=20, lr=0.001, device="gpu", opt=0, lossf=0, model_type=0, load=False)
#path表示训练集路径
#classes用来传入标签 在对象里其实并未用到
#batch_size表示每次训练的照片个数
#epochs表示迭代次数
#lr表示学习率
#device是用来选择用cpu还是gpu进行训练
#opt为优化器的选择 0表示Adam 1表示Adagrad 2表示NAdam 3表示SGD
#lossf表示损失函数类型 0为交叉熵 1为负对数似然函数 2为图片负对数似然函数
#model_type为模型类型 这里提供了我们自己建的模型以及迁移模型resent50
#load是为了加载训练模型而设置的 由于每次训练都会耗费很多时间 所以设置这个来加载之前已经训练完成的模型
loss 值随 epoch 次数的变化曲线
曲线图均为在只改变模型类型参数的基础上绘制,其余默认参数未变。
resnet50

由图像可知,resent50模型的一开始的loss值就已经很低,随着迭代的增加其更加趋于0。
自建立模型

自建模型的损失值一开始处于较大的值,在迭代之后可以发现loss值一直处于下降,可以发现仅仅20次还未达到收敛。可以进一步地提高训练的迭代次数,同时可以通过加载模型功能在之前的模型基础上继续训练。
参数改变的讨论
由于每次训练所需要耗费的时间太长,所以参数的改变只以resnet50为例,对以下三个参数进行讨论。除改变对应参数外其他参数均为默认值。同时为了更快地得到结果,除迭代次数的参数讨论外,其余迭代次数改为了5。
-
batchsize
将batchsize分为16、32、64三个值进行讨论,画出下图的loss 值随 epoch 次数的变化曲线与准确率对比图。


由于resent50模型都是经过了预训练的所以区别并不会太明显,但是由图中可以知道,batchsize在64与16时将比32更优秀,不过此结论需要训练多次才可以验证。
-
迭代次数
将迭代次数分为10、20、30三个值进行讨论,画出下图的loss 值随 epoch 次数的变化曲线与准确率对比图。


可以看出随着迭代次数的增加其曲线与准确率均无太大变化,说明resnet50模型在迭代次数为10时已经收敛。
-
损失函数
将迭代次数分为交叉熵、负对数似然函数、图片负对数似然函数三种类别进行讨论,画出下图的loss 值随 epoch 次数的变化曲线与准确率对比图。参数的选择均参考与网上关于多分类的损失函数介绍。


可以看到用于多分类的损失函数中,交叉熵函数会更加地适合图像的多分类。
模型准确率

由于自建模型的模型结构不是很好也不是很适合所以,最后预测的效果仅仅只有80%所有的正确率。最后的自建模型由于训练后死机问题,所以最后是加载之前训练模型的基础上得到的评估值。
模型采用的提高准确率的技术
-
迁移学习
我们使用的迁移学习方法是resnet,利用此模型可以调用一些预训练的参数以加快训练的速度以及准确率。
-
数据归一化
在数据预处理时,利用了transform中数据标准化的方法,将图片的标准化处理均值和标准差均设为0.5。
-
数据增强
为了增加提高泛化能力,在数据预处理时进行了如下的操作,
-
中心裁剪
在指定的位置处进行裁剪
-
水平翻转
设置一个概率进行水平翻转
-
-
为了提高训练的效率模型使用的是gpu进行训练的。如下为gpu运行于cpu运行的对比图。其中批数为32时gpu每以批次运行时间为1.89s,而cpu则为4.99秒,其相差接近三倍。



















 3174
3174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









