







目录
前言
本文概述:并行超算云使用流程跟华为云的modelarts或者弹性云服务器有比较大的不同,很多小白第一次使用并行超算云可能不懂具体操作流程,因此作者打算出一个完整使用并行超算云多卡训练模型的教程。
作者介绍:作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果你觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
一、官网下载客户端并登录账号
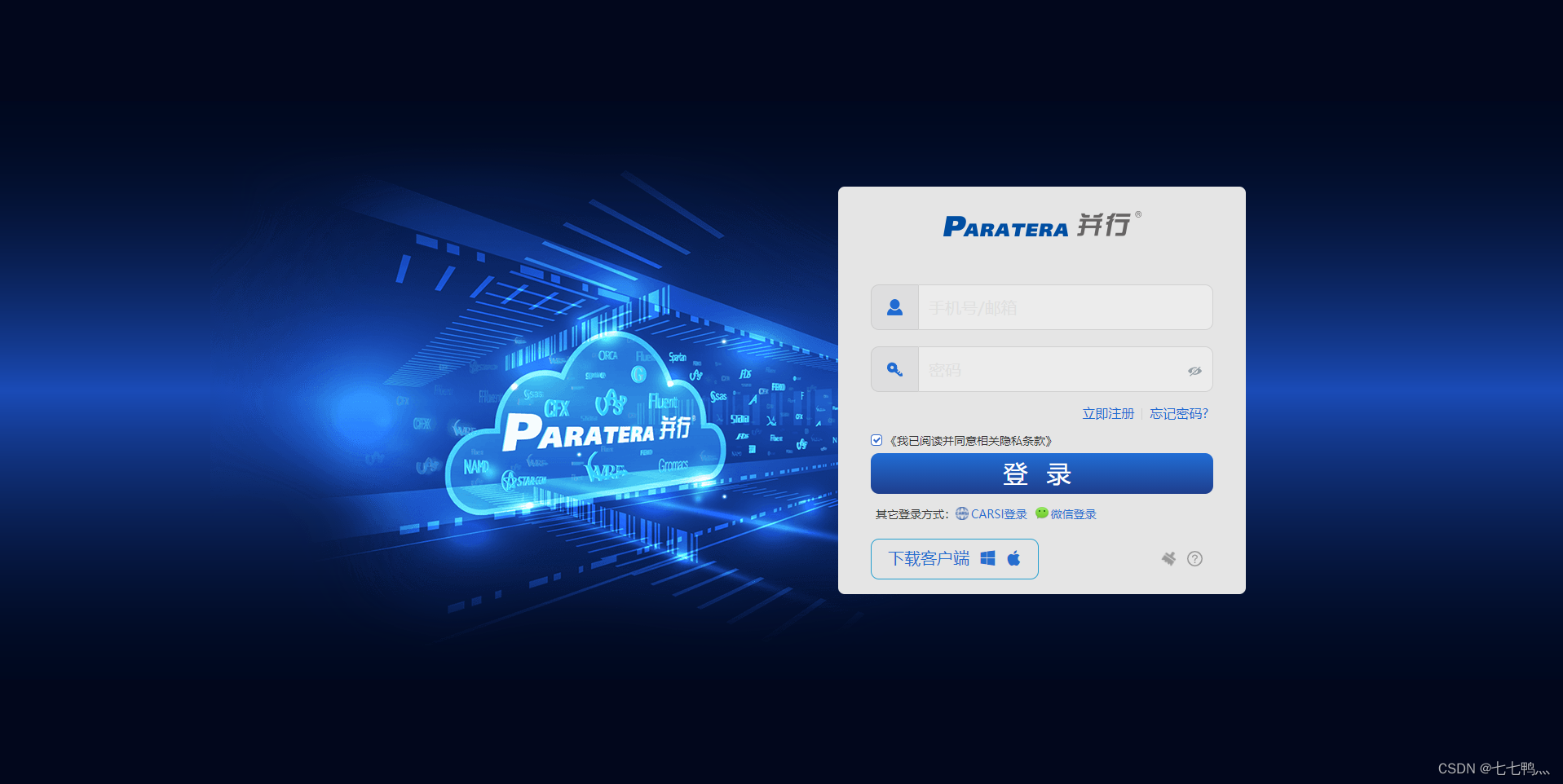
官网链接:https://cloud.paratera.com/
点击下载客户端,选择适合自己的版本下载。
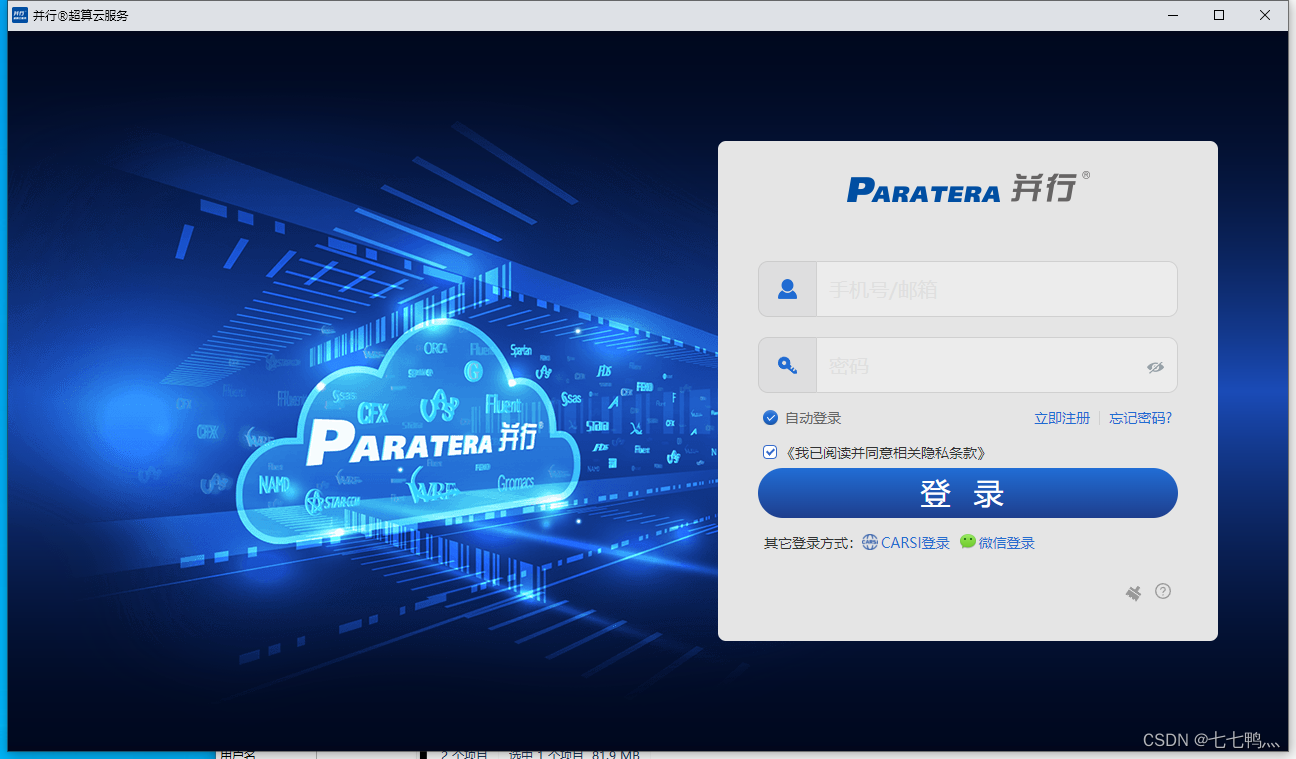
然后登录自己的账号
