






Self-Attention 李宏毅2021笔记
解决的问题
Self-Attention 考虑输入的不同部分之间的相关性
基础计算方式
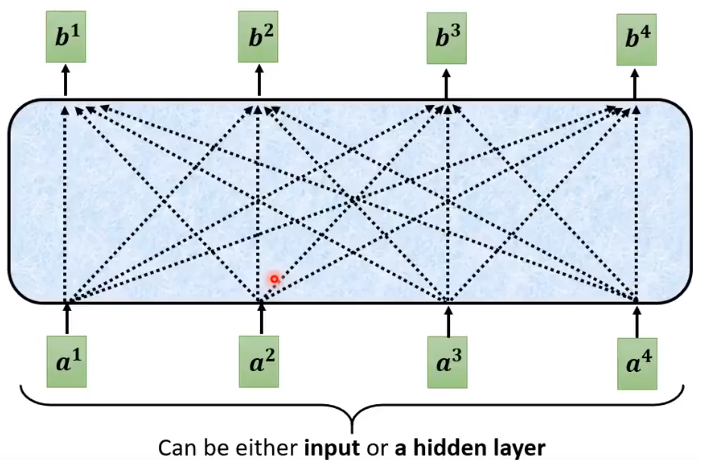
假设 a 1 , a 2 , a 3 , a 4 a^1, a^2, a^3,a^4 a1,a2,a3,a4为输入的四个部分,或是来自上一个隐藏层的输出,要考虑他们之间的关联性,并输出 b 1 , b 2 , b 3 , b 4 b^1,b^2,b^3,b^4 b1,b2,b3,b4。
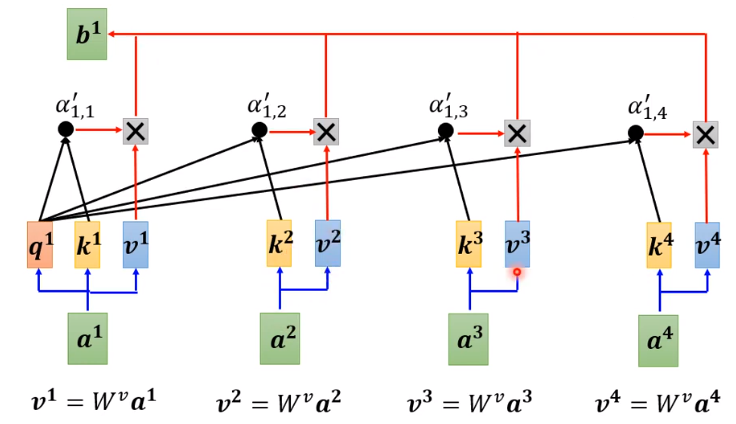
单个输出的计算方式如上图所示,其中 query、key、value 均通过输入乘以矩阵 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv 计算而来,且该参数可以学习。
- 计算 a 1 a^1 a1 与其他部分的输入关系,即将 a 1 a^1 a1 乘以矩阵 W q W^q Wq 得到其对应 query q 1 q^1 q1
- 将所有的输入部分乘以 W k W^k Wk 得到对应 key k 1 , k 2 , k 3 , k 4 k^1, k^2, k^3, k^4 k1,k2,k3,k4 (此处包括计算 a 1 a^1 a1)
- 将 q 1 q^1 q1 与 k 1 , k 2 , k 3 , k 4 k^1, k^2, k^3, k^4 k1,k2,k3,k4 分别相乘得到他们之间的关联程度 α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 \alpha_{1,1},\alpha_{1,2},\alpha_{1,3},\alpha_{1,4} α1,1,α1,2,α1,3,α1,4
- 将 α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 \alpha_{1,1},\alpha_{1,2},\alpha_{1,3},\alpha_{1,4} α1,1,α1,2,α1,3,α1,4 做 softmax 处理,使其权值相加为 1,得到 α 1 , 1 ′ , α 1 , 2 ′ , α 1 , 3 ′ , α 1 , 4 ′ \alpha_{1,1}',\alpha_{1,2}',\alpha_{1,3}',\alpha_{1,4}' α1,1′,α1,2′,α1,3′,α1,4′
- 使用 a 1 , a 2 , a 3 , a 4 a^1, a^2, a^3,a^4 a1,a2,a3,a4 乘以 W v W^v Wv 得到对应 value v 1 , v 2 , v 3 , v 4 v^1, v^2, v^3,v^4 v1,v2,v3,v4
- 将 α 1 , 1 ′ , α 1 , 2 ′ , α 1 , 3 ′ , α 1 , 4 ′ \alpha_{1,1}',\alpha_{1,2}',\alpha_{1,3}',\alpha_{1,4}' α1,1′,α1,2′,α1,3′,α1,4′ 与对应 v 1 , v 2 , v 3 , v 4 v^1, v^2, v^3,v^4 v1,v2,v3,v4 相乘后并相加即可得到输出 b 1 b^1 b1
向量化计算方式
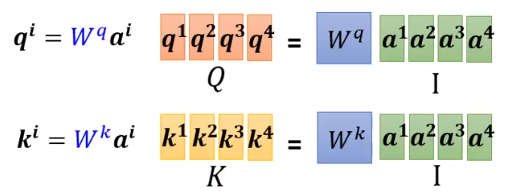
D
e
n
o
t
e
.
