






PARATERA 并行超算从零开始学习及使用-记录(手把手案例)
文章目录
一、PARATERA 并行超算安装和登录
参考官网简介(https://www.paratera.com/)
不打算参考使用终端命令进行作业交互的同学可以直接跳转到: 三、
并行超算 Linux 客户端下载
下载链接(https://www.paratera.com/fuwu/rjxz/)
本人下载的是 3.6.5 版本,注意:Linux 的客户端下载并安装好后是没有客户端页面的,后续的作业提交等需要在终端输入命令行进行操作。
如果希望进入页面进行操作可以点击这个链接(https://cloud.paratera.com/)。
下载好 papp_cloud-3.6.5 的压缩包之后,解压。然后按照文件夹下面的 papp_cloud使用手册.pdf 里面的安装部分进行安操作,即可安装成功。
1.并行超算 Linux 客户端登录
在 papp_cloud使用手册.pdf 里面登录命令行为 papp_cloud login -u demo@paratera.com -p。
例如
并行超算网格云桌面登录帐号为:aaaaaaaaaa@abc.cn
并行超算网格云桌面登录密码为:bbb999bbb
那么在终端里面输入:
# 首先输入帐号对应的命令行
abc@be-JiguangPro:~$ papp_cloud login -u aaaaaaaaaa@abc.cn -p
# 此时会跳出 Password: 让你输入密码,但时输入密码时,密码不可见,因此建议 Ctrl+Shift+v 进行粘贴
Password:
# 密码正确后弹出 login successful! 即代表登录成功
login successful!
命令 papp_cloud acct 是查询当前有多少个超算帐号可供使用

