







目录
1. 精度和召回率
1.1 两个指标的概念
首先理解下TP、FP、TN、FN分别代表什么意思。
- True Positives,TP:预测为正样本,实际也为正样本的特征数。即检测到了目标,并且这个目标确实存在。
- False Positives,FP:预测为正样本,实际为负样本的特征数。即检测到了目标,但是实际上这个目标不存在。
- True Negatives,TN:预测为负样本,实际也为负样本的特征数。即没有检测到目标,实际上目标也不错在。
- False Negatives,FN:预测为负样本,实际为正样本的特征数。即没有检测到目标,但是目标事实上存在。
准确率计算公式:(TP/(TP+FP))
召回率计算公式: (TP/(TP+FN))
1.2 两个指标的优缺点
精度指标的优点:防止胡乱检测目标。
精度指标的缺点:假设有100个目标需要被检测出来,我只要检测出三个,然后不检测出其他东西,正确率是百分之百,这个显然是不能代表算法的好坏。
召回率指标的优点:假设有100个目标需要被检测出来,必须要尽可能把所有目标全部检测出来,指标才会高。
召回率指标的缺点:假设有100个目标需要被检测出来,那我暴力遍历图像区域,把一大堆区域都认定是目标,这样召回率指标会很高,但是显然也不合理。
2. AP值和mAP值计算
2.1 绘制PR曲线(准确率-召回率曲线)
计算AP值的第一步是绘制PR曲线。
以一张图片为例,假设共有(1,2,3)三种目标类别,经过NMS后该图片中保留的bounding boxes(边界框)及其对应的confidence score(置信度)、pred_label(预测的种类)如下表:
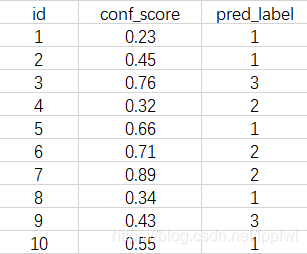
对于这些预测出来的边界框要判断是TP还是FP,需要按照ground truth(真实边界框)和bounding boxes(预测边界框)的重叠比例是否大于iou_thres(重叠阈值)来判断。iou_thes的取值不同即为不同的AP类型,如iou_thres=0.5对应AP50,iou_thres=0.75对应AP75等等(在一些算法中,经常会出现AP50或者AP75,一般来说iou_thres越高,相应的指标也会更高,因为相当于对检测效果的要求降低了,指标自然会上去)。
