






每日进阶-基于机器学习的入侵检测系统——打怪升级之道
在当今的数字时代,网络安全不仅是防御,更是主动出击。你是否想知道如何用机器学习技术设计一套入侵检测系统(IDS),让黑客无所遁形?本系列文章将为您揭开这一神秘领域的面纱,从数据准备到模型实现,全方位手把手指导,让你在毕业设计中技惊四座。
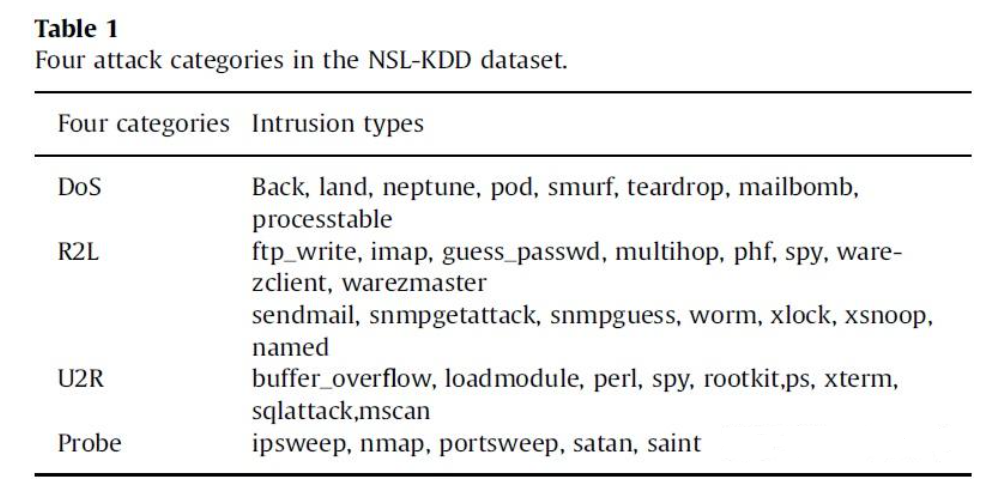
探索NSL-KDD数据集:入侵检测的起点
如何在浩如烟海的数据中找出网络攻击的蛛丝马迹?NSL-KDD数据集就是你踏上入侵检测之旅的第一步。在这篇文章中,我们将带你深入解析这一经典数据集,了解它的结构和应用场景,揭开入侵检测的神秘面纱。准备好挖掘数据的宝藏了吗?
机器学习模型选择与优化:打造智能IDS
面对琳琅满目的机器学习模型,你是否也感到无从下手?别担心,这篇文章将为你详细讲解各种模型的优缺点,帮助你选择最适合的模型,并进行优化。是时候给你的入侵检测系统装上最强“大脑”了!
生成PCAP测试数据包:模拟真实网络攻击场景
想要亲身体验网络攻防的激烈对决?定制PCAP测试数据包就是你的战场。在这篇文章中,我们将指导你生成和使用PCAP数据包,模拟各种网络攻击场景,提升入侵检测系统的实战能力。准备好迎接一场震撼的网络战争了吗?
数据特征提取与计算:从原始数据到有价值信息
如何从杂乱无章的原始数据中提炼出有价值的信息?这正是数据特征提取的魅力所在。在这里,我们将深入探讨数据特征的提取方法,帮助你从原始数据中挖掘出有用的信息,为后续的模型训练打下坚实基础。是时候让你的数据变得聪明起来!
实战指南:将真实数据导入机器学习模型