命令 papp_cloud lsc 命令是查看⽀持的超算中⼼,如下图所示:
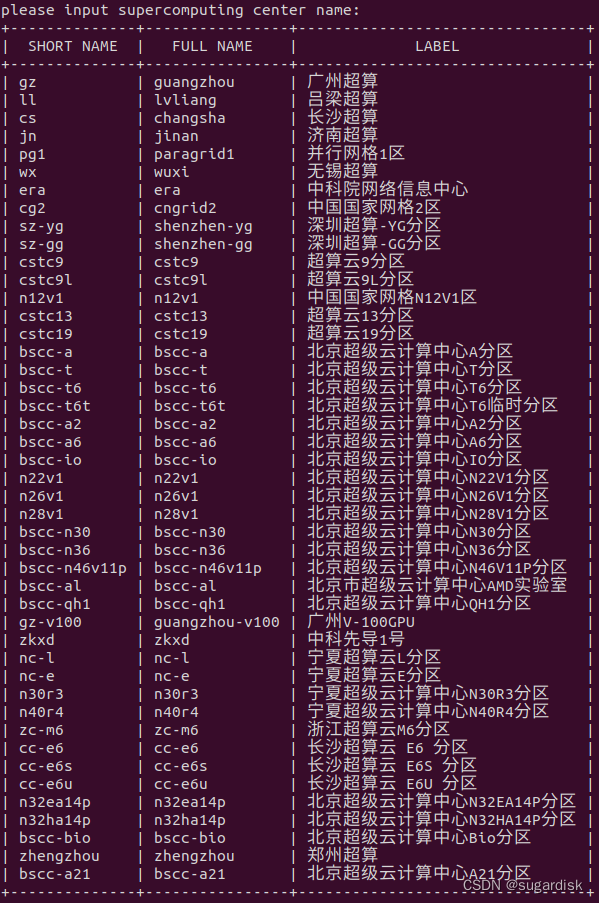
2.ssh 登录超算
(还有别的,例如 Putty、XShell,登录方式会有差异,但是不难)
后面在使用超算的时候需要进行登录。 papp_cloud使用手册.pdf 里面提供了 ssh 登录超算和 sftp 登录超算的模板,以 ssh 登录超算为例。
papp_cloud ssh paratera@gz
以 @ 为分界线,前面 paratera 部分为前面 papp_cloud acct 查到的内容里面的 ACCOUNT NAME,即超算帐号。后面 gz 部分为 SCC SHORT。例如:
超算帐号:aaaa1111aa
papp_cloud acct 查询的 LABEL:并行网格1区
那么输入为:
papp_cloud ssh aaaa1111aa@pg1
二、连接并登录超算后可能会有两种显示
1.来进行编辑编译工作,不能运行作业的情况
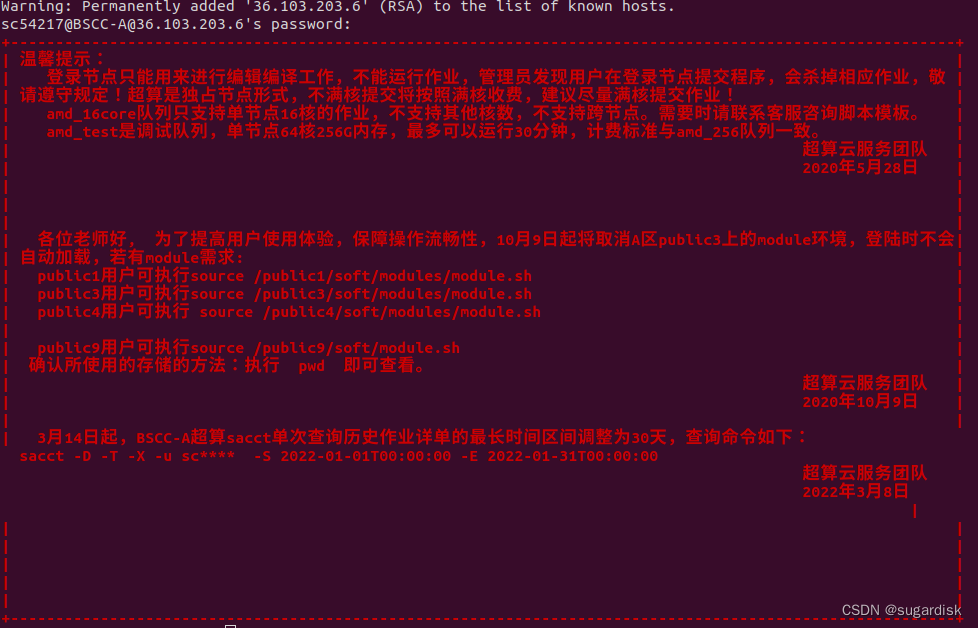
此时如果想要加载模块,那么首先需要确定着各超算帐号属于用户多少。使用命令 pwd,发现属于 public3 用户,那么可以执行下面对应的命令加载模块