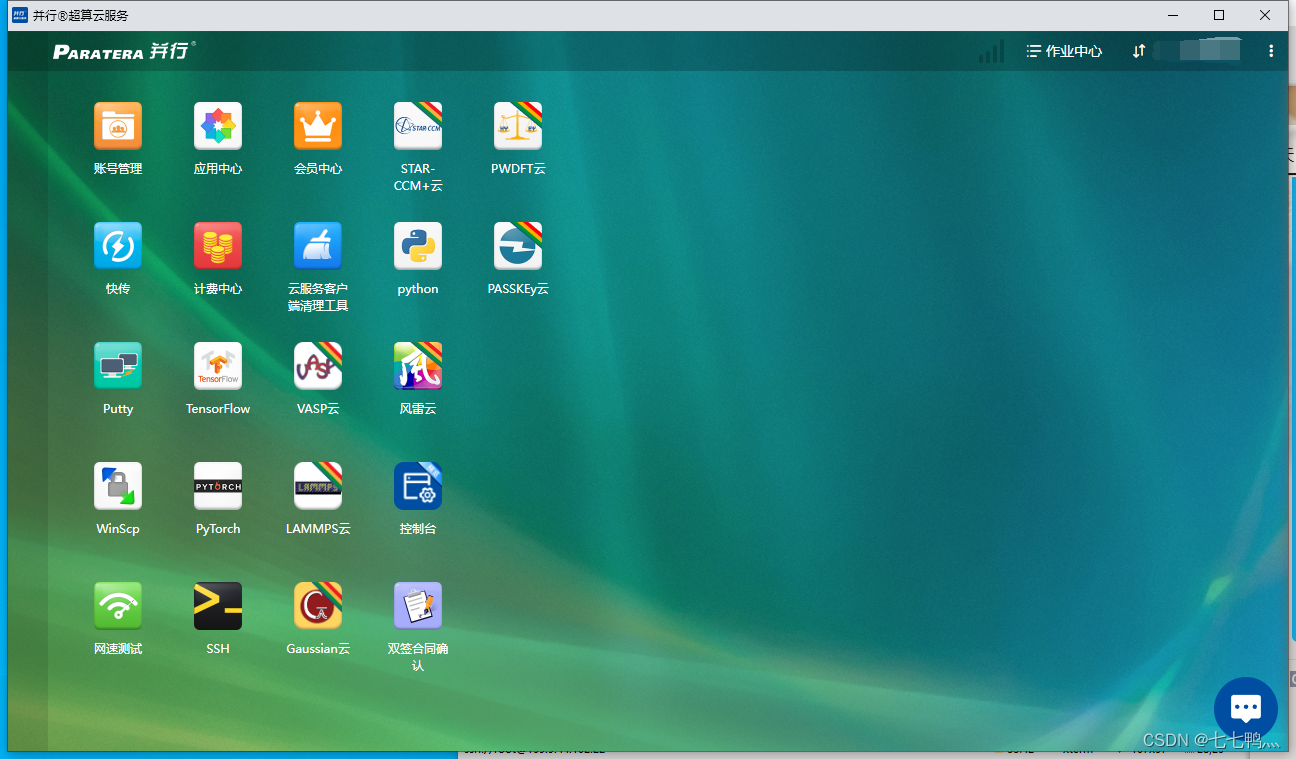
如图,我们主要使用到的超算服务如下:
快传:我们主要用来将本地的文件资源上传到服务器上,或者将服务器的文件下载到本地
Putty:远程连接到服务器,和SSH的区别是,Putty是在你电脑本地上运行的,SSH是在并行超算云客户端界面内运行的,个人认为没有Putty好用。
控制台:用来查看消费情况以及查看帮助手册。
具体详细用法和介绍,下文将提到。
二、远程连接节点服务器
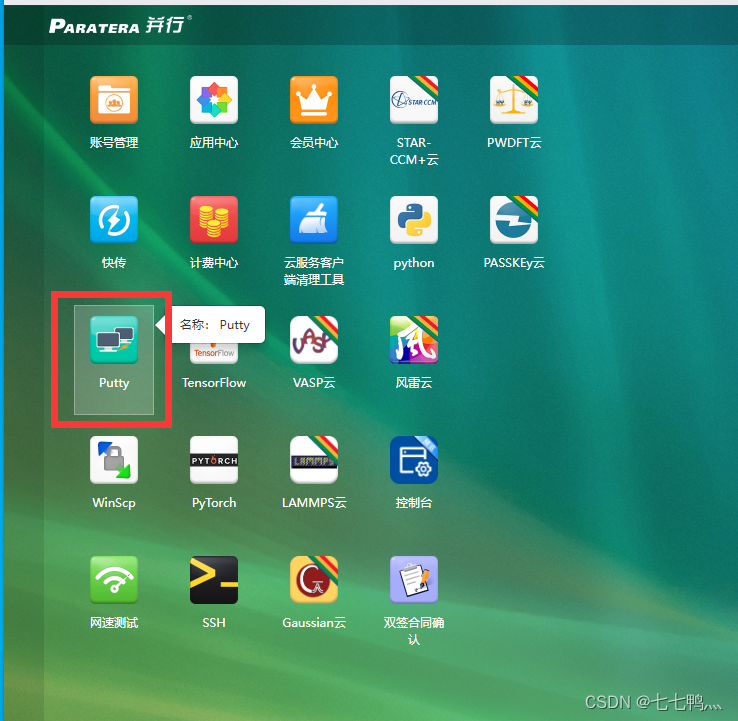
打开Putty
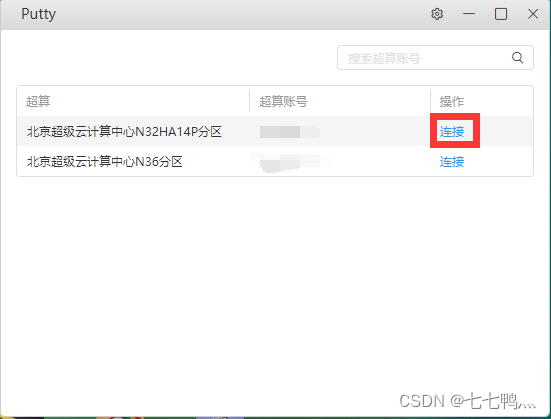
选择你购买的超算节点 并连接

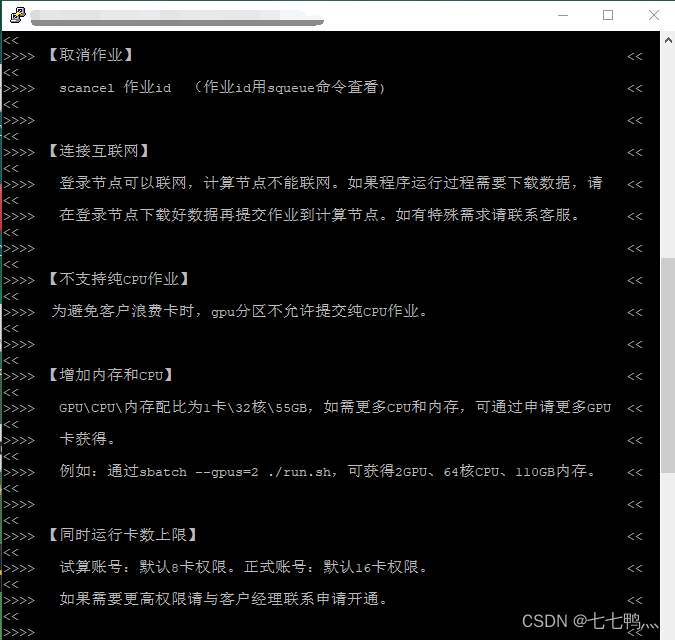
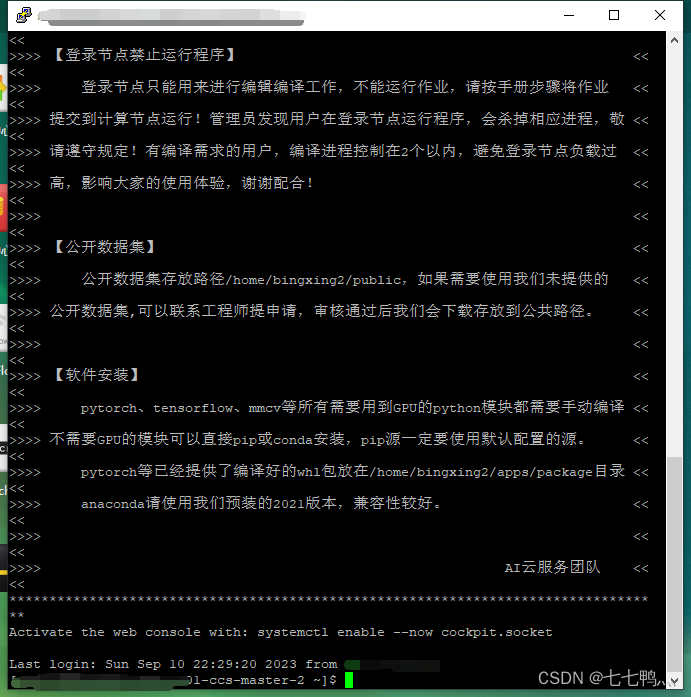