综上所述,判断bounding boxes是TP还是FP的过程如下:
对于每个预测的bounding box,如上表id=1的box,其pred_label为1,则计算其与该图片中所有类别为1的ground truth box的IOU值,取其中最大IOU值iou_max对应的ground truth box作为该预测box对应的ground truth box,如果iou_max>iou_thres,则该预测box即为TP,否则为FP。
注意:有人可能会问,这样一个ground truth box不就可能会匹配到多个正确检测框吗,个人理解是,一旦将一个检测框和对应的ground truth box进行匹配之后,这个ground truth box就会从待匹配列表中剔除,防止后续重复计算。
上表中的各预测box的tp_label如下表所示(已按conf_score排序),TP为1,FP为0(假设这个检测框是TP,则tp_label为1,否则为0):
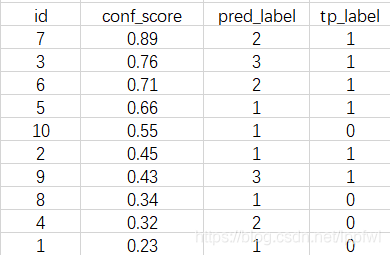
对每个类别需要单独计算AP,最后所有类别取平均。
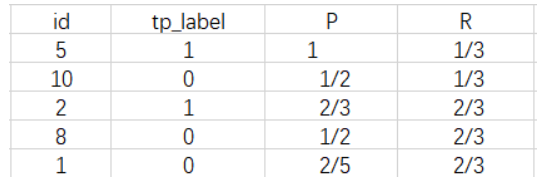
下面以类别1为例,假设该测试集图片中共有3个类别1的标注框(ground truth boxes),显然上述预测结果并没有将全部真值召回。
绘制P-R曲线,曲线的采样点为,结果如下表:
2.2 求AP
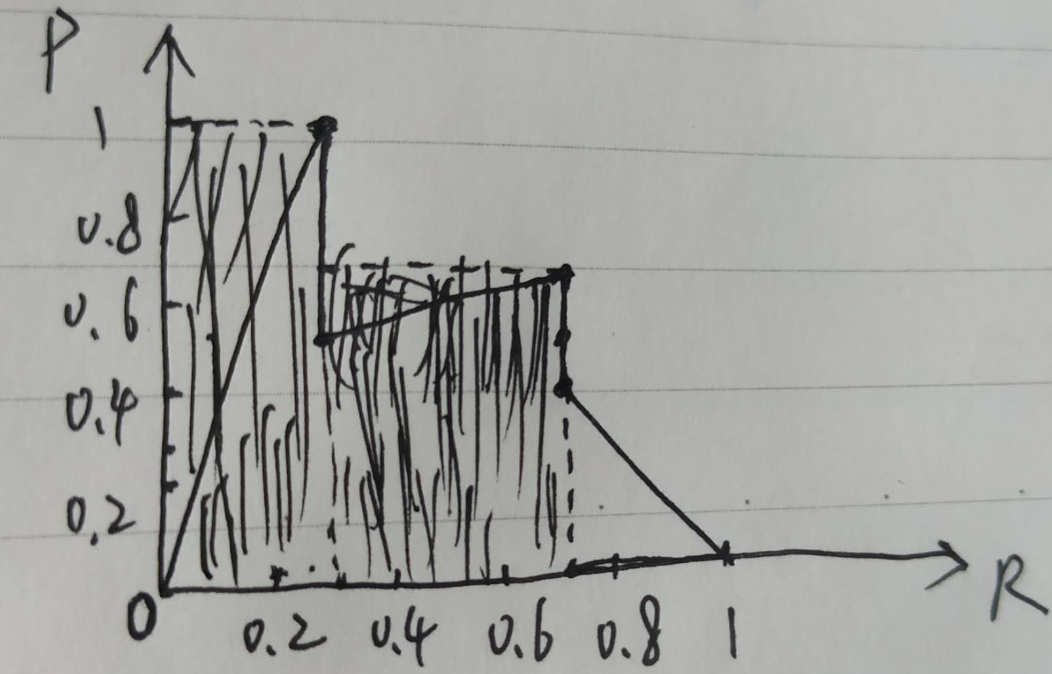
按照上图所示的方式计算黑色区域面积,即为单个类的AP值
2.3 求mAP
按照2.2的步骤单独计算每个类的AP值,然后求平均,即为mAP值。
3. 损失计算
个人觉得yolo的损失计算才是yolo网络最难的一个点,而很多视频教程其实对此提及较少,主要是细节太多,不便于讲清楚。
3.1 Anchor与GroundTruth匹配
