







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
在评估有监督学习的回归问题和分类问题时,所需的指标不同
| 分类问题 | 回归问题 |
| 混淆矩阵 | 均方误差MSE |
| 正确率 | 决定系数 |
| 精确率 | MAE |
| 召回率 | |
| F值 | |
| AUC与ROC |
一、分类评估指标
1,混淆矩阵
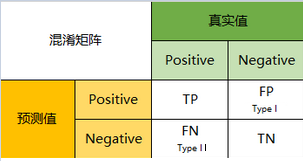
混淆矩阵,可以理解为就是一张表格,混淆矩阵其实就是一张表格而已。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。
这里得到四个基础指标:
1)TP(True Positive)
真实值是positive,模型认为是positive的数量
2)FN(False Negative)
真实值是positive,模型认为是negative的数量
3)FP(False Positive)
真实值是negative,模型认为是positive的数量
4)TN(True Negative)
真实值是negative,模型认为是negative的数量
sklearn的混淆矩阵
from sklearn.metrics import confusion_matrix
def Confusion_Matrix(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
return confusion_matrix(a,b)2,准确率Accuracy
准确率是分类正确的样本占总样本个数的比例
准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有 99% 的样本为正样本,那么分类器只需要一直预测为正,就可以得到 99% 的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
import numpy as np
def Accuracy(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
return np.sum(a==b)/len(a)
3,精确率Precision
精确率指预测为正的样本中有多少是真正的正样本(找得对)
模型预测为正的样本中实际也为正的样本占被预测为正的样本(正确的和错误的)的比例。计算公式为:
分母是模型预测为正的样本数目
import numpy as np
def Precision(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
return (a[b==1]==1).sum()/(b==1).sum()
4,召回率Recall
召回率的是样本中的正例有多少被预测正确了(找得全)所有正例中被正确预测出来的比例
分母是样本正例的数目
import numpy as np
def Recall(a, b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
return (a[b==1]).sum()/(a==1).sum()
5,F值 f1_score
综合反映精确率和召回率两个趋势的指标。
from sklearn.metrics import precision_score, recall_score
def F1_score(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
p=precision(a,b)
r=recall(a,b)
return 2*p*r/(p+r)
6,ROC
ROC是一种显示分类模型在所有分类阈值下的效果的图表
ROC反映了系统中如果提高一点负例的错误率,能带来多少正例正确率的提高
就像在核酸检测中,通过降低阈值误诊一些阳性,可以带来多少阳性的正确识别
真阳性率TPR:
假阳性率FPR:
#绘制ROC
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
def draw_ROC(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测为正例的概率。
fprs,tprs,_ = roc_curve(a,b)
plt.step(fprs,tprs)
sklearn分类的概率预测中:proba=model.predict_proba(X)返回类别的概率
这里我们二分类(0,1),函数返回的就是一列0的概率和一列1的概率,那么预测为正例的概率就为第一列的所有:proba[:,1]
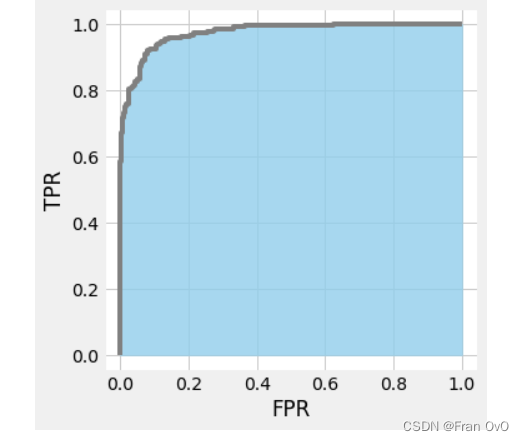
7,AUC值
AUC(Area Under Curve) 就是 ROC 曲线下的面积大小,它能够量化地反映基于 ROC 曲线衡量出的模型性能。AUC 的取值一般在 0.5 和 1 之间,AUC 越大,说明分类器越可能把实际为正的样本排在实际为负的样本的前面,即正确做出预测。
from sklearn.metrics import roc_auc_score
roc_auc_score(y, probas_true)#预测为正例的概率这个AUC值越大越好
8,PR曲线
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系

1:曲线越靠近右上方,性能越好。(例如上图黑色曲线)
2:当一个曲线被另一个曲线完全包含了,则后者性能优于前者。(例如橘蓝曲线,橘色优于蓝 色)
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
def draw_PR(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测为正例的概率。
ps,rs,_ = precision_recall_curve(a,b)
plt.step(rs,ps)