之后就可以使用别的 module 命令。
2.能运行作业的情况

此时一般不再需要确定是哪个用户
可以使用 module avail 确定自己需要的模块,然后通过 module load 进行加载。如果安装的模块版本不对,可以使用 module ubload 进行卸载。(如下图所示)
下图为本人在自己超算帐号上面加载的模块,cuda/11.8 和 anaconda/2022.10,加载好 anaconda 后可以创建虚拟环境并且在虚拟环境中安装需要的库,命令与在电脑上基本一样。唯一需要注意的点,在连接好当前超算后的第一次激活虚拟环境,使用的命令为 source activate xxxxx 但时退出当前虚拟环境使用的命令为 conda deactivate。

安装需要的库可以使用命令:
pip install xxxxxxx -i https://pypi.tuna.tsinghua.edu.cn/simple
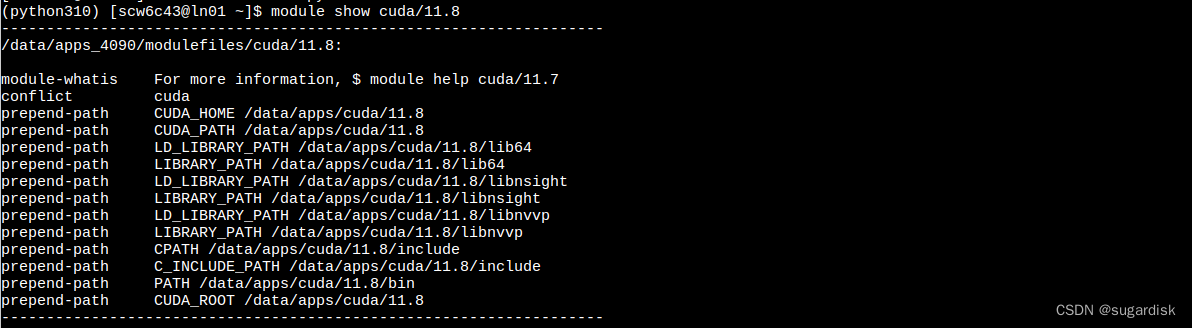
module show xxxxx 可以查看对应模块的库文件或者头文件等等的路径。(如下图所示)
module list 可以查看当前已经部署好的模块。(如下图所示)

