






该内容仅适用于固定表格模板,如表格形式不同可自行修改代码以适用。
一、概述
在使用Origin处理压力数据前通常需要把示波器中导出的以 .CSV 为后缀的数据文件汇总到Excel表中(或者在 .CSV 文件中直接复制粘贴到Origin中),其间还要依据点火的起始点位进行数据的选取。在多工况、多次重复实验的情况下,工作量是十分庞大的,那么我们就需要一些自动化的手段来提高数据处理的效率,把更多的实验放在分析调研上。
笔者根据自己的工作内容并结合网络上现有的解决办法编写了两组代码,依次实现以下功能:
1、将 .CSV 文件批量转换为 .xlsx 文件以便后续使用。
2、根据数据信息表中的数据信息将单组数据表(转换后的 .xlsx 文件)中的数据进行选择,将其汇总到最终汇总表中。
注:每个部分的代码在 “运行” 内。
二、 .CSV 文件的转换
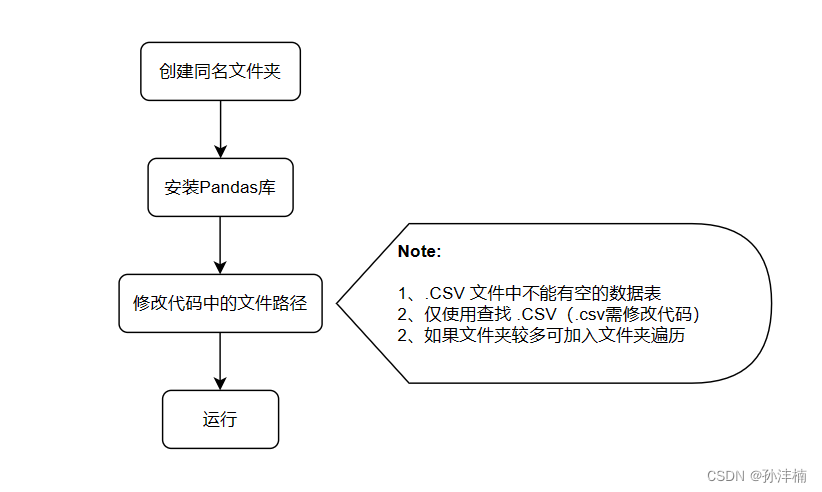
1、创建与 .CSV 文件同名文件夹
由于后续要使用信息表中的内容,所以笔者在这里设置 .xlsx 文件所在文件夹与示波器导出数据文件夹同名,如果信息表是在此步骤之后编制的,可以按自己喜欢的方式去命名。
例如:
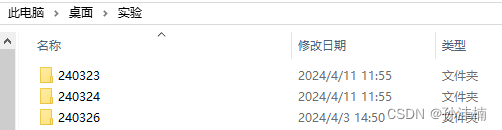
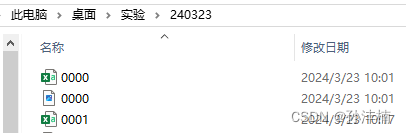
图1. .CSV 所在文件夹
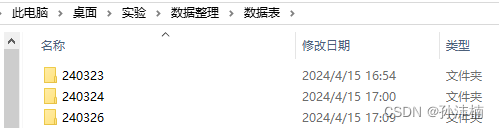
图2. .xlsx 所在文件夹
2、安装 Pandas 库
详见:Pandas 安装 | 菜鸟教程 (runoob.com)
3、修改代码中的文件路径
# 指定要查找的目录和保存的目录
search_directory = r'C:\Users\ASUS\Desktop\实验\240331'
save_directory = r'C:\Users\ASUS\Desktop\实验\数据整理\数据表\240331'4、运行
import os
import pandas as pd
def convert_csv_to_excel(search_directory, save_directory):
# 获取指定目录下所有的CSV文件
csv_files = [file for file in os.listdir(search_directory) if file.lower().endswith('.csv')]
# 遍历每个CSV文件并转换为Excel文件
for csv_file in csv_files:
# 构建CSV文件的完整路径
csv_path = os.path.join(search_directory, csv_file)
# 读取CSV文件,并跳过前16行
df = pd.read_csv(csv_path, skiprows=16, header=None)
# 构建要保存的Excel文件的完整路径,将文件名中的.csv替换为.xlsx
excel_file = os.path.splitext(csv_file)[0] + '.xlsx'
excel_path = os.path.join(save_directory, excel_file)
# 保存为Excel文件
df.to_excel(excel_path, index=False)
# 指定要查找的目录和保存的目录
search_directory = r'C:\Users\ASUS\Desktop\实验\240331'
save_directory = r'C:\Users\ASUS\Desktop\实验\数据整理\数据表\240331'
# 执行转换
convert_csv_to_excel(search_directory, save_directory)
print("转换完成")
图3. 运行结束后窗口显示
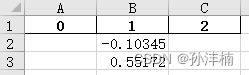
图4. 转换后的表格形式
5、说明
1)笔者所用示波器导出的文件格式为大写的 .CSV 所以在转换后缀时先进行了小写处理。
2)由于导出的 .CSV 文件中有效数据从第17行开始,为了后续处理,笔者在这里直接跳过了前16行。使用者可根据实际情况进行修改。
# 读取CSV文件,并跳过前16行
df = pd.read_csv(csv_path, skiprows=16, header=None)
图5. 第2列从第17行开始为压力数据
3).CSV 数据表中的压力数据(如下图)不能为空,如果为空则会报错。如果压力数据为空,请随机加个数值以保证程序正常运行。
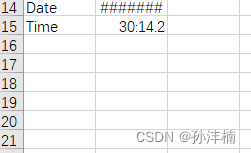
图6. 压力数据为空的文件
三、数据的选择与汇总
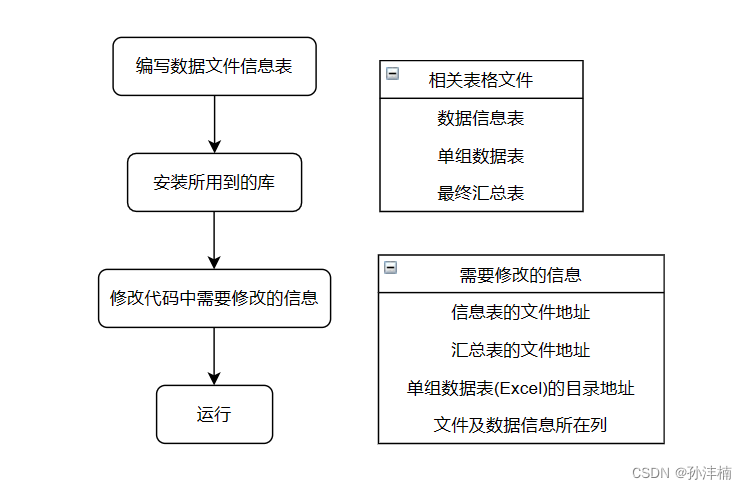
1、编写数据文件信息表
数据信息表格式如下:

![]()
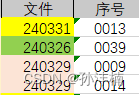
图7. 文件信息表格式
接下来需要创建一个数据汇总表,该汇总表的 Sheet 要与数据信息表的 Sheet 一致。并且汇总表内尽量不要写任何内容。

