







SRAM是一种高速、易失性存储器,具有读写速度快、功耗低等优点。基于SRAM的存内计算技术通过修改SRAM单元的结构,在存储数据的同时实现计算功能。这种技术能够有效地减少数据传输延迟,提高计算速度,并且功耗较低。然而,基于SRAM的存内计算技术也面临着一些挑战,如存储容量的限制、计算精度的问题等。
基于 SRAM 的存内逻辑运算
基于SRAM的存内逻辑运算是存内计算(In-Memory Computing, IMC)领域的一个重要方面,它将数据处理和存储集成在同一个芯片上,以减少数据在处理器和存储器之间的传输,降低功耗并提高计算效率。以下是关于基于SRAM的存内逻辑运算的详细解释:
- 逻辑运算的实现:
- SRAM的逻辑运算是通过激活同一列的多个存储单元来实现的。这些存储单元的字线被同时激活,然后通过灵敏放大器感测位线电压,从而得到存储单元存储比特的逻辑运算结果。
- 在增加额外的逻辑门后,SRAM可以实现更复杂的逻辑运算,如逻辑或非(NOR)和逻辑与非(NAND)运算。
- 创新架构:
- 研究者们提出了多种创新的SRAM存内计算架构。例如,Aga等人提出了一种新的存内计算架构,通过添加解码器和使用单端灵敏放大器实现了逻辑异或(XOR)运算。
- Dong等人则提出了一种4+2T的SRAM单元,这种单元相比传统的6T SRAM单元具有更好的噪声容限。
- 针对传统6T SRAM单元存在的读写干扰和存储内容翻转等问题,研究者们提出了8T和10T SRAM单元。Agrawal等人使用8T SRAM单元和8+T SRAM单元的解耦读写路径,成功实现了存内布尔运算,包括逻辑与非、逻辑或非、逻辑异或等逻辑运算。
- 性能优势:
- 与传统的SRAM阵列相比,新的存内计算阵列具有更高的密度和更低的功耗,为存内计算提供了更广阔的发展空间。
- 基于SRAM的存内逻辑计算技术不断创新,为计算领域带来了更高的性能和更低的功耗。
- 应用实例:
- 例如,在2021年的ISSCC 16.4中,台积电提出一种基于6T SRAM的全数字存内计算宏,用于卷积神经网络中的乘累加运算。这种应用体现了基于SRAM的存内计算在深度学习和其他高性能计算任务中的潜力。
基于SOP(积之和)逻辑形式的SRAM 存内计算方案如下图。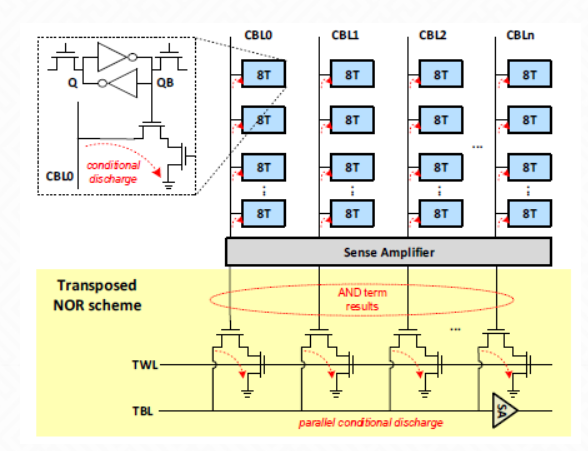
SRAM 应用于神经网络
SRAM(静态随机存取存储器)在神经网络中的应用主要体现在存算一体技术中,它以其高成熟度和高存取速度成为了该领域的热门研究对象。
SRAM存内计算阵列 (a)总体架构 (b)LUT模块 (c)驱动和拷贝模块如下图。
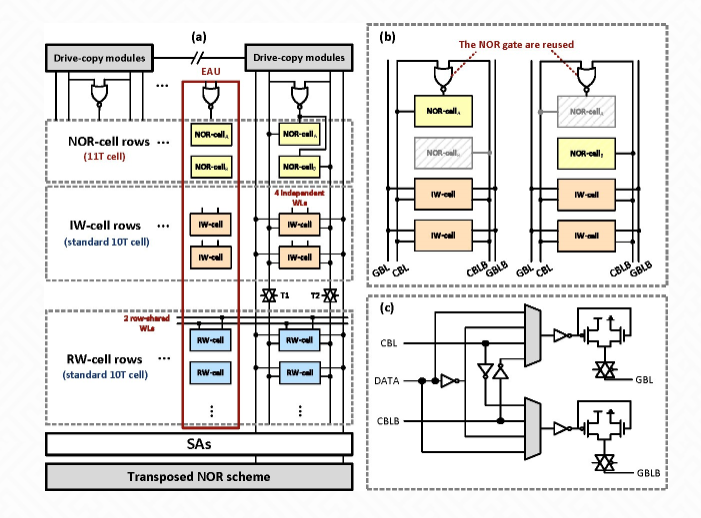
以下是对SRAM在神经网络中应用的具体分析:
- 存算一体技术:
- SRAM存算一体技术在中小算力、端侧、对待机功耗无要求的场景中具有一定的应用价值,如可穿戴设备、边缘计算、无人车等市场。
