






导读在 AI 浪潮席卷全球的今天,大型语言模型(LLM)的算力需求日益攀升,高昂的资源成本却让许多场景望而却步。微软研究院最新发布的 BitNet b1.58 2B4T,以 20 亿参数和 1.58 比特量化的极致效率,颠覆传统全精度模型范式,性能媲美顶尖模型,内存占用仅 0.4GB,能耗节省超 90%!
©️【深蓝AI】编译
论文标题:BitNet b1.58 2B4T Technical Report
论文作者:Shuming Ma, Hongyu Wang, Shaohan Huang, Xingxing Zhang, Ying Hu, Ting Song, Yan Xia, Furu Wei
论文链接:https://arxiv.org/pdf/2504.12285
项目主页:https://aka.ms/GeneralAI
代码链接:https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
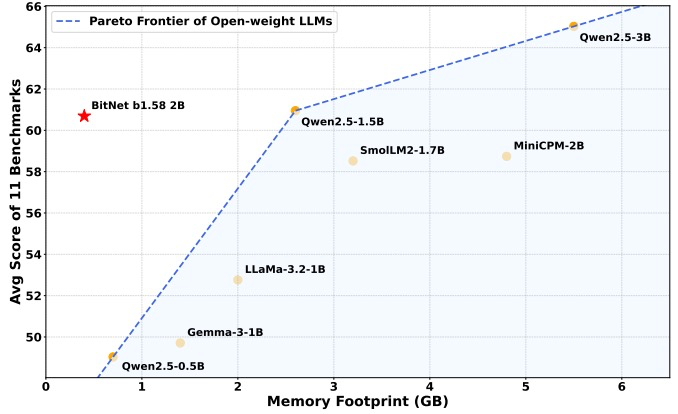
图1:BitNet b1.58 2B4T 在 3B 参数规模以下的性能与内存占用方面,推进了由领先开源权重模型定义的帕累托前沿,展现出卓越的效率。
1、本文概要
BitNet b1.58 2B4T 由微软研究院团队研发,基于 4 万亿 tokens 训练,采用 1.58 比特量化,将权重约束为 -1、0、+1,内存需求从全精度模型的数 GB 压缩至 0.4GB,推理延迟低至 29ms/token,能耗仅 0.028J。无论是语言理解、数学推理、代码生成还是多轮对话,它都能与 LLaMA 3.2 1B、Qwen2.5 1.5B 等全精度模型媲美。模型权重与推理代码已通过 Hugging Face 开源,为开发者提供无限可能。
这款模型的意义远不止技术突破。它的超低资源需求让 AI 从云端走向手机、物联网等边缘设备,降低部署成本,推动绿色计算与 AI 普惠化。BitNet b1.58 证明,极致量化也能实现顶尖性能,挑战了“高性能需高资源”的传统观念。
2、核心创新
▍BitLinear层,极致压缩的关键
BitNet b1.58 2B4T的“杀手锏”在于用定制的BitLinear层替换了传统的全精度线性层。这个BitLinear层到底有多厉害?来看看它的三大绝招:
1. 权重量化:模型权重在前向传播时被压缩到仅1.58位!通过绝对均值量化,权重被映射到{-1, 0, +1}三个值。这不仅让模型体积大幅缩小,还让计算效率飞起!
2. 激活量化:激活值被量化为8位整数,采用基于每个token的绝对最大值量化策略,兼顾精度与效率。
3. 归一化加持:引入了subln归一化,让模型在量化训练中更稳定,训练过程如丝般顺滑。
▍性能优化核心技术
除了BitLinear层,BitNet b1.58 2B4T还整合了多种成熟技术,让性能和稳定性双双在线:
-
激活函数:在前馈网络中,模型抛弃了常见的SwiGLU激活,转而使用平方ReLU。这一选择在1位量化环境中能提升模型稀疏性,计算效率再上一层楼。
-
位置嵌入:采用旋转位置嵌入,为模型注入精准的位置信息,这是高性能大模型的标配。
-
偏置:参考LLaMA架构,模型去掉了所有线性层和归一化层的偏置项,参数量减少,量化过程更简单。
▍分词器选择
在分词方面,BitNet b1.58 2B4T直接采用了LLaMA 3的字节级字节对编码分词器,词汇表高达128,256个token!这个分词器不仅能轻松应对多样的文本和代码,还因其广泛应用,完美适配现有的开源生态!
