






本文目录
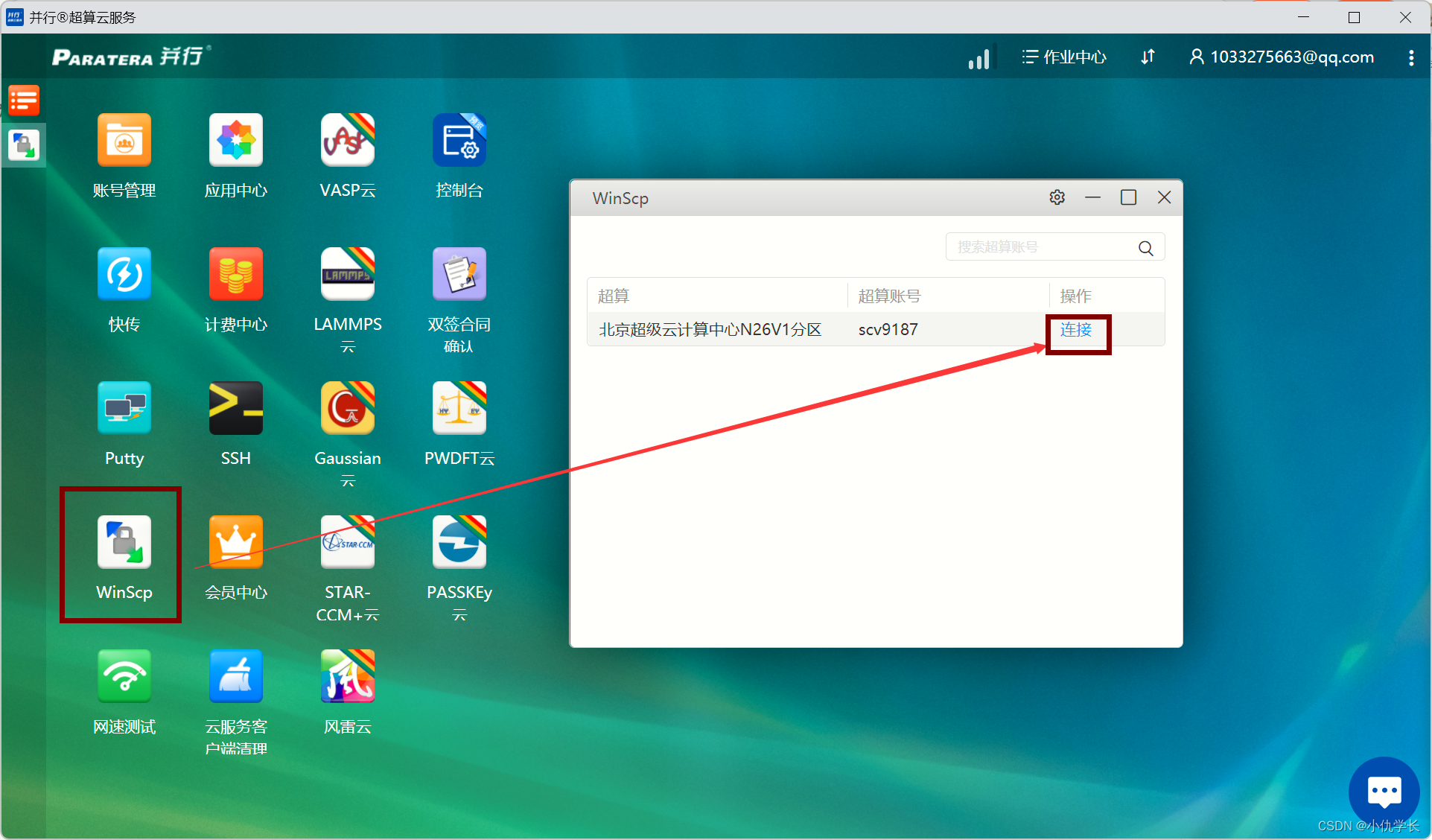
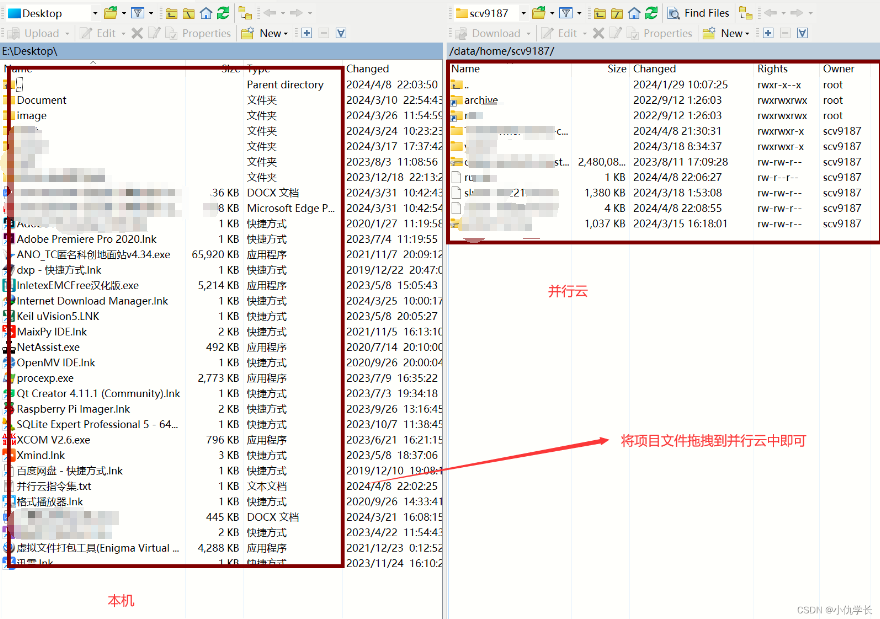
一、将项目传入并运云。
二、创建项目的虚拟环境
- 打开终端
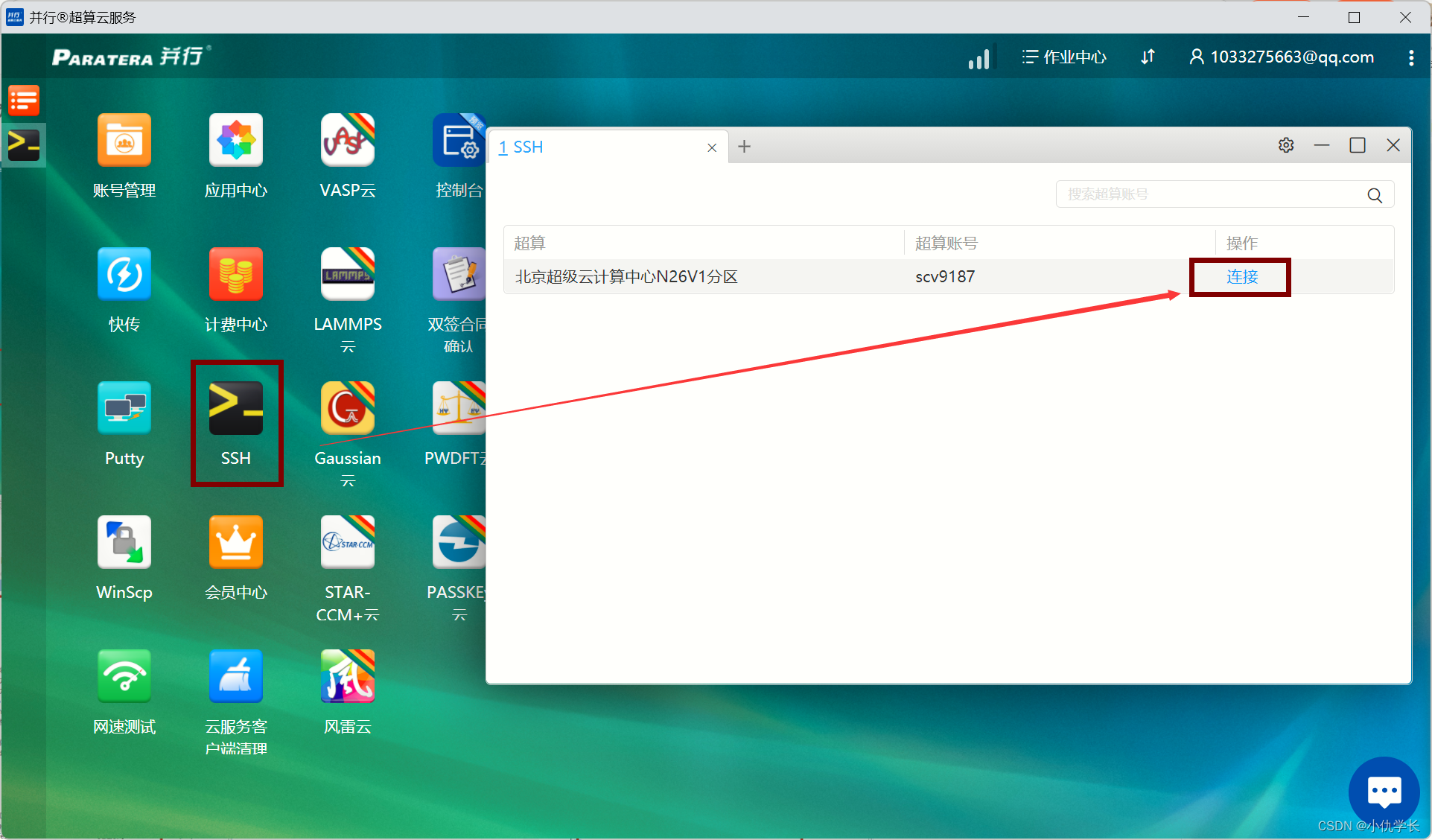
- 使用conda创建:
conda create -n 环境名 python=3.8 - 查看conda下所有的环境:
conda env list - 激活环境:
conda activate 环境名 - 安装项目所需模块:
pip install 模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple,如果项目有requirements.txt文件,则需要先cd到包含该文件的目录下,使用pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple来安装所有模块。 - 查看当前环境下所有的模块:
module ava
三、编辑run.sh脚本
