







摘要
构建逼真且可动的 avatar仍然需要多视角或单目自旋转视频,并且大多数方法缺乏对姿势和表情的精确控制。为了突破这一限制,论文提出了从单张照片构建全身说话avatar的挑战。论文提出了一个新的流程,解决了两个关键问题:复杂的动态建模:人类在交流时表现出复杂的姿势和面部表情,需要构建一个能够捕捉全身运动的模型。泛化到新的姿势和表情:现有的方法通常依赖于训练数据,难以泛化到新的姿势和表情,尤其是在只有一张照片的情况下。为了实现无缝泛化,论文利用最新的姿态引导图像到视频扩散模型来生成不完美的视频帧作为伪标签。为了克服由不完整和嘈杂的伪视频引起的动态建模挑战,论文引入了一种紧密耦合的3DGS-mesh混合avatar表示,并应用了几种关键的正则化来减轻伪标签引起的不一致性。在各种各样的主体上进行的广泛实验表明,该方法能够仅凭一张照片就创建出一个逼真、精确可动且表情丰富的全身说话avatar。
1.引言
构建逼真且可动的全身说话 avatar具有巨大潜力,但现有方法依赖大量视频数据,且难以捕捉细节和控制表情。主要挑战是动态建模,需要捕捉全身的运动,包括身体、手和面部表情;泛化,需要使avatar能够适应新的姿势和表情,即使这些姿势和表情在训练数据中从未出现过。为了解决复杂动态建模的挑战,我们利用单输入图像和不完美的伪标签来训练混合mesh-3DGS化身表示,并受到几个精心设计的正则化的约束。单一输入图像为身体化身提供了准确的(尽管不完整)外观,而伪视频提供了不完美但更完整的视觉线索。对于伪视频标签,我们没有使用逐像素损失,而是使用基于感知的损失项[6,这有助于实现合理的外观建模,同时减轻伪标签中的不对齐。为了进一步缓解伪标签带来的不一致性,我们采用了紧密耦合的mesh-3DGS混合头像表示。通过在变形体网格上引入拉普拉斯平滑和法向一致性正则化,保证了用于渲染的三维高斯网格结构具有良好的约束。最后,我们使用手势和头部视频伪标签来监督化身的表示,从而创建逼真的、精确的动画化和富有表现力的全身化身。总之,我们的贡献包括以下几个方面:
(1)我们引入了一个新的方法,克服了从单个图像构建一个全身表达的说话化身的关键挑战。
(2)我们的扩散引导策略有效地从不完美的扩散输出中提取有价值的知识,并将其与输入图像中的有限信息相结合,从而实现对说话化身的完整建模。
(3)我们精心设计的3DGS-mesh耦合化身表示,以及必要的正则化技术,促进了不同主题的准确建模,并稳定了优化过程。
2.相关工作
相关研究部分回顾了与 One Shot, One Talk相关的三个主要研究领域:基于3D高斯的人体建模、从少量图像重建avatar和姿态引导的人体视频扩散。
2.1基于 3D高斯的人体建模
3D高斯体绘制 是场景重建和新视角合成(NVS)的最新方法,提供superior渲染速度和视觉质量。多视角视频和单目视频 的人体高斯体绘制方法展示了优异的性能。现有方法主要关注静态场景,忽略了动态人体运动,限制了捕捉人体动态的能力。