注意:后面关于并行超算云多卡训练部分可以提前参考这个博客。
并行超算云多卡训练完整流程(从环境配置到提交任务)(https://blog.csdn.net/qq_35768355/article/details/132875292)
三、提交作业,编写简单脚本并运行
1.首先查看作业可以提交的队列,sinfo命令
通过sinfo可查询各分区节点的空闲状态。
如果输入 sinfo 命令报错:
(base) [abcabc123@ln0222 ~]$ sinfo
bash: sinfo: command not found...
Similar command is: 'info'
可能是由于 Slurm 的二进制文件目录没有添加到系统的 PATH 环境变量中
2.使用命令进行传输作业
建议写到脚本中,通过sbatch指令提交到计算节点上执行,可以避免网络波动产生的影响。以如下脚本为例。
(vim 如何编辑、保存以及退出等操作可以网上自行查询)

脚本内容如下:
#!/bin/bash
#SBATCH -N 1
#SBATCH -n 6
srun -n 6 echo "hello world"
第一行写的是解释器。
后面两行分别是**(N)指定节点数量,和(n)**指定计算的核心数量。(因为队列配额说明 6 核 CPU,因此 n = 6)
最后一行是运行作业的指令 srun。(echo 在脚本中,常用于显示消息或输出其他命令的结果)

sbatch 相关的参数解释可以查看这个链接:sbatch
以防万一可以使用 cat 命令输出一下脚本内容。

接下来就是提交脚本,这个时候需要注意,因为前面的 《N40分区简要使用指南》 提到:
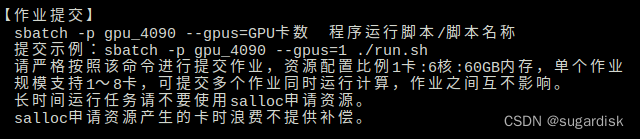
因此,按着模板命令提交作业,并显示。(如下图所示)

然后可以通过 squeue 查看作业状态。如果没有显示,一般说明作业已经运行完毕。
显示内容从左到右依次表示:
- JOBID:提交的作业号(即上面的 1061780),独一无二的
- PARTITION:提交的队列,此处 sub.sh 里面没有涉及,因为空余节点很多。
- NAME:脚本名称,可以在脚本里面单独制定作业名称。
- ST:作业状态,正常运行时显示为 R
- TIME:作业运行了多久
- NODES:作业提交的节点数量