上述为并行超算云的简要使用手册。
总结一下:
我们通过Putty连接到的节点是登录节点,这个节点上我们主要是用来安装环境,解压上传的压缩包。但是不可以运行python程序
三、 安装环境
先使用module load anaconda/2021.11加载anaconda库,这样我们才可以在登录节点使用conda配置环境

然后我们使用source activate [你的conda环境名称]来进入你的conda环境。PS:因为并行超算云里面pytorch、tensorflow、mmcv等库是需要手动编译安装的,要是个人不熟悉操作的话,直接联系并行超算云的工程师提供你的账号和你要安装的pytorch、python、cuda等的版本,让它帮你创建好conda环境。
使用 conda list指令查看你当前的conda环境里面已经安装了什么库
需要新安装库的话使用如下命令进行安装
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple三、上传代码和数据集到服务器

打开快传
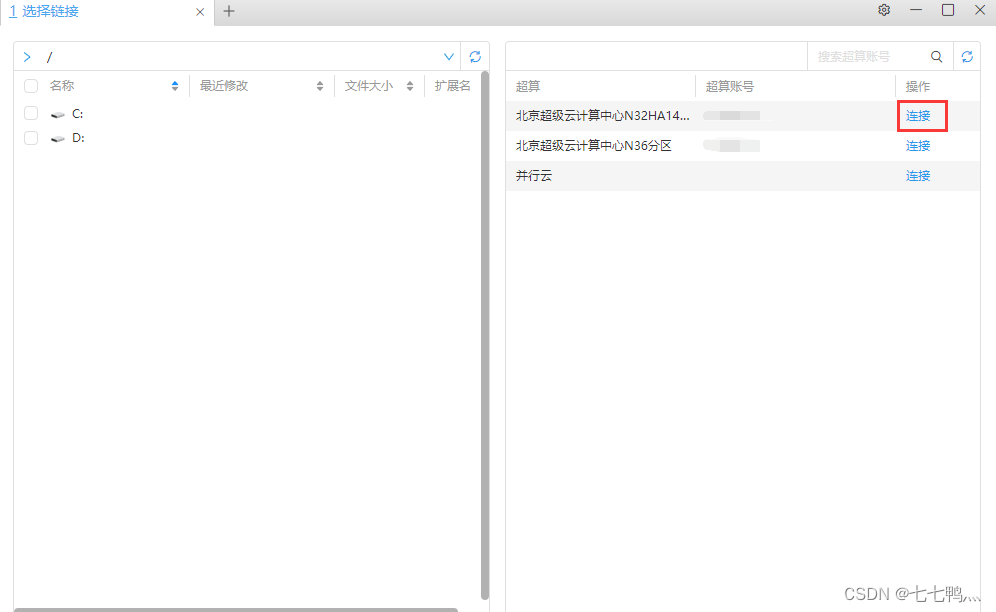
连接对应的超算账号
将本地ZIP压缩包拖放到空白位置或者文件夹内,即可自动上传。然后在Putty上使用如下命令,将ZIP压缩包解压到指定路径下
unzip /path/to/file.zip(压缩包路径) -d /path/to/destination(目标路径)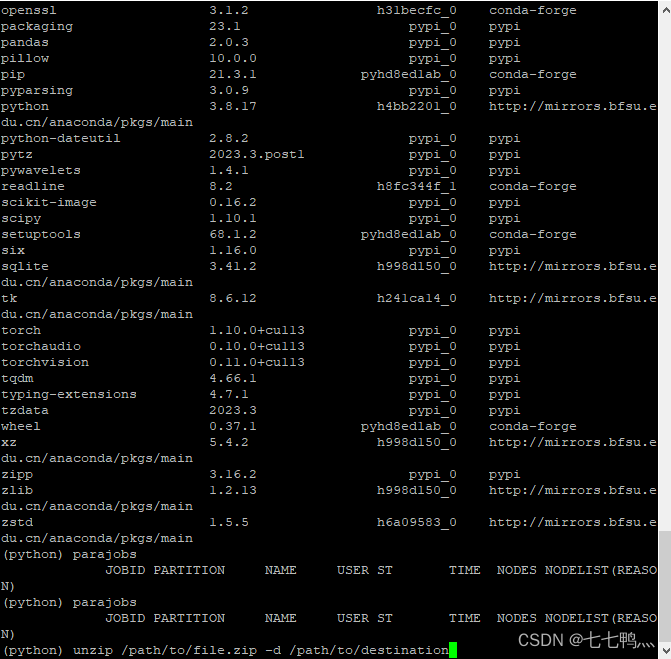
将我们的代码和数据集上传并解压好后,我们要写一个shell脚本用来启动模型训练。
#!/bin/bash
//比如是这个为开头
module load anaconda/2021.11
