









摘要:
进化算法已被证明在解决多目标优化问题方面非常强大,其中非支配排序是一种广泛采用的选择技术,然而,这种技术在计算上可能非常昂贵,特别是当种群中个体数量变大时。这主要是因为在大多数现有的非支配排序算法中,一个解决方案需要与所有其他解决方案进行比较,然后才能被分配到一个前沿。在这项工作中,我们提出了一种新颖的计算效率高的非支配排序方法,称为高效非支配排序(ENS)。在ENS中,一个待分配到前沿的解决方案只需与已经被分配到前沿的解决方案进行比较,从而避免了许多不必要的支配比较。基于这种新方法,我们提出了两种非支配排序算法。理论分析和实证结果都表明,基于ENS的排序算法在计算效率上优于现有的非支配排序方法。
关键词: 进化多目标优化、非支配排序、帕累托最优、计算复杂度
1. 引言
大多数实际优化问题的特点是多个目标,这些目标经常相互冲突。为了求解这种多目标优化问题 (MOP),需要实现一组最优解,称为帕累托最优解,而不是单个最优解。最经典优化方法在求解 MOP 时效率低下,因为它们通常在一次运行中只能找到一个帕累托最优解,这意味着必须多次应用这种方法才能获得帕累托最优解集。
在过去的 20 年中,已经开发了多种进化算法来处理 MOP,例如 PESA-II [1]、NSGA-II [2]、SPEA2 [3] 和 M-PAES [4] 等。这些多目标进化算法 (MOEA) 能够在一次运行中找到一组帕累托最优解。尽管已经采用了各种选择方法[5],但大多数 MOEA 采用基于帕累托的方法,即使用帕累托优势比较候选解的质量。在各种优势比较机制中,非支配排序[2]已被证明对于寻找帕累托最优解非常有效。为了有效地将搜索过程中发现的非支配解决方案存储在存档中,已经做了大量工作[6],[7]。非支配排序是一种过程,其中种群中的解根据其优势关系被分配到不同的战线。在不失去普遍性的情况下,我们假设种群 P 中的个体可以分为 K 帕累托前沿,表示为 Fi, i = 1, . . . , K。根据非支配排序,种群P中所有非支配解均被分配到前沿F1;然后将 P − F1 中的非支配解(即通过删除分配给前 F1 的解而得出的一组解)分配给前 F2。非支配排序的思想最早是在[8]中提出的,作为进化多目标优化的选择策略,该算法在多目标遗传算法中实现,称为非支配排序 GA (NSGA) [9]。NSGA中的非支配排序具有 O(MN3)的时间复杂度和 O(N)的空间复杂度,其中M是目标数,N是总体中的解数。[2]提出了一种更快的非支配排序版本,称为快速非支配排序,其中时间复杂度降低到O(MN2)。然而,快速非支配排序所需的存储空间比 NSGA 的非支配排序更大,增加到 O(N2)。Jensen[10] 对非支配排序采用分而治之的策略,其时间复杂度为 O(N logM−1 N)。Tang等 [11] 提出了一种基于竞技场原理的新型非支配排序方法,即每个获胜者将成为下一个被挑战的“竞技场主持人”。该方法已被证明具有与快速非支配排序相同的时间复杂度,而实证结果表明,该方法在计算效率方面优于快速非支配排序,因为它在某些最佳情况下可以达到时间复杂度 O(MN√N)。Clymont和Keedwell[12]提出了两种改进的非支配排序方法,称为攀爬排序和演绎排序,其中可以根据记录的比较结果推断出解决方案之间的一些优势关系。
在这项工作中,我们提出了一种新的、计算效率高的非支配排序方法,称为高效非支配排序(ENS)。ENS采用了与上述方法不同的想法。主要区别在于,现有的非支配排序方法通常在将解分配给前沿之前将其与总体中的所有其他解进行比较,而 ENS 仅将其与已分配给前沿的解进行比较。这是由于在 ENS 中,在应用 ENS 之前,将总体分类在一个目标中。因此,添加到前端的解决方案不能支配之前添加的任何解决方案。因此,ENS可以避免大量的冗余优势比较,从而显著提高计算效率。理论分析表明,ENS方法的空间复杂度为 O(1),小于现有的所有非支配排序方法。同时,ENS的时间复杂度在良好情况下为 O(MN log N),远低于现有算法。即使在最坏的情况下,ENS的复杂度也为 O(MN2),这与快速非支配排序相同。实验结果表明,ENS的计算效率优于现有技术。