2.2 从少量图像重建 avatar
一些工作采用 3D GAN反演进行单张图像人体重建,但难以保留个人细节和泛化。PIFu及其后续工作引入像素对齐特征和神经场进行基于图像的人体重建。另一种方法利用扩散先验来填补缺失的细节,例如训练以人为中心的扩散模型使用新视角扩散结果进行额外的监督 ,以及采用分数蒸馏采样(SDS)从2D先验生成3D avatar。这些方法主要关注静态场景,忽略了动态人体运动,限制了捕捉人体动态的能力。
2.3姿态引导的人体视频扩散
姿态引导的人体视频扩散模直接从参考图像和姿势序列生成动画视频,绕过传统的 3D重建和渲染过程。这些模型的成功取决于训练数据的质量、模型设计和姿势引导。尽管它们具有优势,但这些2D模型仍然面临一些挑战,例如图像扭曲、身份变化和姿势错位,因为它们缺乏3D理解。为了解决这些问题,我们利用经过优化的avatar表示和精心设计的约束,提高生成动画的一致性和自然度。
3.方法
给定目标人物的单一图像,我们的目标是重建一个完全继承身份并实现自然动画的3D说话化身。为了解决来自不完美伪视频的复杂动态建模的挑战,我们采用了紧密耦合的3DGS-mesh混合化身表示(第3.1节)。为了很好地推广到不同的手势和面部动作,我们生成了由各种动作序列驱动的目标人的不完美视频序列(第3.2节)。最后,我们引入了精心设计的约束和损失项,以有效地训练噪声视频的表示(第3.3节)。整个方法如图2所示
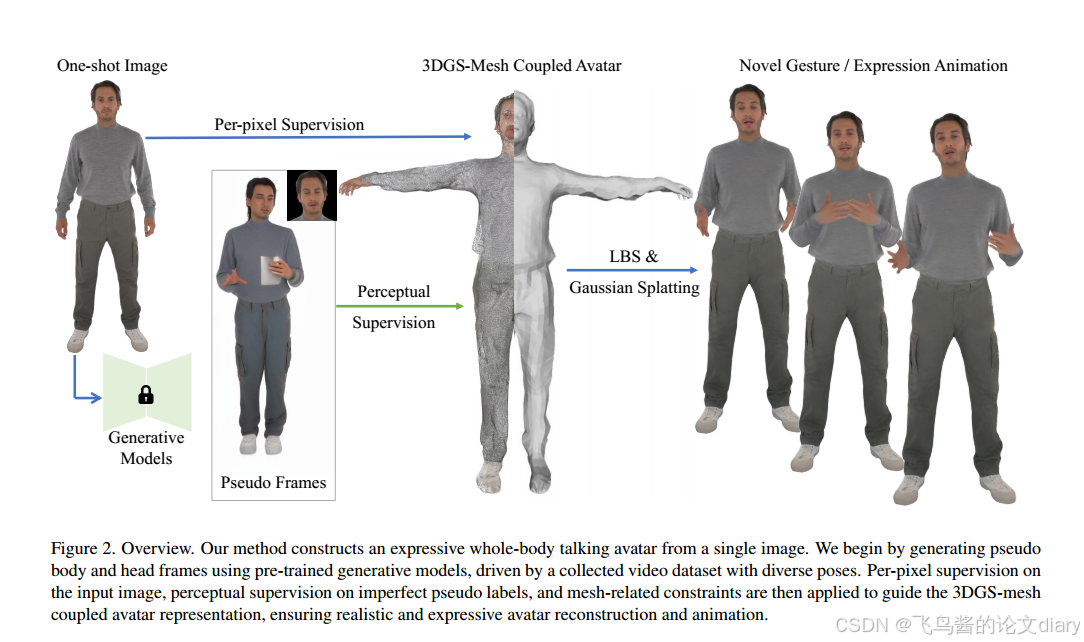
3.1耦合的3DGS-Mesh化身
将3DGS场与SMPL-X网格模型紧密耦合。利用UV参数化在标准网格表面上初始化3D高斯。设计了两个变形场:Gaussian变形场:代表传统的Gaussian变形。Mesh变形场:代表关键网格变形。通过鼓励Gaussian变形场与Mesh变形场的重心对齐,间接影响Gaussian变形。这种方法允许有效地处理复杂区域,同时确保网格的几何完整性和细节。
3.2伪标签生成
为了使avatar能够泛化到新的姿势和表情,One Shot, One Talk利用预训练的扩散模型生成目标人物执行不同姿势和表情的伪视频序列作为训练数据。
3.2.1.生成伪身体帧
从TED手势数据集中收集一组SMPL-X姿势序列作为输入。使用MimicMotion模型根据输入图像和姿势序列生成伪身体帧。对生成的伪身体帧进行重新跟踪,以获得更精确的姿势参数,并克服2D扩散模型引入的错位问题。
3.2.2.生成伪头部帧:
使用Portrait4D-v2模型根据TED手势数据集中的表情序列生成伪头部帧。
3.2.3优势:
伪标签为avatar提供了更丰富的运动和表情信息,使其能够泛化到新的姿势和表情。
重新跟踪步骤确保了伪标签的准确性,并避免了纹理错误和细节丢失。
3.3目标函数