二、回归问题的评价方法
1,均方误差MSE
def MSE(a,b):
# a:numpy一维数组,形状是(n,),表示标签。
# b:numpy一维数组,形状是(n,),表示预测结果。
return ((a-b)**2).mean()或者
from sklearn.metrics import mean_squared_error
mean_squared_error(y, y_pred) 2.决定系数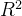
R2 = 1 - ((y-y_pred)**2).sum() / ((y-y.mean())**2).sum()或者
from sklearn.metrics import r2_score
r2_score(y, y_pred)3,MAE
MAE = (np.abs(y - y_pred)).mean()或者
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y, y_pred)三,评估方法
一、留出法
-
train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)将全量数据集划分成互不相交的两部分,其中数据量较大的一部分(一般占总数据量的2/3到4/5)作为训练集,另一部分作为测试集。在划分数据时,应保持数据分布在训练集合测试集中的一致性(可使用分层抽样等方法);同时,考虑到划分随机性的影响,应该多次重复划分。
二、交叉验证法(k折为例)
-
cross_val_score
-
KFold
将全量数据集划分为互不相交且数据量相等的k份,进行k次模型评估。第i次(i=1,2,...,k)取第i份数据作为测试集,其余数据作为训练集。将k次模型评估的结果取平均,作为最终的模型评估结果。k与数据量相等时的k折交叉验证称为留一法。
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
cv = KFold(5, shuffle=True)
model_rfc_1 = RandomForestClassifier()
cross_val_score(model_rfc_1, X, y, cv=cv, scoring='accuracy')
cross_val_score(model_rfc_1, X, y, cv=cv, scoring="f1")![]()
![]()
这部分还有很多东东,包含很多交叉验证的方法如:留一交叉LOO,留P交叉LPO,随机排列交叉验证,组k-fold等等
三、bootstrap自助法(重采样)
对原始的全量数据集(样本量为m)用有放回重复抽样的方法抽取样本量为m的新样本。当m很大时,原始数据集中某个样本在m次抽取中均不被抽中的概率(也即某数据不进入新样本的概率)约为0.368,因此原始数据集中大约有36.8%的数据不在新样本中。以新样本为训练集,以那剩余约36.8%的数据为测试集。
四、搜索超参数
这有点深度学习了。。。就像动态学习率这个超参数
-
GridSearchCV
网格搜索是在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果(暴力搜索)。
原理:在一定的区间内,通过循环遍历,尝试每一种可能性,并计算其约束函数和目标函数的值,对满足约束条件的点,逐个比较其目标函数的值,将坏的点抛弃,保留好的点,最后便得到最优解的近似解。
为了评价每次选出的参数的好坏,我们需要选择评价指标,评价指标可以根据自己的需要选择accuracy、f1-score、f-beta、percision、recall等。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
cv = KFold(5, shuffle=True)
param_grid = {'max_depth': [5, 10, 15], 'n_estimators': [10, 20, 30]}
model_rfc_2 = RandomForestClassifier()
grid_search = GridSearchCV(model_rfc_2, param_grid, cv=cv, scoring='accuracy')
grid_search.fit(X, y)
print(grid_search.best_score_)
print(grid_search.best_params_)![]()
GridSearchCV(
estimator,param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True,
refit=True,cv=None, verbose=0, pre_dispatch='2*n_jobs',
error_score='raise',return_train_score=True)参数:
- estimator:所使用的分类器
- param_grid:值为字典或者列表,需要最优化的参数的取值范围,如paramters = {'n_estimators':range(10,100,10)}。
- scoring :准确度评价指标,默认None,这时需要使用score函数;或者如scoring='roc_auc'。
- cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
这东西已经是大招级别的东西了
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import GridSearchCV
def Student(X_train, y_train, X_test):
# X_train:numpy二维数组,由n个样本、k个特征组成的数据矩阵,形状是(n,k)。
# y_train:numpy一维数组,由n个数据组成的标签,形状是(n,)。
# X_test:numpy二维数组,由m个测试、k个特征组成的数据矩阵,形状是(m,k)。
model = AdaBoostClassifier(n_estimators=10,random_state=10)
param_grid = {'n_estimators': range(10,100,10)}
grid_search = GridSearchCV(model, param_grid, scoring='accuracy')
grid_search.fit(X_train,y_train)
y_pred = grid_search.predict(X_test)
return y_pred
![]()
这么写也是分分钟过案例,虽然用AdaBoostClassifier或者XGBClassifier已经够了
四,复习题
eg1

假阳性率FPR,其他全是正例样本的
选B
eg2
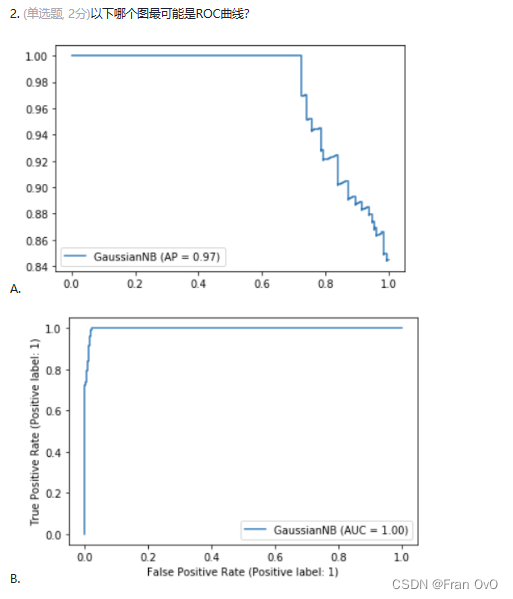
选B
eg3
 模型对正例的判断中=模型判断的正例,Precision
模型对正例的判断中=模型判断的正例,Precision
选A
eg4