本文的其余部分组织如下。在第二节中,我们简要回顾了几种广泛使用的非支配排序方法,并分析了它们的计算复杂性。在第三节中,我们提出了一种新的非支配排序方法ENS,并在此基础上开发了两种非支配排序算法。 然后分析了两种算法的计算复杂度。仿真结果在第四节中给出,以实证比较两种基于ENS的非支配排序算法与三种最先进的方法。最后,结论和评论见第五节。
2. 相关工作
在本节中,我们回顾了一些流行的非主导排序方法,并对其计算复杂性进行了分析。
A.非支配排序方法
回顾了一些在 MOEA 中广泛使用的非支配排序方法。首先,NSGA 中的非支配排序执行如下:每个解与种群中的所有其他解进行比较,未被任何其他解所支配的解被分配到前沿F1。所有分配到F1的解都被临时从种群中移除。然后,剩余种群中的每个解与其他解进行比较,所有非支配解被分配到前沿F2。这个操作重复进行直到所有解都被分配到前沿。这种方法包含了很多冗余的比较,也就是说对于两个解之间的比较可能会执行多次。该方法的时间复杂度为O(
M
N
3
MN^3
MN3),这使得 NSGA 对于大规模种群来说非常耗时和计算效率低下。唐等人[11]采用了竞技场原则将解分配到一个前沿,在实证评估中显示出比快速非支配排序和Jensen排序具有更好的计算效率。该方法随机从种群中选择一个解作为"竞技场主机",然后将种群中的所有剩余解与"竞技场主机"进行比较。支配"竞技场主机"的解将变为新的"竞技场主机",替代当前的主机。该方法的时间复杂度和空间复杂度分别为 O(
M
N
2
MN^2
MN2) 和O(N)。Clymont 和 Keedwell [12] 提出了两种非显性排序方法:爬行排序和演绎排序。如 [12] 所示,演绎排序通常比爬行排序表现更好。演绎排序通过记录比较结果来推断解决方案之间的优势关系,从而避免一些不必要的比较。演绎排序具有 O(
M
N
2
MN^2
MN2) 的时间复杂度和 O(N) 的空间复杂性,其表现优于其他方法,例如快速非显性排序。
还有一些其他的非支配排序方法受到不同思想的启发,如全优化器的非支配秩排序[16]、更好的非支配排序[17]、基于免疫识别的算法[18]、快速排序[19]、基于排序的算法[20]和基于分治的非支配排序算法[13]。这些方法大多在处理目标数量较少的《议定书》缔约方会议时是有效的,但是,随着目标数量的增加,其效率往往会严重下降。
B. 对现有方法的分析
解决方案之间的优势比较是非主导排序的主要操作,即所需的比较次数决定了非主导排序方法的效率。现有的大多数非支配排序方法都侧重于减少比较次数以提高其计算效率。原因是解决方案之间的一些优势比较是不必要的,可以避免。仔细观察,我们发现一个优势比较的结果可以分为以下四种情况,假设将解
p
m
p_m
pm与解
p
n
p_n
pn进行比较:

情况1:
p
m
p_m
pm由
p
n
p_n
pn主导,或
p
n
p_n
pn由
p
m
p_m
pm主导。
情况2:
p
m
p_m
pm和
p
n
p_n
pn是非支配的,并且它们属于同一个前沿
F
i
F_i
Fi,其中
F
i
F_i
Fi是当前的前沿(即正在分配解的前沿)。
情况3:
p
m
p_m
pm和
p
n
p_n
pn是非支配的,并且它们属于同一个前沿
F
i
F_i
Fi,其中
F
i
F_i
Fi不是当前的前沿。
情况4:
p
m
p_m
pm和
p
n
p_n
pn是非支配的,但它们属于不同的前沿。
