








🧠 Python 时序数据分析的解读与实践:ARIMA模型、SARIMA模型、LSTM模型,模型评估指标
目录
- 🔍 ARIMA模型:自回归积分滑动平均模型详解
- 🌐 SARIMA模型:季节性ARIMA的扩展与应用
- 🧬 LSTM:长短期记忆网络在时序数据中的应用
- 📊 模型评估指标:RMSE、MAE等方法解析
1. 🔍 ARIMA模型:自回归积分滑动平均模型详解
ARIMA模型(AutoRegressive Integrated Moving Average)是用于分析和预测时间序列数据的常用统计方法。它由三个部分组成:自回归(AR)、差分(I,积分)和滑动平均(MA)。ARIMA的主要目标是通过建模时间序列的趋势、周期性和随机波动来进行预测,尤其适合处理非平稳的时间序列数据。
🧩 ARIMA模型的三个组成部分
-
自回归(AR): 通过前几个时间点的数据来预测当前时间点。它基于这样的假设,即当前值与前几个时刻的值之间存在线性关系。
- 数学公式:
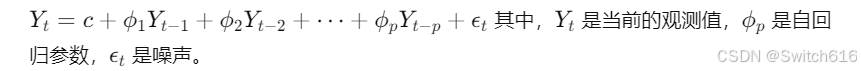
- 数学公式:
-
差分(I): 用于将非平稳的时间序列转换为平稳序列。通过计算相邻时间点的差值,消除趋势和季节性波动。
- 一阶差分公式:
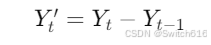
- 一阶差分公式:
-
滑动平均(MA): 通过当前和前几个时刻的误差(噪声)来预测未来的值。
- 数学公式:
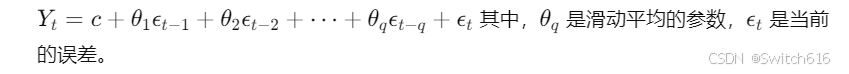
- 数学公式:
🛠 ARIMA模型的参数选择
ARIMA模型由三个重要的参数控制:( p )、( d ) 和 ( q ),分别表示自回归阶数、差分次数和滑动平均阶数。
- p(自回归阶数):决定了模型在多大程度上使用过去的值来预测当前值。
- d(差分次数):决定了差分的次数,以消除趋势使序列平稳。
- q(滑动平均阶数):决定了预测当前值时所使用的噪声项的数量。
🧑💻 ARIMA代码实现
以下是使用Python库 statsmodels 进行ARIMA建模的示例:
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# 假设有一个时序数据集,加载数据
data = pd.read_csv('time_series_data.csv', index_col='Date', parse_dates=True)
data = data['Value']
# 可视化原始数据
plt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
plt.title('Time Series Data')
plt.show()
# 构建ARIMA模型(p=2, d=1, q=2)
model = ARIMA(data, order=(2, 1, 2))
model_fit = model.fit()
# 输出模型摘要
print(model_fit.summary())
# 使用模型进行预测
predictions = model_fit.forecast(steps=10)
print("预测结果:", predictions)
# 可视化预测结果
plt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
plt.plot(pd.date_range(start=data.index[-1], periods=11, freq='D')[1:], predictions, label='Predicted', color='red')
plt.title('ARIMA Model Forecast')
plt.legend()
plt.show()
📝 ARIMA模型的优势与局限性
优势:
- ARIMA模型能够捕捉时间序列中的趋势和周期性变化,并能有效处理非平稳时间序列。
- 参数的灵活性允许它适用于多种时间序列问题。
局限性:
- 当数据具有复杂的季节性模式或非线性关系时,ARIMA可能表现不佳。
- 该模型假设时间序列为线性,无法处理高度非线性的情况。
2. 🌐 SARIMA模型:季节性ARIMA的扩展与应用
ARIMA模型虽然强大,但它无法直接处理季节性数据。为了解决这一问题,SARIMA(Seasonal ARIMA)扩展了ARIMA,加入了处理季节性成分的能力。SARIMA在ARIMA模型的基础上,增加了季节性自回归、季节性差分和季节性滑动平均成分,用来处理数据中的周期性波动。
🧩 SARIMA的参数
SARIMA模型的表示形式为
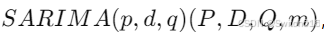
其中:
- p、d、q:与ARIMA模型中的参数相同,分别代表自回归阶数、差分次数和滑动平均阶数。
- P、D、Q:分别代表季节性自回归阶数、季节性差分次数和季节性滑动平均阶数。
- m:代表季节长度(例如,m=12 代表按年为周期的月度数据)。
🛠 SARIMA的原理
SARIMA模型的核心思想是将时间序列数据的季节性模式与非季节性模式分别处理。季节性成分用于解释数据的周期性,而非季节性成分则捕捉趋势和短期波动。
🧑💻 SARIMA代码实现
以下是SARIMA模型的代码实现,使用statsmodels库进行建模:
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
import matplotlib.pyplot as plt
# 加载季节性时间序列数据
data = pd.read_csv('seasonal_time_series_data.csv', index_col='Date', parse_dates=True)
data = data['Value']
# 可视化原始数据
plt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
plt.title('Seasonal Time Series Data')
plt.show()
# 构建SARIMA模型 (p=1, d=1, q=1) (P=1, D=1, Q=1, m=12)
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
model_fit = model.fit()