//加载anaconda
module load cuda/11.3
//加载cuda
source activate python
//进入你的conda环境,这里的python要改为你自己的conda环境名
export WORLD_SIZE=4
//单机多卡的话使用多少张卡就设置为几
python -m torch.distributed.launch --nproc_per_node=4 /home/bingxing2/home/xxx/zjd/zijiandu/models/train.py
//同理_per_node也是设置为卡数,然后路径设置为自己模型的训练脚本路径
如果出现 /var/www/borg/fuel/app/tasks/monitor_sync.sh/var/www/borg/fuel/app/tasks/monitor_sync.sh: line 11: $'\r': command not found/var/www/borg/fuel/app/tasks/monitor_sync.sh: line 12: syntax error near unexpected token `$'{\r''这种换行符报错的话,这是shell脚本格式不正确导致的,我们可以使用dos2unix命令转化shell脚本的格式,然后重新运行shell脚本即可
dos2unix /home/xxx/avc/sss.sh(你的shell脚本的路径)四、将训练任务提交到计算节点,进行模型训练
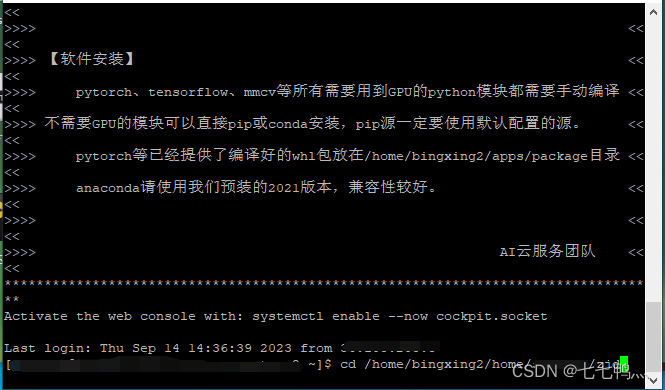
我们先使用cd 命令进入到之前编写好的shell脚本的目录下
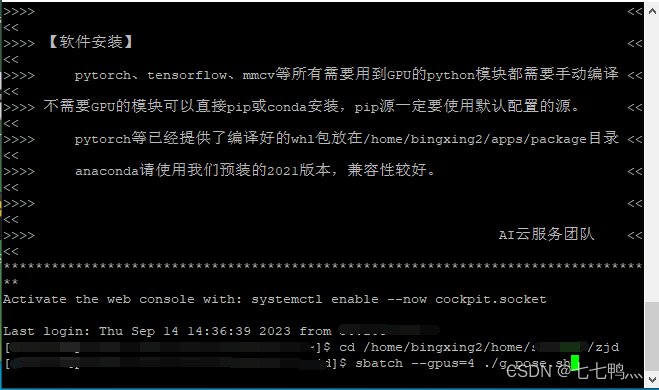