回想一下,如果一个解在当前种群中没有被任何其他解所支配,那么它会被分配到当前的前沿。在情况1中,如果解 p m p_m pm支配解 p n p_n pn,那么解 p n p_n pn就不属于当前的前沿,因此我们不再需要对解 p n p_n pn与当前种群中的其他解进行额外比较,这意味着如果执行这样的比较,则属于冗余操作。在情况2中,解 p m p_m pm和 p n p_n pn都属于当前的前沿,因此不存在可以支配解 p m p_m pm或 p n p_n pn的解,需要对解 p m p_m pm和 p n p_n pn进行比较以验证其中是否有一个支配另一个。
实际上,当前前沿中的所有解都应该互相比较,以确保它们彼此之间都不被支配。在情况3中,解 p m p_m pm和解 p n p_n pn都不属于当前的前沿,这意味着至少存在一个解支配解 p m p_m pm和一个解支配解 p n p_n pn,因此可以跳过解 p m p_m pm和解 p n p_n pn之间的比较。在情况4中,由于至少存在一个解支配解 p m p_m pm或解 p n p_n pn,因此解pm和解 p n p_n pn的比较是不必要的。图3中展示了可能的四种比较情况。
如图3所示,对于非支配排序,在情况1和情况2中无法避免比较,这些比较被称为必要比较。情况1中的必要比较是指不同前沿中解之间的比较,而情况2中的必要比较是指同一个前沿中解之间的比较。情况1和情况2中必要比较的数量是任何非支配排序算法所需支配比较的理论最小数量。如果非支配排序方法确定解所属前沿的方式是从第一个前沿开始逐个检查,例如在图1中从F1到F4,那么情况1中必要比较的数量可以如下计算。假设种群由N个解组成,并分成K个前沿,假设第 i 个前沿
F
i
F_i
Fi包含
N
i
N_i
Ni个解,其中1 ≤ i ≤ K。因此,我们有 N1 + N2 + . . . + NK = N。如果一个解
p
n
p_n
pn属于前沿
F
i
F_i
Fi,那么至少会在前面的 i−1个前沿中找到一个支配
p
n
p_n
pn的解。这意味着解
p
n
p_n
pn需要进行 i−1 次情况1的比较。由于
F
i
F_i
Fi中有
N
i
N_i
Ni个解,因此
F
i
F_i
Fi前沿需要进行(i−1)×
N
i
N_i
Ni 次情况1 的比较。因此,在不同前沿的解之间,必要的支配比较总数为:
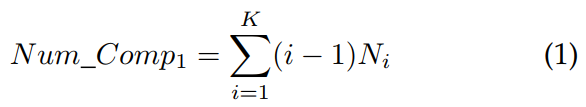
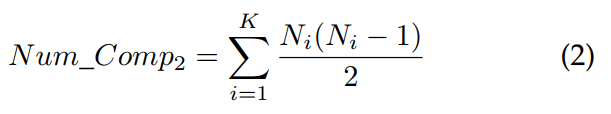
大多数流行的非支配排序方法的支配比较总数远高于Num Comp1和Num Comp2的总和。通过上述讨论,我们可以发现非支配排序方法的计算效率的进一步改进应集中在减少情况1、3和4中的不必要比较。实际上,大多数现有的改进非支配排序方法已成功消除了情况1中的不必要支配比较,然而仍会进行许多属于情况3和4的不必要比较。
以一个例子为例,我们考虑在图4中展示的种群中进行的演绎排序中的比较。该种群包含了一个双目标最小化问题的六个候选解,每个解都用pi(f1, f2)表示,其中i = 1, 2, . . . , 6,f1和f2分别是解pi的两个目标的值。在这个例子中,这六个候选解分别是p1(5, 4), p2(6, 3), p3(7, 2), p4(1, 6), p5(2, 5), p6(3, 1)。
根据图4所示,该种群中存在两个前沿,其中解p4、p5和p6属于第一个前沿F1,而解p1、p2和p3属于第二个前沿F2。演绎排序执行以下比较来将解分配到这两个前沿中。首先,将解p1与种群中的每个其他解逐一进行比较。解p1首先与解p2进行比较。由于p1不被p2支配,演绎排序继续对p1与p3进行比较。比较结果显示p1不被p3支配。同样地,p1将与p4和p5进一步进行比较,得出结论p1既不被p4支配也不被p5支配。然后,p1与p6进行比较,发现p1被p6支配,这意味着p1不属于当前前沿F1。到那时,解p1将不再参与演绎排序中前沿F1的进一步比较。
