







从向量点乘说起
提示:这里可以添加技术概要
Transformer1论文中使用了注意力Attention机制,注意力Attention机制的最核心的公式为: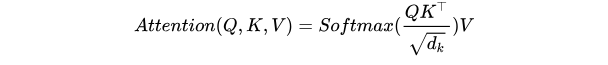
这个公式中的Q、K和V分别代表Query、Key和Value,他们之间进行的数学计算并不容易理解。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
Q与 K T K^T KT 经过 M a t M u l MatMul MatMul,生成了相似度矩阵。对相似度矩阵每个元素除以 d k \sqrt{d_{k}} dk, d k d_{k} dk为 K K K的维度大小。这个除法被称为Scale。当 d k d_{k} dk很大时, Q K T QK^T QKT的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。
我们先从 S o f t m a x ( X X ⊤ ) X Softmax(\mathbf{X}\mathbf{X}^\top)\mathbf{X} Softmax(XX⊤)X这样一个公式开始。
-
S
o
f
t
m
a
x
(
X
X
⊤
)
Softmax(\mathbf{X}\mathbf{X}^\top)
Softmax(XX⊤), 点积跟余弦相似度的公式比较像,也是衡量两个向量在方向上的相似性。
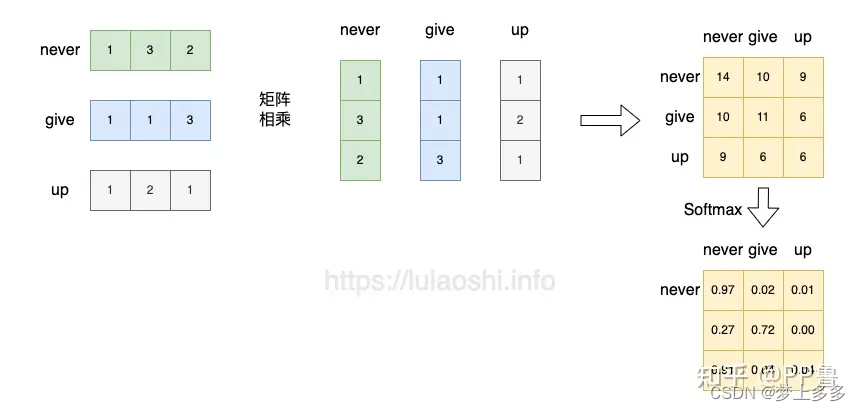
-
S
o
f
t
m
a
x
(
X
X
⊤
)
X
Softmax(\mathbf{X}\mathbf{X}^\top)\mathbf{X}
Softmax(XX⊤)X 将得到的归一化的权重矩阵与词向量矩阵相乘。权重矩阵中某一行分别与词向量的一列相乘,词向量矩阵的一列其实代表着不同词的某一维度。经过这样一个矩阵相乘,相当于用每个字的权重对每个字的特征进行加权求和,得到结果词向量是经过加权求和之后的新表示,而权重矩阵是经过相似度和归一化计算得到的。
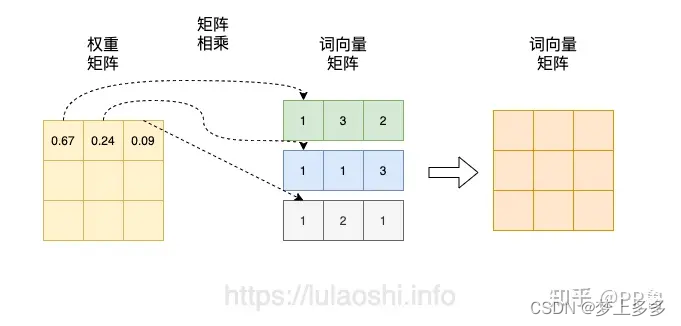
https://www.zhihu.com/tardis/zm/art/414084879?source_id=1005
https://blog.csdn.net/fzz97_/article/details/128920353
https://blog.csdn.net/vivi_cin/article/details/131371433
详解Transformer (Attention Is All You Need)
提示:这里可以添加技术整体架构
Multi-Head Attention
Multi-Head Attention相当于 h h h 个不同的self-attention的集成(ensemble),在这里我们以 h = 8 h=8 h=8 举例说明。Multi-Head Attention的输出分成3步:
- 将数据 X X X 分别输入到图13所示的8个self-attention中,得到8个加权后的特征矩阵 Z i , i ∈ { 1 , 2 , . . . , 8 } Z_i, i \in \{1,2,...,8\} Zi,i∈{1,2,...,8} 。
- 将8个 Z i Z_i Zi 按列拼成一个大的特征矩阵;
- 特征矩阵经过一层全连接后得到输出
Z
Z
Z 。
整个过程如下图所示: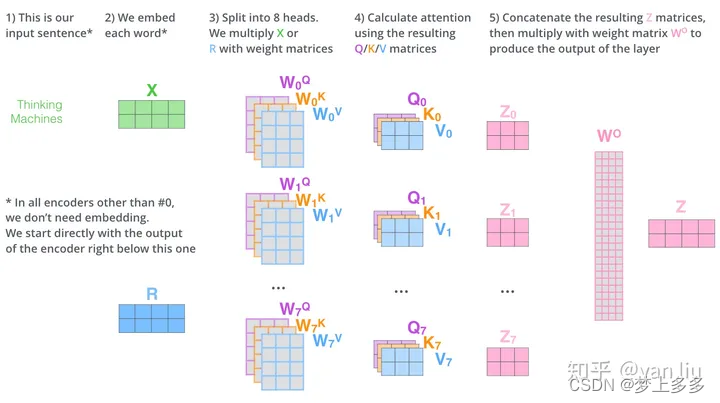
同self-attention一样,multi-head attention也加入了short-cut机制。
Encoder-Decoder Attention
在解码器中,Transformer block比编码器中多了个encoder-cecoder attention。在encoder-decoder attention中,
Q
Q
Q来自于解码器的上一个输出,
K
K
K,
V
V
V 则来自于与编码器的输出。其计算方式完全和图10的过程相同。
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第
个特征向量时,我们只能看到第
及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。
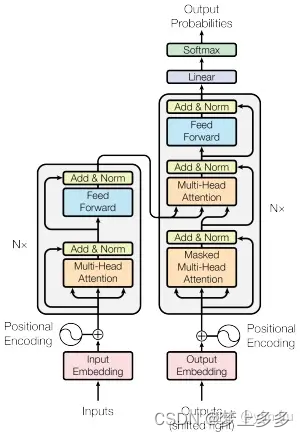
https://zhuanlan.zhihu.com/p/48508221
1 ↩︎
















 5148
5148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