为了有效地从单张照片和不完美的伪标签中提取信息,One Shot, One Talk引入了一系列精心设计的约束和损失函数,包括:
3.3.1网格相关约束(Mesh-related Constraints):
法线一致性损失 (Lnormal):确保变形后网格表面的法线一致性。掩码损失(LM):衡量真实掩码与变形后网格渲染掩码之间的差异。网格-高斯一致性损失(LMGC):鼓励Gaussian变形场与Mesh变形场的重心对齐。拉普拉斯平滑损失(Llap):对变形后的Gaussian进行拉普拉斯平滑,并保持其缩放和RGB值。
3.3.2基于感知的伪标签指导(Perceptual Supervision of Pseudo-Labels)
使用 LPIPS感知损失来指导伪标签的学习,并保留输入图像的细节和身份信息。
3.3.3输入图像的逐像素监督(Per-pixel Supervision of the Input Image)
使用 L1损失、SSIM损失和掩码损失来确保输入图像与生成avatar之间的纹理一致性。
3.3.4优势:
通过网格相关约束,确保了网格的几何完整性和细节。
通过基于感知的伪标签指导,避免了伪标签中的纹理错误和身份变化。
通过输入图像的逐像素监督,确保了输入图像与生成 avatar之间的纹理一致性。
4.实验
4.1定性比较
图3和图4给出了我们的方法与其他代表性方法之间的定性比较。对于图3,我们使用不同身份的位姿作为驱动信号。在图4中,我们使用具有相应视频数据的受试者,比较了这些方法在自驱动姿态再现任务中的性能.


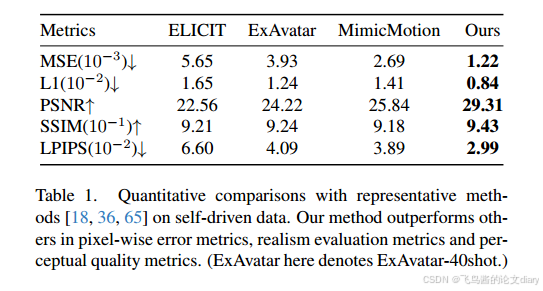
4.2定量比较。
表1给出了我们的模型与其他方法的定量比较。尽管单镜头图像动画任务通常缺乏用于定量比较的严格测试集,但我们对自驱动任务进行了评估,并使用五个常用指标进行比较:均方误差(MSE)、L1距离、PSNR、SSIM和LPIPS。我们的方法在这些指标上优于所有其他方法,在结果中表现出卓越的真实感和3D一致性。然而,我们认为这些指标并不能完全捕捉方法的质量或能力,特别是对于单镜头图像动画任务。我们鼓励读者参考我们方法的视频结果,以获得更全面和客观的评价。
5.结论
在本文中,我们介绍了一种新的方法,用于从单个图像中创建具有表现力的说话化身。我们提出了一个耦合的3DGS-Mesh化身表示,结合了几个关键约束和一个精心设计的混合学习框架,该框架结合了来自输入图像和伪帧的信息。实验结果表明,我们的方法优于现有的技术,我们的一次性头像甚至超过了需要视频输入的最先进的方法。考虑到其结构简单,能够生成生动逼真的动画,我们的方法在各个领域的实际应用中显示出巨大的潜力。
论文地址::https://ustc3dv.github.io/OneShotOneTalk/

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