3、多阶段训练细节
BitNet b1.58 2B4T的训练过程分为三大阶段:大规模预训练、监督微调(SFT)和直接偏好优化(DPO)。这套高效的训练策略让模型在小体量下也能展现惊人性能!
▍预训练:打下扎实的语言基础
预训练的目标是让模型掌握广泛的世界知识和语言能力。两个阶段主要在学习率调度和权重衰减有重大区别:
-
学习率调度:第一阶段采用高学习率和余弦衰减,1位模型的稳定性允许更大胆的学习步幅;第二阶段“降温”,骤降学习率,配合余弦调度,专注高质量数据优化。
-
权重衰减:第一阶段用余弦调度,峰值0.1防止过拟合;第二阶段关闭权重衰减,让模型参数更精细调整。
数据选择:使用公开的文本和代码数据集,如DCLM和FineWeb-EDU,加入合成数学数据增强推理能力。第一阶段处理通用数据,第二阶段聚焦高质量数据集。
▍监督微调:
SFT阶段提升模型的指令遵循和对话能力。使用WildChat、LMSYS-Chat-1M等多样化指令和对话数据集,辅以GLAN、MathScale等合成数据增强推理。优化细节包括:
-
损失聚合:采用损失求和而非均值,提升收敛效果。
-
超参数调整:1位模型需要更大胆的学习率和更多训练轮次。
-
对话模板:采用结构化模板,确保对话任务一致性。
▍直接偏好优化:
DPO阶段通过UltraFeedback和MagPie等偏好数据集,进一步优化模型的帮助性和安全性。训练2轮,学习率2×10^-7,DPO beta设为0.1,结合Liger Kernel库提升效率。DPO让模型生成更符合人类预期的回答,同时保留核心能力。
4、性能评估
BitNet b1.58 在多项基准测试中表现出色,与全精度模型正面交锋。它内存占用仅 0.4GB,推理延迟 29ms/token,能耗节省 90%,效率远超 LLaMA 3.2 1B(1.4GB,41ms/token)等模型。在 ARC-Challenge(49.91%)、GSM8K(58.38%)、WinoGrande(71.90%)等任务中名列前茅,综合得分接近 Qwen2.5 1.5B,远超 Gemma-3。相比其他 1 比特模型,如 Bonsai 0.5B,它平均得分高出近 20%,甚至超越更大的后量化模型。