在计算损失之前,首先我们需要知道GroundTruth(标签值)需要和哪些Anchor计算损失,即如何将Anchor和GroundTruth进行匹配,以下图为例(引用其他博主),如果不进行这一步,假设右下角的Cell负责的Anchor去和左侧那辆车的标签进行损失计算,显然是不合理的,因为右下角的Cell根本不需要对离它如此之远的目标进行预测。
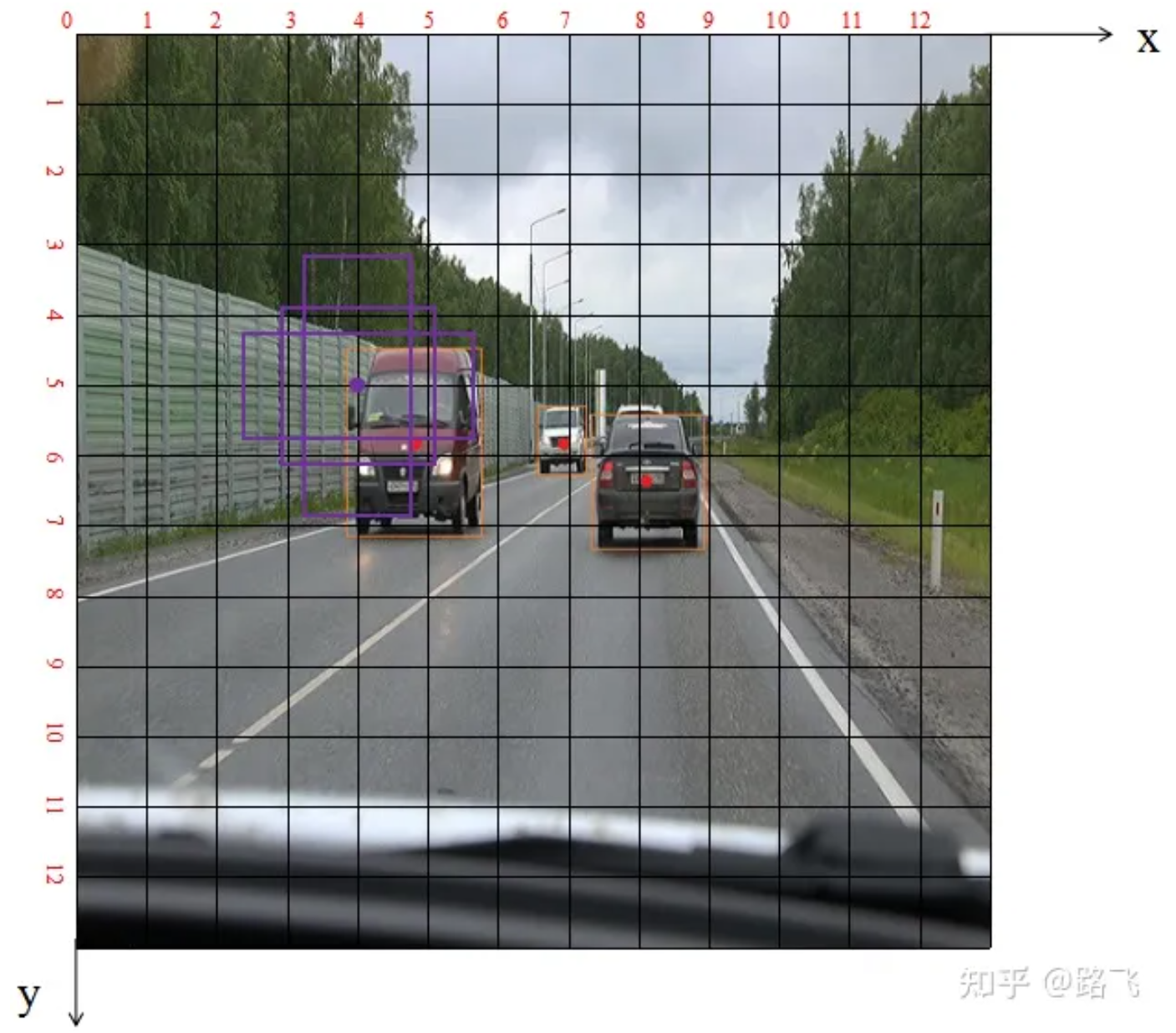
YOLO最终输出三个尺度的特征图,分别用于预测大、中、小的目标。假设输入图像尺寸为416X416,用于预测大尺寸目标的特征图尺寸为13X13(下采样32倍),示意图依旧是上图。将左侧汽车橙色的GroundTruth与这3个紫色的Anchors分别计算iou,并分别在26*26尺度、52*52尺度下执行相同操作,得到与GroundTruth最大iou的那个先验框Anchor作为正样本,小于设定阈值的作为负样本,大于设定阈值但不是最大iou的为忽略样本。
注意!!!以上操作是基于IOU去匹配Anchor,但是在YOLOV5中是以长宽比进行匹配,但是总体思路是一样的。此外,一个目标应该不是单单匹配一个Anchor,而是匹配多个Anchor,这样也比较符合实际情况,有的目标介于多个Anchor的尺度和位置之间。
Anchor与GroundTruth匹配的目的就是找出与GroundTruth最匹配的先验框Anchor,并且返回该GroundTruth框相对于该先验框锚点的偏移量和在该特征图下的长宽尺寸tbox(上图中偏移量为0.82,0.81,宽高为1.9和2.7),以及类别tcls(上图为汽车),与gt匹配的先验框的xy坐标indices(上图为4,5),与gt匹配的先验框的宽高anchor(上图中为2.2,2.2)。
该部分的算法细节比较多,可以debug一步步看,源码在yolov5工程目录的loss.py文件夹下。















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