Q
=
[
q
1
,
q
2
,
q
3
,
q
4
]
,
K
=
[
k
1
,
k
2
,
k
3
,
k
4
]
,
I
=
[
a
1
,
a
2
,
a
3
,
a
4
]
Q
=
W
q
I
K
=
W
k
I
Denote.\quad Q = [q^1, q^2, q^3, q^4],\quad K = [k^1, k^2, k^3, k^4],\quad I = [a^1, a^2, a^3, a^4]\\[1em] Q = W^q I\\ K = W^k I
Denote.Q=[q1,q2,q3,q4],K=[k1,k2,k3,k4],I=[a1,a2,a3,a4]Q=WqIK=WkI
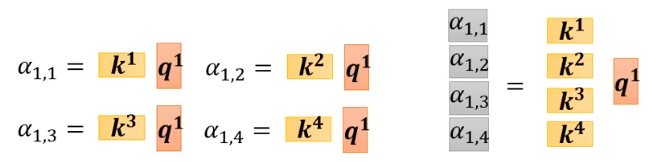
D
e
n
o
t
e
.
A
1
=
[
α
1
,
1
,
α
1
,
2
,
α
1
,
3
,
α
1
,
4
]
A
1
T
=
K
T
q
1
Denote.\quad A_1 = [\alpha_{1,1}, \alpha_{1,2}, \alpha_{1,3}, \alpha_{1,4}]\\[1em] A_1^T = K^T q^1
Denote.A1=[α1,1,α1,2,α1,3,α1,4]A1T=KTq1
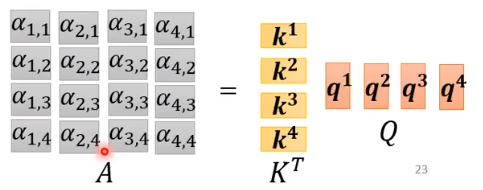
A
=
[
A
1
T
,
A
2
T
,
A
3
T
,
A
4
T
]
=
K
T
Q
A = [A_1^T , A_2 ^T , A_3^T, A_4^T] = K^T Q
A=[A1T,A2T,A3T,A4T]=KTQ
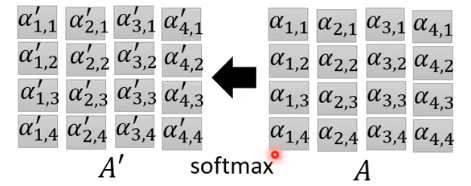
A
′
=
softmax
(
A
)
A' = \operatorname{softmax} (A)
A′=softmax(A)
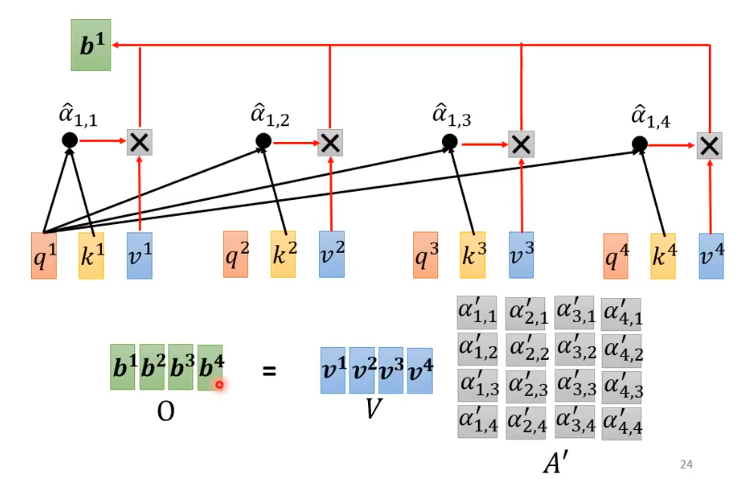
D e n o t e . V = [ v 1 , v 2 , v 3 , v 4 ] V = W v I O = [ b 1 , b 2 , b 3 , b 4 ] = V A ′ Denote.\quad V = [v^1, v^2, v^3, v^4]\\[1em] V = W^v I\\ O = [b^1, b^2, b^3, b^4] = VA' Denote.V=[v1,v2,v3,v4]V=WvIO=[b1,b2,b3,b4]=VA′
即
O = W v I softmax ( ( W k I ) T W q I ) O = W^v I\operatorname{softmax}((W^k I)^T W^q I) O=WvIsoftmax((WkI)TWqI)
需要学习的参数只有 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv。