运行完作业后会生成 .out 文件。输出这个文件,可以得到结果。
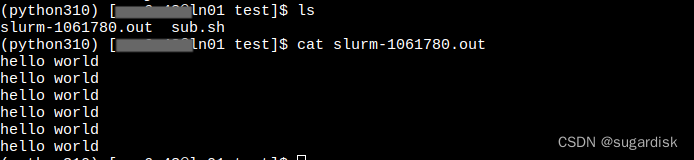
说明作业运行完成!!!
四、神经网络 FGVC-PIM 为例,上传代码和数据集到服务器并调用 GPU 训练
训练 FGVC-PIM
上传过程使用的是里面的快传功能。
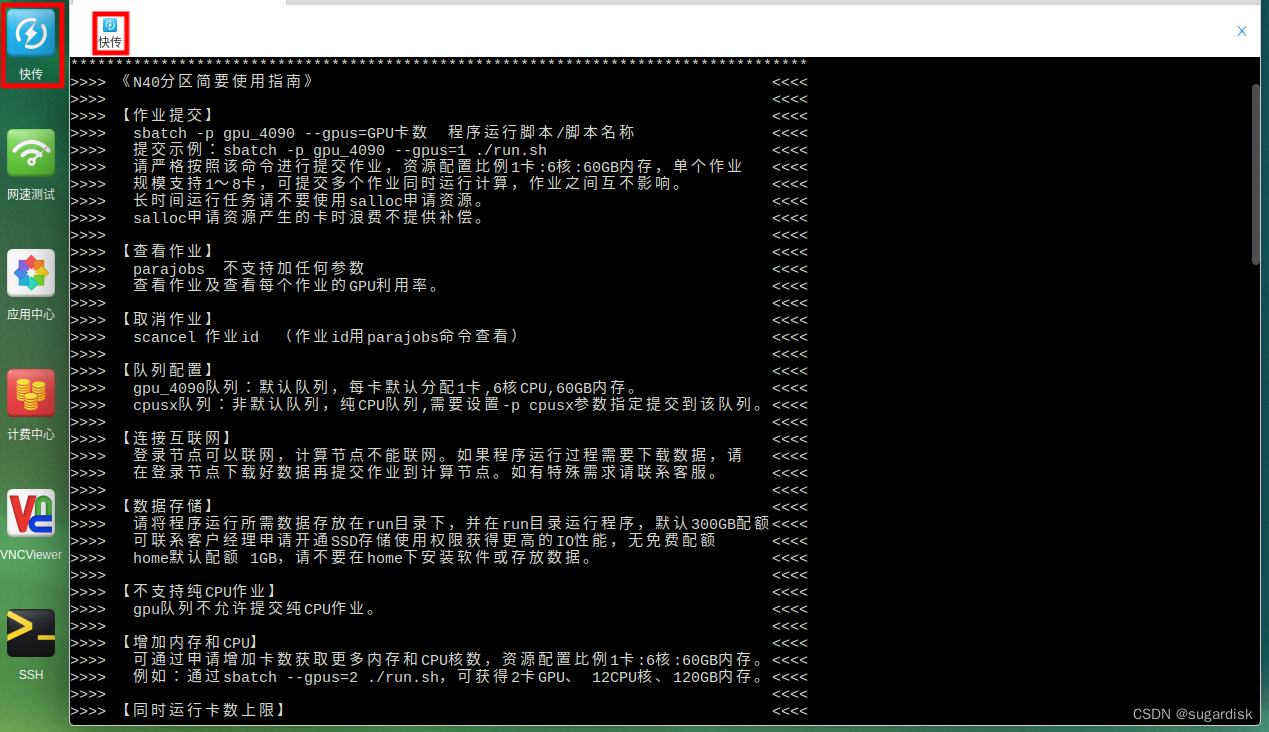
即图中红框部分,单击右边的红框则进入下图页面,需要选择要进行上传的超算帐号。

连接后进入如下界面(里面的初始文件夹是什么命名都无所谓,只是路径而已),点击进入自己需要传入数据的文件夹之后,再单击上传按键即可选择自己电脑端里面的文件进行上传。