# 输出模型摘要
print(model_fit.summary())
# 使用模型进行预测
predictions = model_fit.forecast(steps=12)
print("预测结果:", predictions)
# 可视化预测结果
plt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
plt.plot(pd.date_range(start=data.index[-1], periods=13, freq='M')[1:], predictions, label='Predicted', color='red')
plt.title('SARIMA Model Forecast')
plt.legend()
plt.show()
📝 SARIMA模型的应用与优势
优势:
- SARIMA通过引入季节性成分,能更好地处理具有周期性或季节性波动的时间序列数据。
- 适用于每年、每月或每周出现周期性模式的数据。
应用场景:
- 财务分析中,按月、季度预测销售额或收入。
- 气象数据的季节性分析,例如按月预测温度或降水量。
3. 🧬 LSTM:长短期记忆网络在时序数据中的应用
在处理时间序列数据时,传统的统计方法如ARIMA和SARIMA虽然有效,但它们对数据的线性假设限制了它们在更复杂的非线性数据中的表现。长短期记忆网络(LSTM)是一种特殊的递归神经网络(RNN),它能够有效捕捉时间序列数据中的长期依赖关系,尤其适合处理非线性和复杂的序列数据。
🧩 LSTM的基本结构
LSTM通过在每个时刻维护一个“记忆单元”,解决了传统RNN中的梯度消失问题。这使得LSTM能够学习和存储长时间跨度的依赖关系。LSTM单元的关键组件包括:
- 遗忘门(Forget Gate):决定需要遗忘的历史信息。
- 输入门(Input Gate):决定哪些新的信息需要
存储到记忆单元。
- 输出门(Output Gate):决定当前时刻的输出,以及记忆单元的更新。
🧑💻 LSTM代码实现
以下是使用Python库 Keras 构建LSTM模型的代码示例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 加载时间序列数据
data = pd.read_csv('time_series_data.csv', index_col='Date', parse_dates=True)
data = data['Value']
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data.values.reshape(-1, 1))
# 准备训练数据
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), 0]
X.append(a)
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 10
X, Y = create_dataset(scaled_data, look_back)
# 将数据重新塑形为LSTM输入格式 [样本数, 时间步长, 特征数]
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(look_back, 1)))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 训练模型
model.fit(X, Y, epochs=100, batch_size=64, verbose=1)
# 进行预测
train_predict = model.predict(X)
# 反归一化数据
train_predict = scaler.inverse_transform(train_predict)
# 可视化预测结果
plt.figure(figsize=(10, 6))
plt.plot(data.index, data.values, label='Original Data')
plt.plot(data.index[look_back+1:], train_predict, label='LSTM Predictions', color='red')
plt.title('LSTM Model Predictions')
plt.legend()
plt.show()
📝 LSTM的优势与应用
优势:
- LSTM能够处理长序列中的长期依赖性,适合分析金融市场数据、气象数据等复杂时序数据。
- 相比传统统计方法,LSTM对数据的非线性变化具有更强的适应能力。
应用场景:
- 金融领域:股票价格预测、市场趋势分析。
- 自然语言处理:文本生成、情感分析。
- 信号处理:音频信号的预测和生成。
4. 📊 模型评估指标:RMSE、MAE等方法解析
在构建和训练时间序列模型后,评估模型的预测性能至关重要。常用的评估指标包括均方根误差(RMSE)、平均绝对误差(MAE)等。这些指标帮助量化模型在预测时的误差大小,从而评估其实际应用的有效性。
🔍 均方根误差(RMSE)

🔍 平均绝对误差(MAE)

🧑💻 计算RMSE和MAE的代码示例
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
# 计算RMSE
rmse = np.sqrt(mean_squared_error(data[look_back+1:], train_predict))
print(f"RMSE: {rmse}")
# 计算MAE
mae = mean_absolute_error(data[look_back+1:], train_predict)
print(f"MAE: {mae}")
📝 指标的意义
- RMSE适合用于关注较大误差的场景,因为它对异常值更为敏感。
- MAE提供了更加平滑的误差度量,不容易受极端值影响。
评估指标的选择应根据具体应用场景而定,通常建议结合使用多个指标来全面评估模型的表现。
通过深入理解和应用ARIMA、SARIMA和LSTM等时序模型,可以有效应对不同类型的时间序列数据分析和预测任务。使用适当的模型评估指标,可以更好地理解模型的性能并进行优化,以实现更高质量的预测。


















 2271
2271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