模型准备好了,但如何在实际中应用?这篇文章将教你如何将真实数据导入机器学习模型,进行实际的入侵检测。一步步的操作指南,带你完成从数据到模型的全流程,让你真正掌握入侵检测的实战技能。准备好迎接现实的挑战了吗?
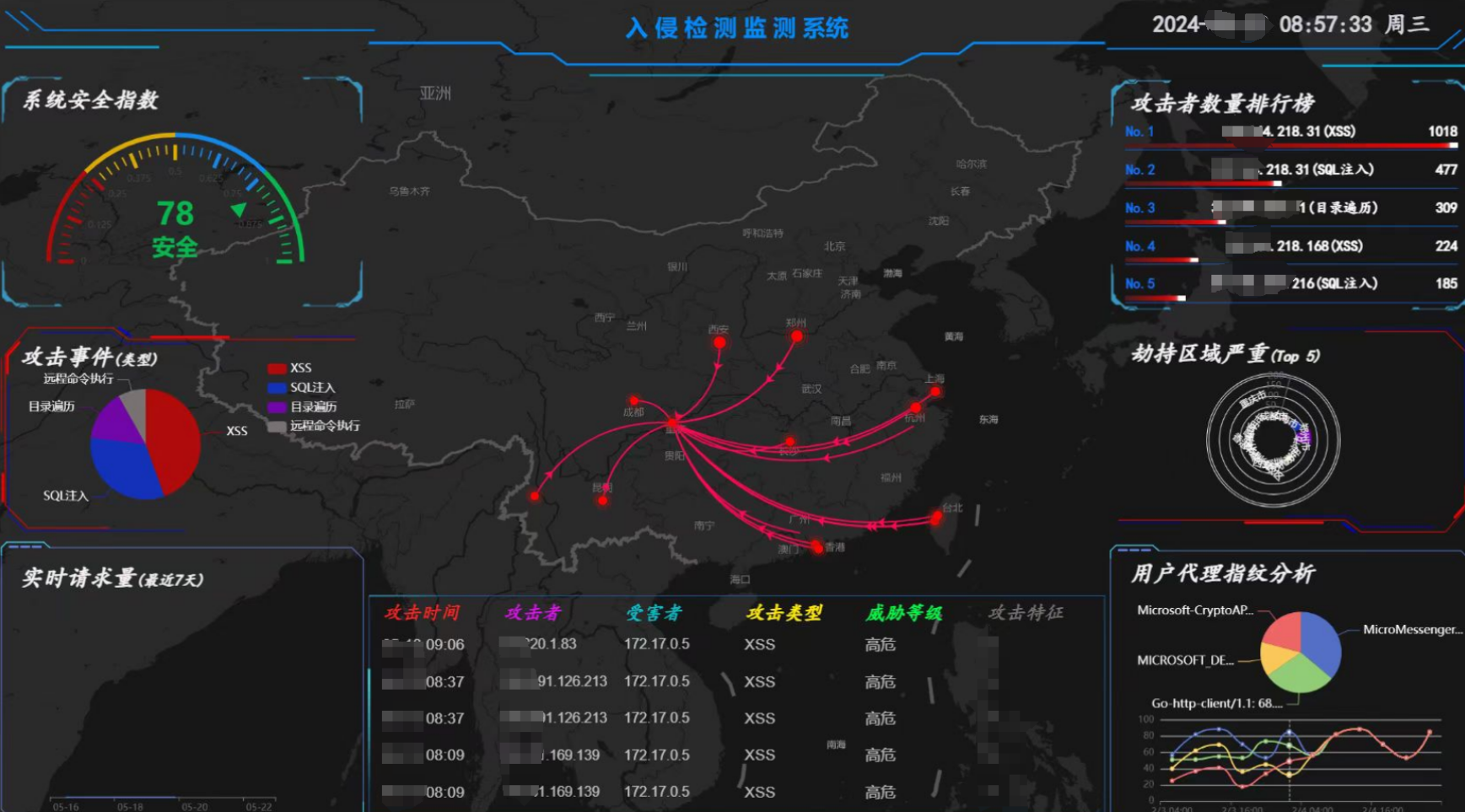
构建与展示:基于机器学习的入侵检测系统Web端实现
最后一步,也是最激动人心的一步:将你的入侵检测系统展示给全世界。在这里,我们将教你如何将基于机器学习的入侵检测系统进行Web端实现,构建一个直观且强大的展示平台。准备好接受大家的赞叹与掌声了吗?
总结
这六篇文章将逐步带你完成从数据准备、模型训练到实际部署的全过程,使你能够设计和实现高效的入侵检测系统。每一篇文章都将为你的毕业设计提供新的思路和实践指南,让你在网络安全的世界中游刃有余。
有💴的捧个Q场,实在不行点赞收藏+关注走一波嘛~

预告
你是否已经迫不及待地想要开始这场入侵检测的学习之旅?下一期内容,我们将带你深入探讨NSL-KDD数据集,带你从零开始了解入侵检测的基础。敬请期待,不要错过任何一个精彩瞬间!
源码指导与教学
毕业设计难搞定? 考研、找工作忙得不可开交? 别担心, 我们团队提供专业可靠的代做服务,帮你轻松解决毕设需求,助你答辩一路绿通。高效、安心,全面服务,一对一跟进,确保你的毕业之旅顺利完成!我们不仅提供高质量的代写服务,更希望通过我们的努力,让你在掌握知识的同时,感受到数字世界的魅力。
每个大学生都梦想在毕业设计中大放异彩,而基于机器学习的入侵检测系统正是你脱颖而出的绝佳机会。让我们一起开启这段充满挑战与成就的旅程,成为网络安全领域的未来之星!















 2779
2779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