选B
eg5
逻辑回归是一个分类模型,它用了决定系数R2就不行
选B
eg6

这道题有点狗,不按常理。。。
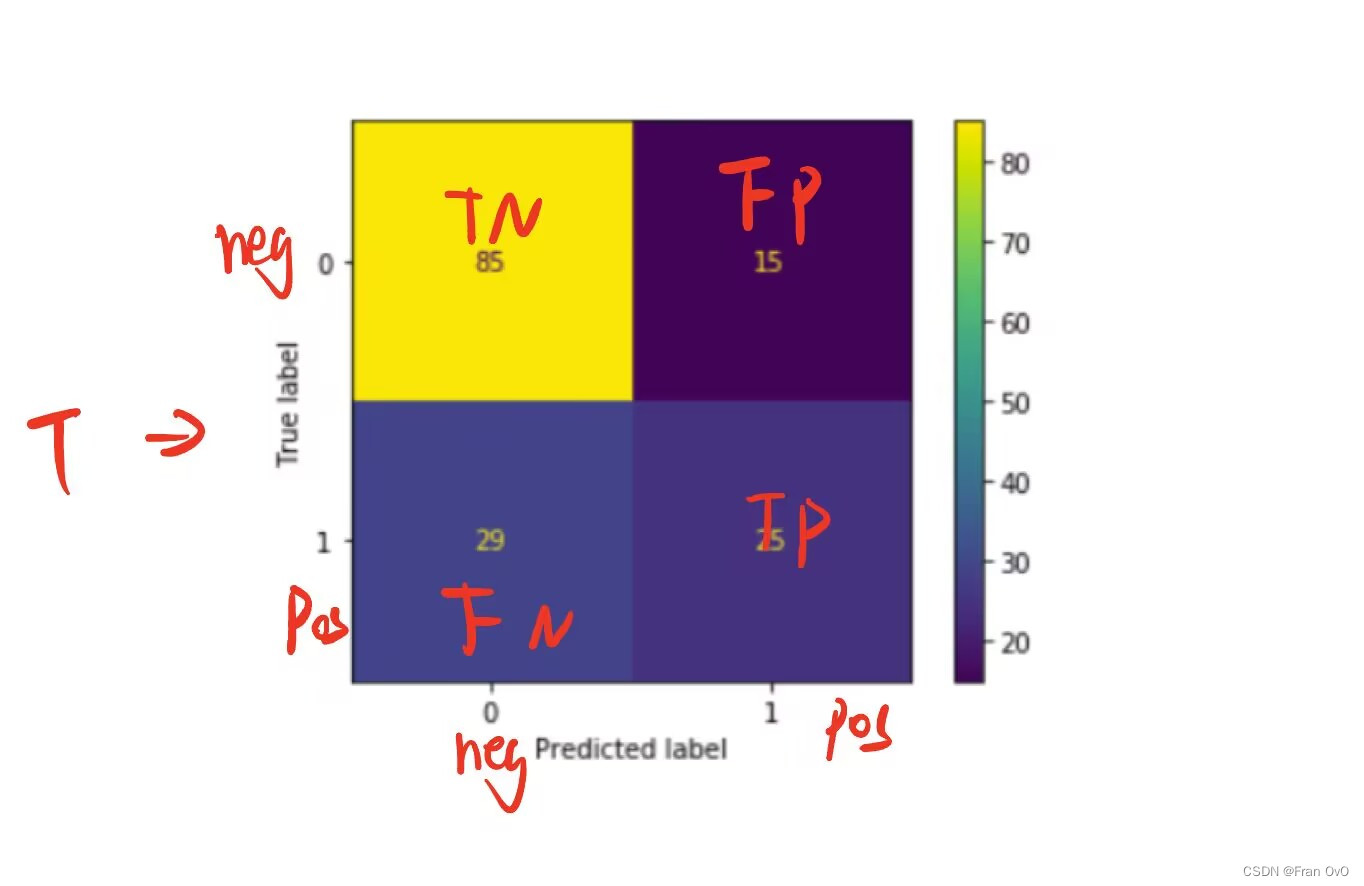
eg7

300-0.8*300=60
eg8
选C
Accuracy——找的准(不够这个要看数据比例了,如果都是正例,模型都预测正例,那acc就不会低)
precision——找的对
,这个公式目的就是让FP误判为正样本越小,正判TP越大
recall——找的全 (比较关注正例)
,这个公式目的就是让TP更靠近总样例,误判为负样本更少
因为他是正确被检测的正例占正例的多少
戴口罩肯定要找的对才行,像 核酸检测就要看他阳性找的全不全

选D
eg9

平方肯定大于等于零
选D
eg10

这个更看重准确率
选B
eg11
















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