在上述过程中,进行了以下支配比较:三个情况3的比较(p1与p2、p3的比较),两个情况4的比较(p1与p4、p5的比较),以及一个情况1的比较(p1与p6的比较)。在p1与所有其他解进行比较后,演绎排序开始考虑解p2。支配比较将继续进行,直到所有解都被分配到一个前沿中。表格I列出了在图4所示的种群中,演绎排序进行的所有比较。
根据表格 I,我们可以清楚地看到演绎排序执行了许多不必要的比较,这些比较属于情况3和情况4。在这些不必要的比较中,有几个是重复的比较,比如p1和p2之间的比较。事实上,演绎排序中的所有重复比较都属于情况3。在这项工作中,我们提出了一种新的非支配排序算法,采用了与图2中所示不同的策略,旨在避免重复比较,从而大大减少了不必要的比较的数量。
在这里,我们提出了一种新的高效非支配分拣策略,称为ENS,它在概念上与大多数现有的非支配分拣方法不同。ENS 方法的主要思想如图 5 所示。通过比较图2和图5,我们可以看到ENS方法逐个确定每个解所属的前沿,而大多数现有的非支配排序方法会将同一前沿上的所有解一起确定。独立确定每个解所属前沿的主要优点是它可以避免重复的比较,因为在这种方法中,要分配的解只需要与已经分配到一个前沿的解进行比较。完成对种群P中个体的排序后,ENS开始逐个将解分配给已排序的种群P中的前沿(front)。从第一个解p1开始,直到最后一个解pN。正如我们所知,如果一个解被分配到一个前沿,那么它至少被前面一个前沿中的一个解所支配。正如上面所指出的,一个解永远不会被已排序种群P中的任何后续解所支配。因此,仅需将一个解与已经分配到前沿的解进行比较,就可以确定该解所属的前沿。图6显示了一个待分配解与已经分配到前沿的解之间可能的关系。实际上,如果一个解pn被分配到前沿Fi,则Fi必须满足以下两个条件:
- 在已经分配的每个前沿Fj中至少存在一个解,这个解支配着解pn,其中1 ≤ j ≤ i - 1;
- 在任何已分配的前沿Fk中,不存在支配解pn的解,其中k ≥ i。
通过满足上述两个条件来确定解所属的前沿,以此方式可以确定解所属的前沿。接下来,我们在ENS框架下介绍了两种搜索满足上述两个条件的前沿的策略,一个是使用顺序搜索策略(称为ENS-SS),另一个是使用二分搜索策略(ENS-BS)。
A. 顺序搜索策略
顺序搜索的伪代码呈现在算法2中。这种搜索策略的思路非常直观。对于解
p
n
p_n
pn,算法首先检查是否存在一个解被分配到第一个前沿F1,并且支配解
p
n
p_n
pn。如果不存在这样的解,则将
p
n
p_n
pn分配到前沿F1。如果
p
n
p_n
pn被F1中的任何解所支配,则开始将pn与分配到F2的解进行比较。如果F2中没有任何解支配
p
n
p_n
pn,则将
p
n
p_n
pn分配到F2。如果
p
n
p_n
pn没有被分配到任何现有的前沿中,则创建一个新的前沿,并将pn分配给这个新前沿。
在检查一个前沿是否有一个解支配解pn时,有一个小技巧。回想一下,分配给已存在前沿的解也按照种群的相同顺序进行排序。因此,解 p n p_n pn与分配给该前沿的解之间的比较应该从该前沿中的最后一个解开始,一直到第一个解结束。如果一个解被分配到该前沿并支配解 p n p_n pn,这个技巧往往会导致更少的比较,因为已排序前沿末尾的解更有可能支配解 p n p_n pn。因此,可以避免不必要的比较。