此处的脚本用于后续的提交作业。
#!/bin/bash
export PYTHONUNBUFFERED=1
conda activate yolov5
cd /data/home/scv9187/yolov1
python train.py
主要修改以下内容:
conda activate yolov5:激活刚才创建好的环境,这里yolov5是环境名,要根据自己所创建的环境修改。cd /data/home/scv9187/yolov1:切换含有train.py文件的目录下。python train.py:运行train.py文件。
四、提交作业
我们需要先cd到含有run.sh脚本文件的目录下,然后使用下面命令提交脚本文件。run.sh在哪个目录下,最后生成的.out文件就在哪个目录下。
使用命令:sbatch --gpus=GPU卡数 run.sh,这里GPU卡数不要超过8。使用的卡数不同需要等待资源分配的时间也不同。
使用示例:sbatch --gpus=8 run.sh

提交后会立刻获得一个作业号,但是这个作业号并不是.out文件,只是为了方便后续我们区别不同的作业而已。即使是提交同一份代码,每次运行该命令得到的作业号也不一样。
坑1:提交作业后未生成.out文件
在提交完成后,等待片刻,终端会生成一个作业号.out文件。但是这并不是立刻生成的,当我们提交了作业后,云计算端会按照作业的排队顺序去分配计算资源,当作业被分配了资源后,才会生成.out文件。这时需要等待分配资源即可。
坑2:如果长时间没有生成.out文件
可能是该GPU卡数排队作业量较多,使用不同的卡数试一下。
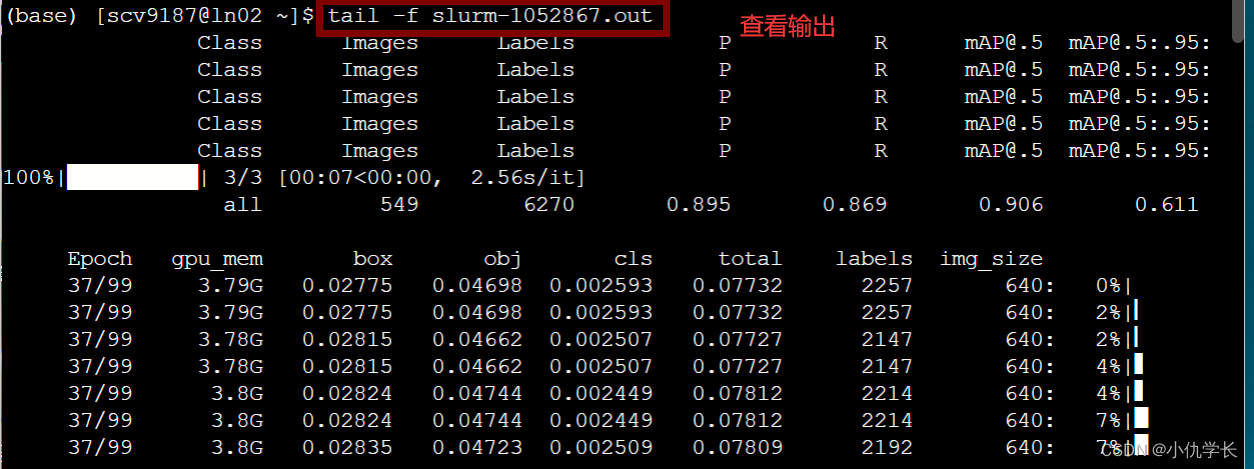
五、查看作业输出
使用命令:tail -f slurm-作业号.out
使用示例:tail -f slurm-1052867.out
特别注意:只有终端生成了.out文件后,我们才可以使用上面的命令就可以查看作业的输出内容。
六、查看提交的作业号
使用命令:squeue

作业运行状态:
R:正在运行
PD:正在排队
CG:即将完成
CD:已完成
七、结束作业
使用命令:scancel 作业号



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