图8. 数据汇总表 Sheets
2、安装 Openpyxl 库
打开CMD,输入:
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple/
(来源:清华大学 TUNA 协会)
3、修改代码中的信息
1)修改汇总文件、信息文件和单组数据文件的地址
# 载入汇总文件表和信息文件表
wb_sum = load_workbook(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_info = load_workbook(r"C:\Users\ASUS\Desktop\实验\数据整理\data_info.xlsx")
# 单组数据文件所在目录
data_path = os.path.join(r"C:\Users\ASUS\Desktop\实验\数据整理\数据表", str(folder_name), str(data_name+".xlsx"))
# 汇总表的保存地址
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")2)修改数据信息所在列
# B为当量比所在列
column = current_sheet["B"]
# 提取文件列、序号列和修正点位列的数据
folder_column = current_sheet["D"] # 文件名列
data_num_column = current_sheet["E"] # 序号列
start_row_column = current_sheet["K"] # 修正点位列3)说明
a. 该程序没有自动创建汇总表,需要手动创建并修改 Sheet。
b. 在所提取的单元格值不能是公式,否则就会报错,需要修改为数值。
c. 单组数据表的命名要和信息表中的序号一致,如 0000 对应 0000.xlsx。
d. 数据量较多时会耗费大量的时间,建议使用者设置提取数据的数量,程序中默认提取所有数据。可以选择下面两种方式设置数据量。
# 方法一:
end_row = start_row + 50000 #可设置固定截取单元格数量
for row in data_sheet.iter_rows(min_row=start_row, max_row=end_row , min_col=2, max_col=2): #可设置要提取的数据量
# 方法二
for row in data_sheet.iter_rows(min_row=start_row, max_row=150000 , min_col=2, max_col=2): #可添加设置最大选择行max_rowe. 在选择截取数据方面,该程序在将修正后点位设为起始行时会有一行的误差。如若追求准确可将下面代码中 “1” 修改为 “2”。(也可自行调试修改为其他数值)
# 获取起始行信息,即修正后的起始点+1(因为转换后的单组数据表含有表头)
start_row = int(start_row_cell.value) + 1f. 使用者在调试后,如可以正常运行和结束(调试时建议设置少量单元格来节省时间),需要删除或注释掉下列代码以节省时间。
# 该行尽量删除或注释
print("Data Column:", data_column)
#该行必须删除或注释,否则运行效率会大大降低
print(f"Writing to Row {row_idx}, Column {target_col_idx}, Value: {source_cell}")
# 删除中间的那一行
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")4、运行
import os
from openpyxl import Workbook, load_workbook
# 载入汇总文件表和信息文件表
wb_sum = load_workbook(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_info = load_workbook(r"C:\Users\ASUS\Desktop\实验\数据整理\data_info.xlsx")
# 遍历每个信息表sheet(每个sheet代表一个工况变量)
for ws_info in wb_info.sheetnames:
# 当前sheet
current_sheet = wb_info[ws_info]
# 检查汇总表格中是否存在与信息表格中相同名称的sheet,如果不存在则创建
if ws_info not in wb_sum.sheetnames:
wb_sum.create_sheet(title = ws_info)
# 选择汇总表格中对应的sheet
target_sheet = wb_sum[ws_info]
# B为当量比所在列
column = current_sheet["B"]
# 创建一个空列表来存储当量比工况
numbers = []
# 遍历列中的每个单元格,并将当量比工况添加到列表中
for cell in column:
if cell.value is not None and isinstance(cell.value, (int, float)):