本课题方向是物种多样性分类,需要使用超算进行多卡训练,使用的神经网络为:FGVC-PIM。
选中本地神经网络 FGVC-PIM 压缩包,然后点击 Open,即可开始上传。
然后将 FGVC-PIM 压缩包解压到指定路径下。(可以右键选择解压)(如下图所示)
(上传神经网络的时候忘记上传数据集了,其实数据集可以放在神经网络的压缩包里面一起进行上传。)
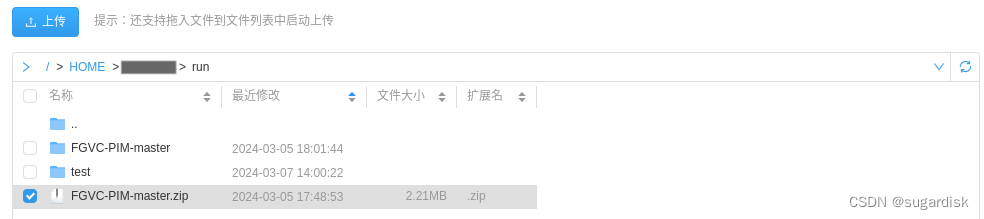
上传数据集压缩包并解压,解压后以此进入数据集,确定数据集的内容没有问题。(如下图所示)
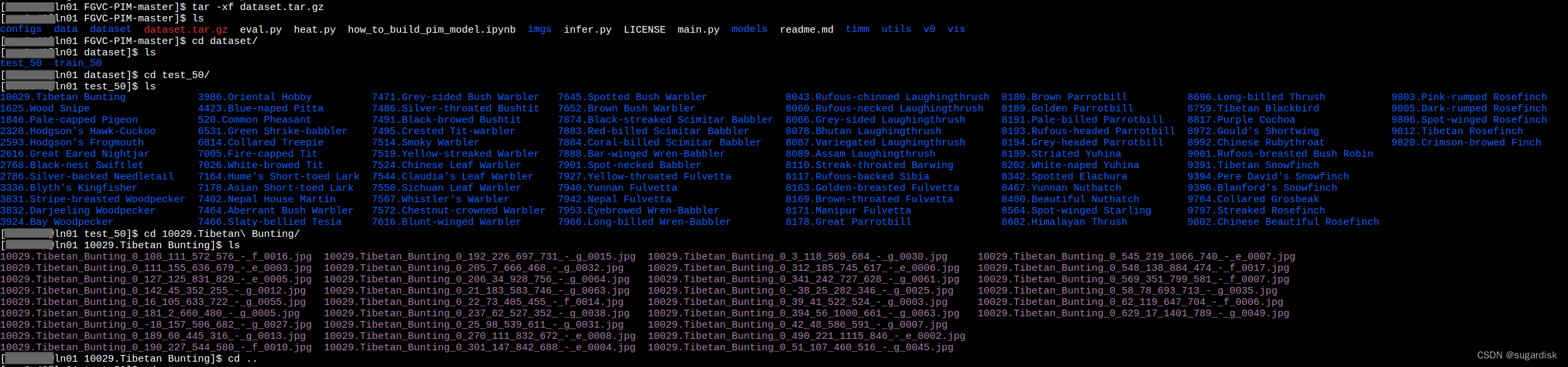
编写的运行脚本内容如下:(比较简单,没有那么多参数,后续可以自行添加)。
其中 pip 安装的是 FGVC-PIM 神经网络所需要的库。因为 github 源码里面没有对应的 requirements.txt,并且俺也懒得写了,所以电脑端确定需要安装哪些库之后,超算上直接一行命令进行安装。
#!/bin/bash
#SBATCH -N 1
#SBATCH -n 6
pip install --default-timeout=600 tqdm matplotlib opencv-python pandas wandb scikit-learn
python main.py --c ./configs/Bird.yaml
按 ESC,之后输入 :wq 保存并退出脚本编辑页面。
然后在脚本所在当前目录使用 sbatch 进行作业的上传,此处使用两张卡进行计算,命令如下
sbatch -p gpu_4090 --gpus=2 ./sub.sh
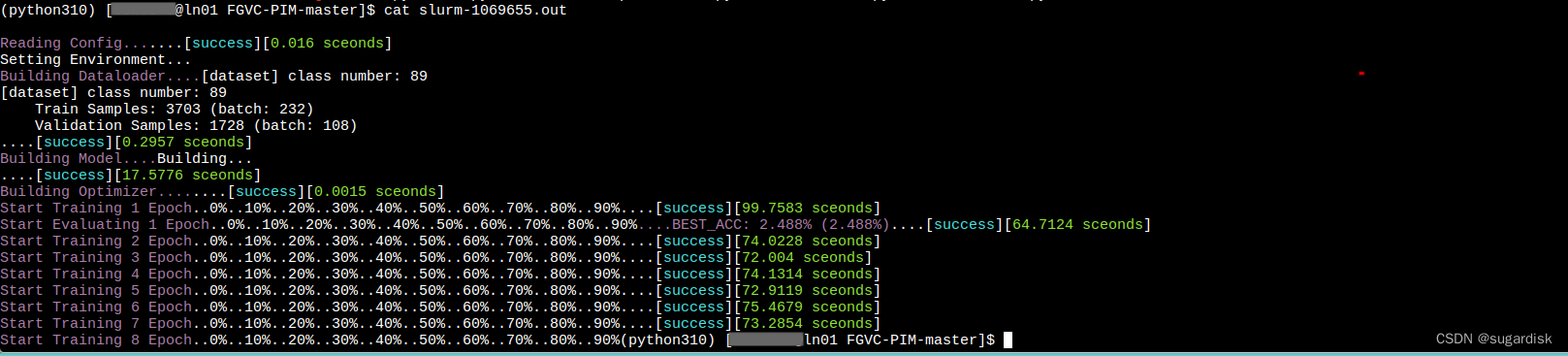
想查看当前的训练进度,可以先找到作业对应的 .out 文件。一般 .out 文件和脚本文件默认在一个文件夹下面。(如下图 slurm-1069655.out)

