







自然语言处理笔记总目录
注意力机制:
- 它需要三个指定的输入Q(query),K(key),V(value),然后通过计算公式得到注意力的结果,这个结果代表query在key和value作用下的注意力表示。当输入的Q=K=V时,称作自注意力计算规则
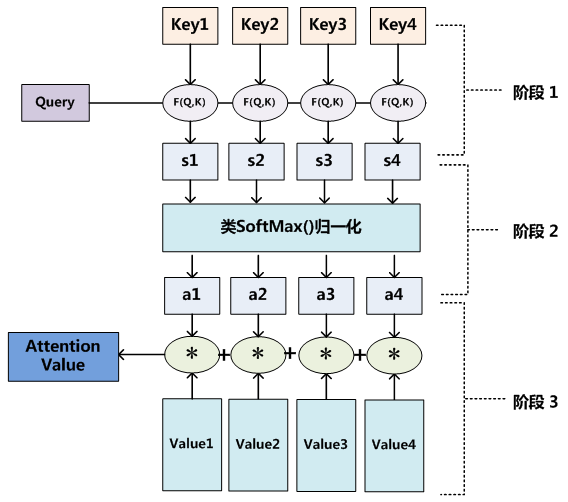
常见的注意力计算规则:
- 将Q、K进行纵轴拼接,做一次线性变化,再使用softmax处理获得结果最后与V做张量乘法
Attention ( Q , K , V ) = Softmax ( Linear ( [ Q , K ] ) ) ⋅ V \text { Attention }(Q, K, V)=\operatorname{Softmax}(\text { Linear }([Q, K])) \cdot V Attention (Q,K,V)=Softmax( Linear ([Q,K]))⋅V - 将Q、K进行纵轴拼接,做一次线性变化后再使用tanh函数激活,然后再进行内部求和,最后使用softmax处理获得结果再与V做张量乘法
Attention ( Q , K , V ) = Softmax ( sum ( tanh ( Linear ( [ Q , K ] ) ) ) ) ⋅ V \text { Attention }(Q, K, V)=\operatorname{Softmax}(\operatorname{sum}(\tanh (\operatorname{Linear}([Q, K])))) \cdot V Attention (Q,K,V)=Softmax(sum(tanh(Linear([Q,K]))))⋅V - 将Q与K的转置做点积运算,然后除以一个缩放系数,再使用softmax处理获得结果最后与V做张量乘法
Attention ( Q , K , V ) = Softmax ( Q ⋅ K T d k ) ⋅ V \operatorname{Attention}(Q, K, V)=\operatorname{Softmax}\left(\frac{Q \cdot K^{T}}{\sqrt{d_{k}}}\right) \cdot V Attention(Q,K,V)=Softmax(dkQ⋅KT)⋅V
首先看一下bmm算法的规则,接下来要用到:
input = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(input, mat2)
res.size()
注意力机制的实现:
- 第一步:根据注意力计算规则,对Q,K,V进行相应的计算.
- 第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接,如果是转置点积,一般是自注意力,Q与V相同,则不需要进行与Q的拼接.
- 第三步:最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步的结果上做一个线性变换,得到最终对Q的注意力表示
import torch
from torch import nn
import torch.nn.functional as F
class Attn(nn.Module):
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(Attn, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 初始化注意力机制第一步
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 初始化注意力机制第三步
self.attn_combine = nn.Linear(self.query_size + self.value_size2, self.output_size)
def forward(self, Q, K, V):
# 第一步,我们将采用上述第一种计算规则
# 先进性QK的拼接以及线性变换,再经过softmax处理获得结果
# 这里QKV都是三维张量
attn_weights = F.softmax(self.attn(torch.cat((Q[0], K[0]), 1)), dim=1)
# 第一步的后半部分,将得到的权重矩阵与V做矩阵乘法计算
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
# 第二步,将Q与第一步的结果再进行拼接
output = torch.cat((Q[0], attn_applied[0]), 1)
# 第三步,得到输出
output = self.attn_combine(output).unsqueeze(0)
return output, attn_weights
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 64
attn = Attn(query_size, key_size, value_size1, value_size2, output_size)
Q = torch.randn(1, 1, query_size)
K = torch.randn(1, 1, key_size)
V = torch.randn(1, value_size1, value_size2)
out = attn(Q, K, V)
print(out[0])
print(out[0].shape)
print(out[1])
print(out[1].shape)
Out:
tensor([[[ 0.1920, -0.0226, 0.6748, 0.0918, -0.4823, -0.6283, -0.0208,
-0.1392, 0.2600, -0.4108, -0.0454, 0.4292, 0.2689, 0.0253,
0.0899, -0.0454, -0.5245, 0.2048, 0.4343, -0.1976, 0.3197,
-0.1002, 0.3520, 0.5735, 0.0335, 0.1373, 0.5763, -0.2970,
0.1358, -0.5142, 0.3692, -0.2756, 0.6040, -0.3971, 0.0294,
-0.4729, 0.2117, 0.0017, -0.0073, -0.1308, 0.4360, -0.1295,
-0.2908, 0.0267, -0.2415, -0.4326, -0.2029, -0.3610, -0.1869,
0.2833, -0.0548, 0.5320, 0.0839, 0.2886, -0.0132, -0.1591,
0.1140, 0.1069, 0.2512, 0.2884, 0.4276, -0.3709, 0.3110,
0.2892]]], grad_fn=<UnsqueezeBackward0>)
torch.Size([1, 1, 64])
tensor([[0.0151, 0.0225, 0.0306, 0.0240, 0.0299, 0.0142, 0.0559, 0.0327, 0.0627,
0.0434, 0.0191, 0.0405, 0.0154, 0.0084, 0.0474, 0.0174, 0.0192, 0.0526,
0.0196, 0.0143, 0.0505, 0.0270, 0.0154, 0.0323, 0.0478, 0.0277, 0.0887,
0.0137, 0.0155, 0.0540, 0.0152, 0.0273]], grad_fn=<SoftmaxBackward0>)
torch.Size([1, 32])
这里推荐一篇文章:深度学习中的注意力模型(2017版)

















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