然后使用sbatch --gpus=4 ./shell脚本名称,就可以将脚本任务提交到计算节点进行训练,我们这里是使用了4张A100进行演示。
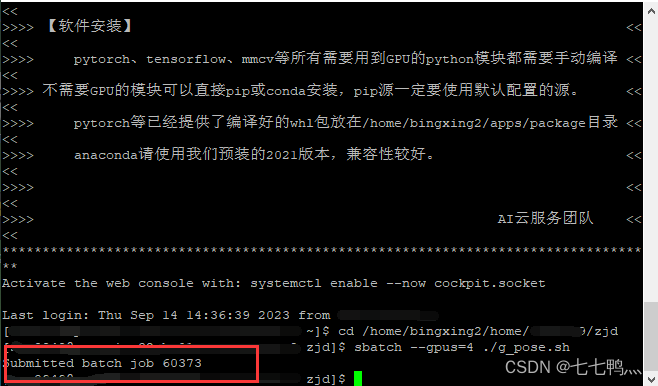
这样就是提交成功了,60373就是计算进程号,后续可以通过这个进程号取消计算作业
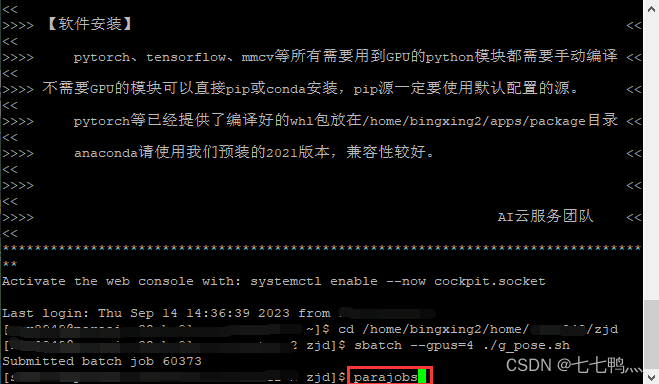
然后我们使用parajobs指令,可以查看计算节点中各显卡的运行情况,如下图所示
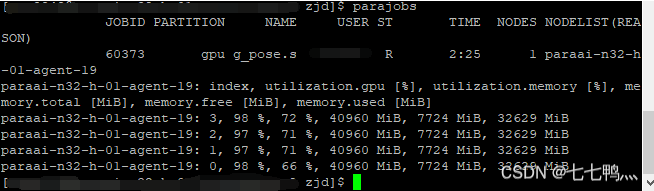
当你想停止作业的时候,就使用scancel 进程ID就可以取消作业。
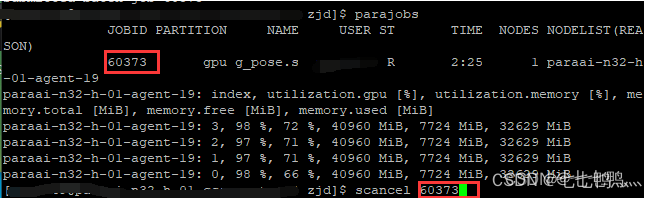
这个是日志文件,报错信息呀 打印信息都在里面
五、下载训练好的文件