numbers.append(cell.value)
# 将所有当量比工况分别写入汇总表的第一行单元格中,并在重复的工况后添加编号以区分
for idx, number in enumerate(numbers, start=1):
if numbers.count(number) > 1: # 如果工况重复
count = 1
for i in range(idx-1):
if numbers[i] == number:
count += 1
# 给重复工况编号
numbered_number = f"{number}_{count}"
else:
numbered_number = str(number)
# 写入带有编号的当量比工况到汇总表的第一行单元格中作为表头
target_sheet.cell(row=1, column=idx, value=numbered_number)
# 提取文件列、序号列和修正点位列的数据
folder_column = current_sheet["D"] # 文件名列
data_num_column = current_sheet["E"] # 序号列
start_row_column = current_sheet["K"] # 修正点位列
col_idx = 0 # 后面要用到的写入data_sum的初始列索引的初始化
# 遍历文件列、序号列和修正点位列的数据(跳过表头)
for folder_cell, data_cell, start_row_cell in zip(folder_column[1:], data_num_column[1:], start_row_column[1:]):
folder_name = folder_cell.value
data_name = data_cell.value
if data_name is None:
break
data_path = os.path.join(r"C:\Users\ASUS\Desktop\实验\数据整理\数据表", str(folder_name), str(data_name+".xlsx"))
print("Data Path:", data_path)
data_wb = load_workbook(data_path, data_only=True)
# 提取单组数据表中的压力数据
data_sheet = data_wb.active
print(data_sheet.title)
start_row = int(start_row_cell.value) + 1 # 获取起始行信息,即修正后的起始点+1(因为转换后的单组数据表含有表头)
print("Start Row:", start_row)
data_column = []
# end_row = start_row + 50000 #可设置固定截取单元格数量
# for row in data_sheet.iter_rows(min_row=start_row, max_row=150000 , min_col=2, max_col=2): #可添加设置最大选择行max_row
for row in data_sheet.iter_rows(min_row=start_row, min_col=2, max_col=2):
# 如果该行不为空且第二列有数值,则将其添加到 data_column 中
if row and row[0].value is not None:
data_column.append(row[0].value)
print("Data Column:", data_column)
row_idx = 1 # 初始行索引为第一行
col_idx += 1
# 遍历数据列中的每个单元格,并写入到目标表格中对应的位置
for row_idx, source_cell in enumerate(data_column, start=2):
# 计算要写入的列索引,确保不超出范围
target_col_idx = min(col_idx, target_sheet.max_column)
# 写入数据到汇总表格的对应位置
target_cell = target_sheet.cell(row=row_idx, column=target_col_idx, value=source_cell)
row_idx += 1
print(f"Writing to Row {row_idx}, Column {target_col_idx}, Value: {source_cell}")
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
wb_sum.save(r"C:\Users\ASUS\Desktop\实验\数据整理\data_sum.xlsx")
由于笔者是初学者,能力有限,程序内容需要仔细修改才能适用其他工作内容,并且程序本身不够简洁也可能有错误之处,欢迎使用者批评指正。

















 5576
5576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