对于双目标优化问题,这里提出的方法在计算上比现有的非支配排序方法更高效。事实上,如算法2所示,只需进行一次比较就足以确定待分配解属于现有前沿。原因如下:在排序过程中,分配给前沿的解按照第一个目标的升序进行排序,这意味着这些解的第二个目标按降序排列,因为它们相互之间是非支配的。这意味着,如果待分配解 p n p_n pn被现有前沿中的一个解所支配,那么它肯定被该前沿中的最后一个解所支配,因为最后一个解在该前沿中的所有解中具有第二个目标的最小值。因此,对于双目标优化问题,该方法仅通过对该解与每个前沿中的最后一个解进行比较,就可以确定解所属的前沿编号。
在表II中,我们列出了ENS使用顺序搜索策略(ENS-SS)对图4中给出的种群进行非支配排序所进行的比较。如表中所示,ENS-SS总共只需要进行九次比较,这个数量远远小于演绎排序所需的比较次数,参见表I。读者可以轻松验证ENS-SS中不存在属于情况3的比较。这意味着ENS-SS不会执行任何重复的比较,这可以归功于图5所展示的ENS策略。需要注意的是,虽然ENS-SS对图4所示的种群不执行任何属于情况4的比较,但是对其他种群来说,这种比较可能会出现。
B. 二元搜索策略
二分搜索策略的伪代码呈现在算法3中。与顺序搜索不同,二分搜索策略从检查中间的前沿 F⌊L/2⌋ 开始,而不是第一个前沿F1,其中L是到目前为止已创建的前沿数量,即在分配解
p
n
p_n
pn之前。如果解pn不被前沿 F⌊L/2⌋ 中的任何解所支配,则将解
p
n
p_n
pn与前沿 F⌊L/4⌋中的解进行比较。否则,将解
p
n
p_n
pn与前沿 F⌊3L/4⌋ 中的解进行比较。通过这种方式,二分搜索在检查了⌈log(L + 1)⌉个前沿后可以确定解
p
n
p_n
pn所属的前沿。如果已经检查了最后一个现有的前沿FL并且
p
n
p_n
pn不属于该前沿,则将创建一个新的前沿
F
L
+
1
F_{L+1}
FL+1,并将解
p
n
p_n
pn分配给这个新前沿。在这里采用的二分搜索策略通常比顺序搜索策略更有效,因为它需要在种群中检查较少的前沿。但是,这并不意味着二分搜索策略在前沿分配方面总是能执行比顺序搜索策略更少的比较。在二分搜索中,可能需要检查多个没有任何解支配解pn的前沿。所有这些被检查的前沿中的解都必须与pn进行比较。而在顺序搜索中,最多只需检查一个不包含任何支配解pn的前沿。因此,尤其对于由少量前沿组成的种群而言,二分搜索策略并不总是在比较的数量上优于顺序搜索策略。
在这里同样可以采用在顺序搜索策略中用到的比较同一个前沿中的解的小技巧。这意味着比较应从待检查前沿中最后一个分配的解开始。由于图4中的种群只包含两个前沿,所以二分搜索策略将执行与表II中顺序搜索策略相同数量的比较,读者可以轻松验证这一点。
C. 计算复杂度分析
在本部分,我们简要分析了所提出的两种基于ENS的算法的计算复杂性。 在接下来的分析中,我们假设对包含N个解和M个目标的种群进行非支配排序。 如前一部分所述,ENS方法包括两个主要步骤。首先,按照目标将种群按升序排序。 其次,将排序后的解分配到前沿。我们可以在第一步采用堆排序[21],其时间复杂度为O(N log N),空间复杂度为O(1)。 如果采用顺序搜索将解分配到前沿,第二步的最坏情况时间复杂度为O(MN2),即当种群中的所有N个个体互相非支配时。因此,种群中的所有解将被分配到一个前沿。如方程(1)所示,当所有解都是非支配的时候,在顺序搜索策略中,不同前沿中的解之间的比较次数将会是
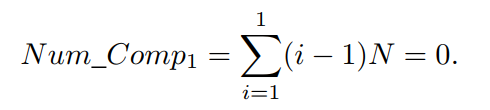
对于同一个前沿中的N个解,在顺序搜索策略中所需的比较次数,如方程(2)所示,为
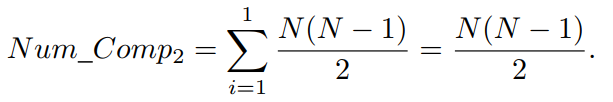
在最坏情况下,顺序搜索策略不会进行任何不必要的比较,因为种群中的每对两个解都已经进行了比较。因此,顺序搜索策略执行的总比较次数为