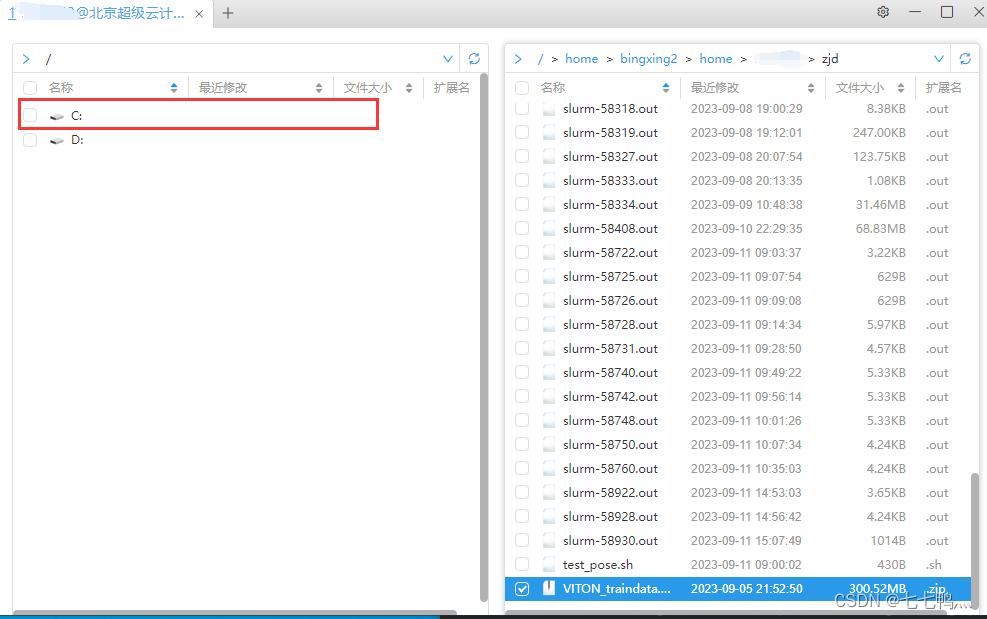
我们是不能够直接下载文件夹里面的文件的,我们先双击进入左侧本地的磁盘

然后进入你想要保存下载文件的路径下
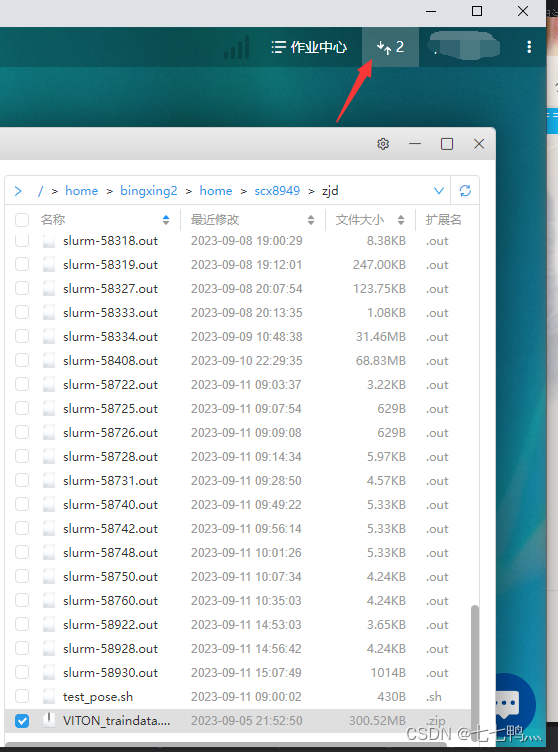
然后这个时候就可以右键文件,下载到对应的本地路径下

至此,整个并行超算云计算中心的模型基本使用流程和训练方法就是这样了。

后续有问题的话就可以打开控制台
选择帮助文档
选择对应分区的用户手册,里面有服务器的各种命令使用教程
尾言
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。



















 2082
2082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