不过,在知识密集型任务如 TriviaQA 上,模型表现稍弱,可能受数据分布或量化限制影响。未来优化数据集和长上下文支持将进一步提升其能力。
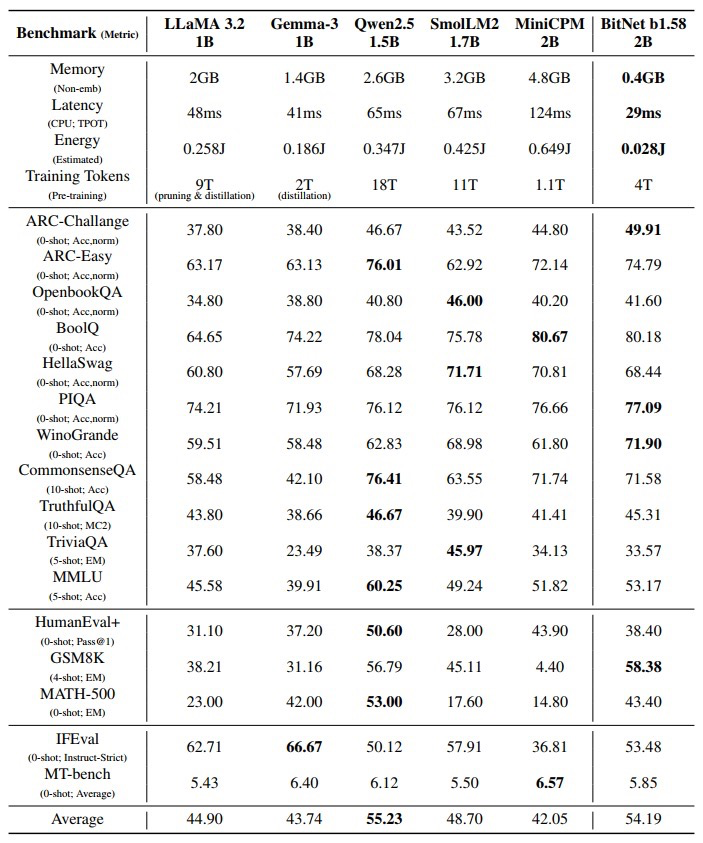
表1:BitNet b1.58 2B4T 在多个基准测试中的性能与内存占用对比,显示出其在保持高性能的同时,显著降低了内存需求。
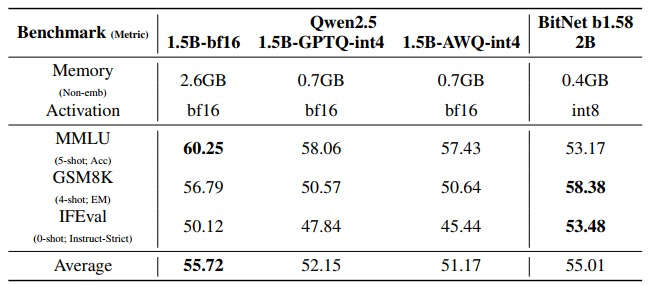
图2:BitNet b1.58 2B4T 与 Qwen2.5 1.5B 的 INT4 后训练量化版本的性能对比,展示出其在保持高性能的同时,内存占用更低。
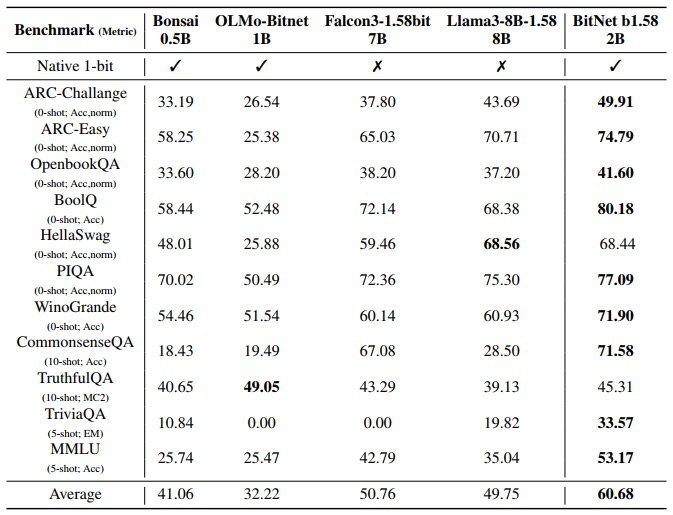
BitNet b1.58 2B4T 与其他 1-bit 模型(包括原生 1-bit 模型和后量化模型)的性能对比,显示出其在 1-bit 精度下的卓越性能。
5、结语
BitNet b1.58 2B4T 不仅是一款模型,更是一场范式革命。它让 AI 走进资源受限的边缘设备,助力中小企业与个人开发者拥抱先进技术;能耗降低 90%,为绿色 AI 树立标杆;开源生态降低技术门槛,激发全球创新。这款模型质疑了全精度权重的必要性,或将引领模型压缩新潮流。
未来,BitNet b1.58 有望向更大规模扩展,支持多语言和多模态任务,结合专用硬件释放更大潜力。尽管在知识任务和硬件适配上仍有改进空间,其创新性已足以震撼行业。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