Multi-head Self-attention (MHSA)
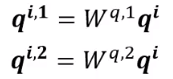
MHSA 与常规 Self-attention 的区别为:每一个部分输入有多个 W q 、 W k 、 W v W^q、W^k、W^v Wq、Wk、Wv。
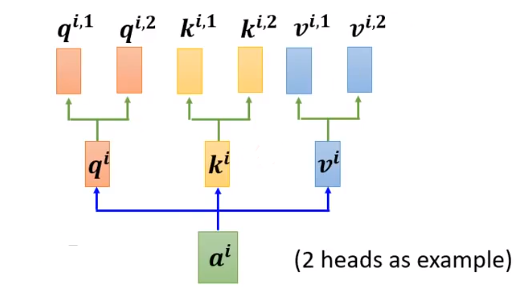
如有输入 a 1 , a 2 , ⋯ , a n a^1, a^2,\cdots,a^n a1,a2,⋯,an,设 head 的数量为 M,则对于任意 a i a^i ai 对应有 query q i , m q^{i,m} qi,m ,也有对应 key k i , m k^{i,m} ki,m ,value v i , m v^{i,m} vi,m 其中 m = 1 , 2 , ⋯ , M m = 1,2,\cdots, M m=1,2,⋯,M。
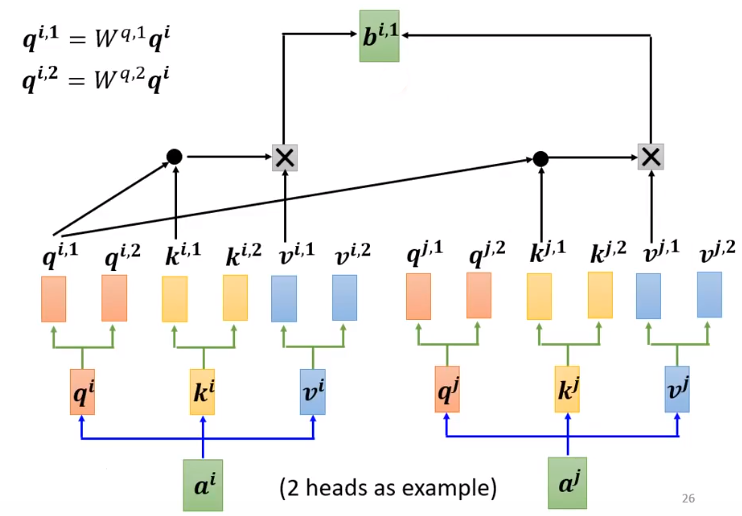
得到
a
i
a^i
ai 的 M 个
q
q
q 后,让所有项的
k
k
k 与其对应相乘,即
q
i
,
1
q^{i,1}
qi,1 分别乘以
k
j
,
1
k^{j,1}
kj,1 ,
q
i
,
2
q^{i,2}
qi,2 分别乘以
k
j
,
2
k^{j,2}
kj,2 其中
j
=
1
⋯
n
j = 1\cdots n
j=1⋯n ,得到
α
i
,
j
,
m
\alpha^{i,j,m}
αi,j,m,其中
m
=
1
,
2
,
⋯
,
M
m = 1,2,\cdots, M
m=1,2,⋯,M 。将他们进行 softmax 操作之后同样乘以各项的 value并相加得到
b
i
,
m
b^{i,m}
bi,m 即:
b
i
,
m
=
∑
j
=
1
N
v
j
,
m
α
i
,
j
,
m
b^{i,m} = \sum_{j=1}^Nv^{j,m}\alpha^{i,j,m}
bi,m=j=1∑Nvj,mαi,j,m
b
i
b^i
bi 的计算方式为,将
b
i
,
1
,
b
i
,
2
,
⋯
,
b
i
,
m
b^{i,1},b^{i,2},\cdots,b^{i,m}
bi,1,bi,2,⋯,bi,m 做 concat 操作后,再通过一个全连接层得到:
b
i
=
W
[
b
i
,
1
,
b
i
,
2
,
⋯
,
b
i
,
m
]
b^i = W[b^{i,1},b^{i,2},\cdots,b^{i,m}]
bi=W[bi,1,bi,2,⋯,bi,m]
以上为 MHSA 的做法。















 2183
2183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