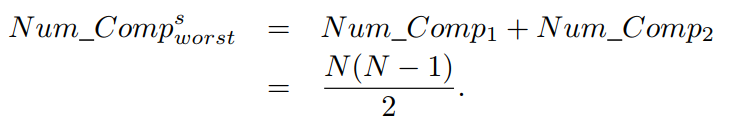
由于每个解决方案都有 M 个目标,因此顺序搜索策略具有最坏情况下的时间复杂度,如下所示
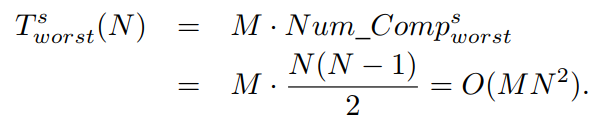
在最好的情况下,ENS-SS的时间复杂度为O(MN√N)。这种情况发生在N个解属于⌈√N⌉个前沿,每个前沿大约有⌈√N⌉个解,并且每个前沿中的解都被前一个前沿中的所有解所支配。根据方程(1),ENS-SS中不同前沿中的解之间的比较次数将为
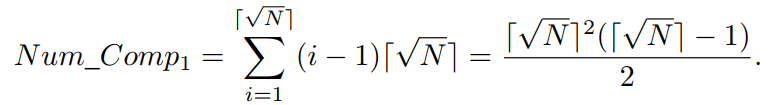
在⌈√N⌉个前沿中的每一个前沿中,需要对前沿中的⌈√N⌉个解中的任意两个解进行比较。如方程(2)所示,ENS-SS需要在同一个前沿中的解之间进行的比较次数为
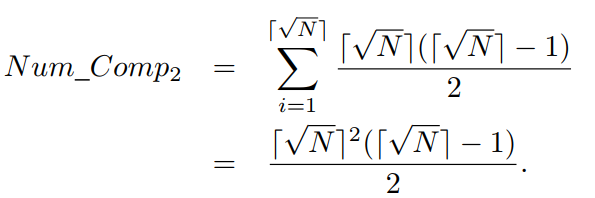
于每个前沿中的解都被前一个前沿中的所有解所支配,在最好的情况下,顺序搜索策略不会执行任何不必要的比较。因此,在最好的情况下,ENS-SS进行非支配排序时执行的总比较次数将会是
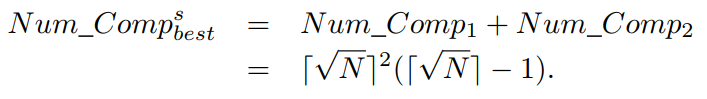
因此,在最好的情况下,ENS-SS的时间复杂度为
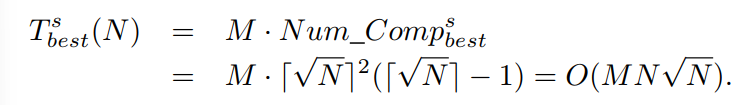
ENS-BS的最坏情况时间复杂度与ENS-SS的最坏情况相同,在这种情况下,给定种群时ENS-SS和ENS-BS都需要执行相同数量的比较。因此,ENS-BS的最坏情况时间复杂度为
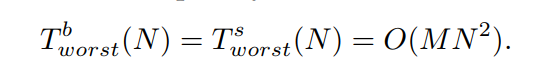
ENS-BS的最好情况发生在种群中的N个解属于N个不同的前沿的情况下。在这种情况下,任何一个前沿中的解都不需要与待分配的解进行比较。通过方程(2),我们可以看到ENS-BS中同一个前沿中解之间的比较次数为
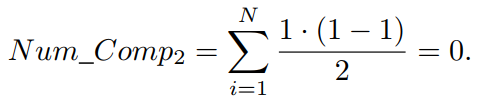
在ENS-BS中,如果要将一个解分配到一个前沿,这个解可能需要与许多已存在的前沿中的解进行比较,但不是全部。这意味着如果使用二分搜索策略,不能简单地使用公式(1)计算待分配解与已存在前沿中解之间的比较次数。在最好的情况下,每个前沿只包含一个解,因此解pn(1 ≤ n ≤ N)应被分配到前沿Fn。为了实现这一点,需要检查⌈log n⌉个前沿,并进行⌈log n⌉次比较。采用二分搜索策略的不同前沿中解之间的比较次数为
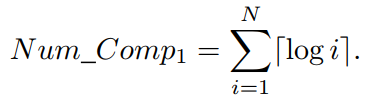
Table III呈现了基于ENS的非支配排序算法(ENSSS和ENS-BS)的时间和空间复杂度,以及三种现有的流行非支配排序算法的复杂度,分别是推导排序(deductive sort),竞技场原则(arena’s principle)和快速非支配排序(fast non-dominated sort)。从表III可以看出,基于ENS的算法与这三种现有的非支配排序方法具有相同的最坏情况时间复杂度O(MN^2)。需要注意的是,快速非支配排序的最佳情况时间复杂度和最坏情况时间复杂度相同,而推导排序和竞技场原则的最佳情况时间复杂度可以降低到O(MN√N)。ENS-SS的最佳情况时间复杂度与推导排序和竞技场原则相同,而ENS-BS在最佳情况时间复杂度上取得了提升,为O(MN log N)。我们应该强调的是,这并不意味着ENS-BS的效率平均而言比ENSSS更好。另一方面,ENS-SS和ENS-BS都可以实现比三种现有方法更低的空间复杂度。















 8247
8247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