然后使用 cat slurm-1069655.out 即可打印出当前神经网络的训练进度。
parajobs 可以查看当前作业的 GPU 占用率。
如果想要实时查看,可以使用命令 watch parajobs。(如下图所示)每两秒刷新一次。


scancel + JOBID 可以取消当前 ID 的作业。
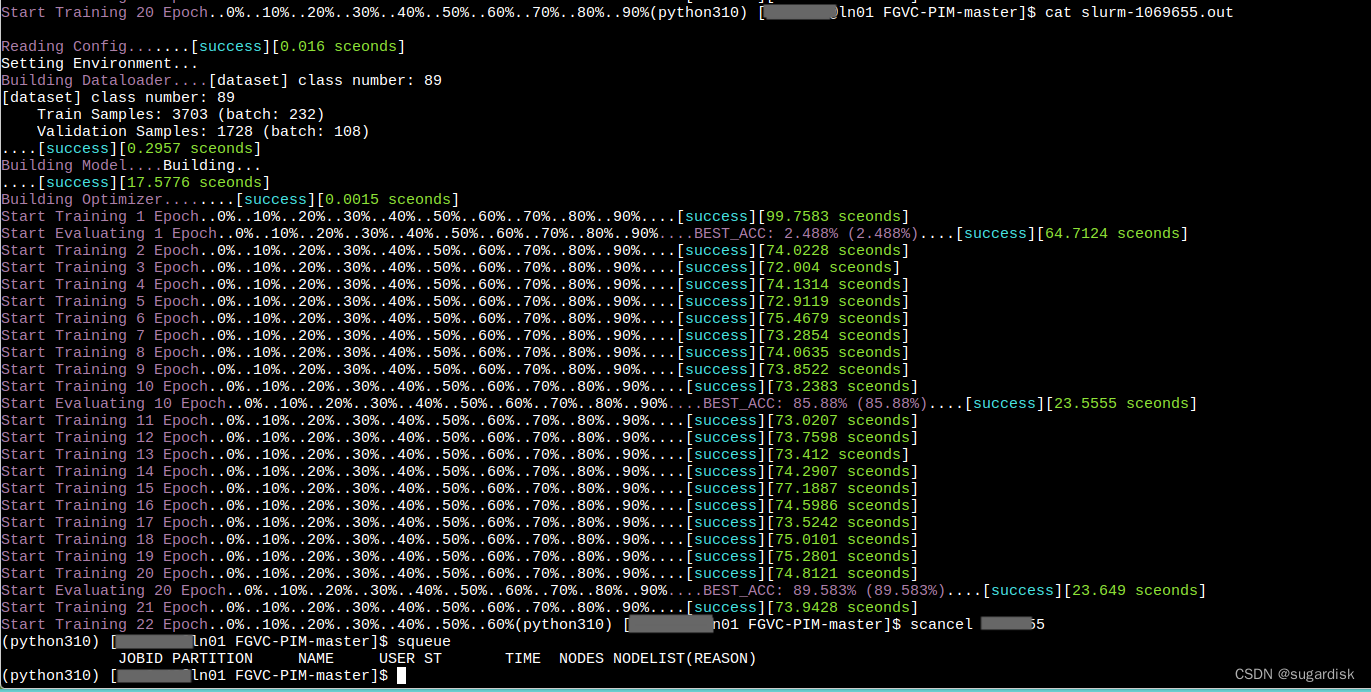
可以看到取消当前作业之后再使用 squeue 就看不到正在进行的作业了。
公共数据集
并行超算里面是有自己的公共数据集的,并且这个数据集是实时更新的。当前日期:2024.03.08数据集类型如下图所示。
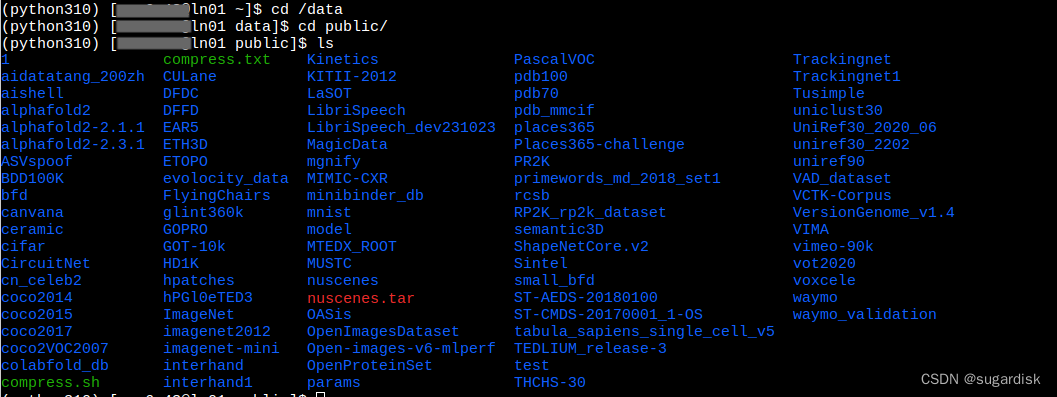
如果需要官方下载新的数据集,可以联系官方客服,帮忙将数据集下载到公共目录下面。
并行超算训练神经网络的脚本编写的一些想法
- 首先整体在超算上训练神经网络跟在自己的电脑端没有什么区别,只不过是加载一些库,显示一些节点状态的命令与电脑端不同,初学者不用慌(我也是这么慌过来的)
- 其次,便写脚本的方式除了最开始的 #!bin/bash 以及设置一些 cpu 和 gpu 的参数以外,下面的运行内容其实就是加载模块,激活虚拟环境**(source)**,pip install 安装神经网络需要用到的库,然后就是神经网络训练的命令啦(如果是 github 上面的源码,那么参考 README.md 里面训练神经网络的指令,修改里面的参数即可。)
- 需要修改 gpu 参数的话,可以查看这个网站里面的内容:https://hpc.pku.edu.cn/_book/guide/slurm/sbatch.html
- 需要注意,一些神经网络的训练是需要预训练权重文件的。以 Ubuntu 为例,这个文件一般会保存在这个 /home/xxx/.cache/torch/hub/checkpoints/ 路径下面,但是一般上传文件的时候会遗忘,然后使用超算时就会因为找不到预训练权重文件而终止,所以建议将这个预训练权重文件单独上传,然后用 cp 命令复制到 /HOME/xxx/.cache/torch/hub/checkpoints/ 路径下面。
- 最后训练结束,再次 cat slurm_xxxxxxxx.out 文件可以查看对应的权重文件保存的路径,然后通过超算的传输功能下载下来即可
AI 云主机
这个是北京超级云计算中心的网站,感兴趣的同学可以看看,了解一下云主机等相关内容。
AI 智算云















 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