- 通过将运算单元整合到内存中,SRAM存算一体技术实现了即存即算的数据处理,有效解决了冯·诺伊曼架构中处理器和存储器之间频繁传输数据带来的性能瓶颈和能量消耗问题。
- 技术特点与优势:
- SRAM具有高存取速度,能够快速响应神经网络的计算需求。
- 与传统存储介质相比,SRAM适合IP化,便于在神经网络中实现灵活的存储和计算。
- 通过存算一体技术,SRAM可以减少数据传输的延迟和功耗,提高数据处理的效率和能效。
- 应用挑战:
- 尽管SRAM在存算一体领域具有显著优势,但由于其单元面积大、静态功耗高、易失性、对PVT变化敏感、存储密度低等特点,在应用于一些大算力、大容量、高密度集成的大型神经网络计算场景时会受到较多限制。
- 技术发展趋势:
- 随着技术的不断进步,研究者们正在探索新型的SRAM结构和技术,以克服上述挑战。例如,采用多核架构、优化电源管理、开发新型材料等方法来提高SRAM的性能和可靠性。
- 未来的SRAM存算一体技术将更加注重能效比的提升和计算精度的优化,以满足神经网络在更广泛领域的应用需求。
- 实际案例:
- 某些量产芯片如知存科技的WTM2101和即将量产的WTM8芯片,采用了基于SRAM的存内计算技术,实现了满足端侧算力需求的语音识别和复杂图像处理等功能。这些案例证明了SRAM在神经网络中的实际应用价值和潜力。
SRAM在神经网络中的应用主要体现在存算一体技术上,它通过整合计算逻辑和存储功能在同一个芯片上来提高计算效率和降低功耗。虽然面临一些挑战,但随着技术的不断创新和发展,SRAM在神经网络中的应用前景仍然十分广阔。
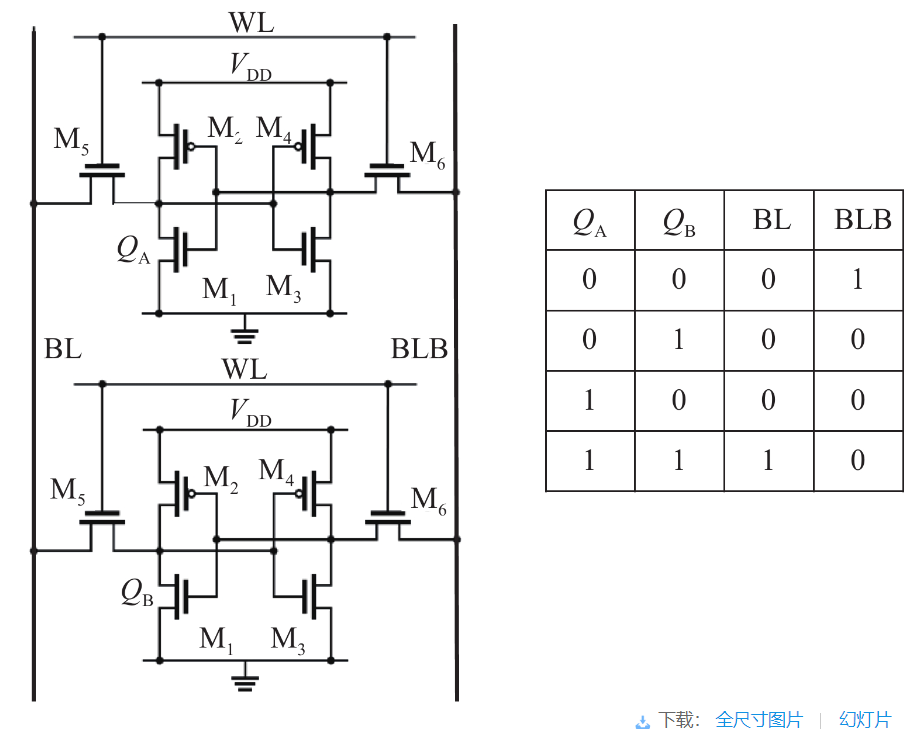
基于SRAM的存内逻辑操作原理图如下。
常见的用于神经网络加速的忆阻器阵列
忆阻器阵列在神经网络加速中的应用,主要得益于其独特的记忆电阻特性和高集成度、低功耗等优点。以下是对常见的用于神经网络加速的忆阻器阵列的详细分析:
- 忆阻器阵列的基本原理:
- 忆阻器,全称记忆电阻器,是一种能够记录电流变化并保持其状态的器件。其阻值由流经的电荷确定,因此具有记忆电荷的作用。
- 忆阻器阵列由多个忆阻器组成,每个忆阻器对应一个突触连接,其强度取决于忆阻器的电阻值。当输入信号经过突触阵列时,不同忆阻器的电阻值将决定信号的传递强度,进而影响突触传输的权重。
- 忆阻器阵列在神经网络加速中的优势:
- 高集成度和低功耗:忆阻器阵列可以实现大规模并行的神经网络,从而支持复杂的智能计算任务。同时,其低功耗特性使得在能源受限的环境中也能有效运行。
- 自适应学习和记忆功能:忆阻器阵列中的突触强度和权重可以通过学习算法进行调整,实现自适应学习和记忆功能。这种特性使得其在模式识别、数据挖掘和智能控制等方面具有广泛的应用前景。
- 模拟生物神经网络:忆阻器突触阵列利用忆阻器的记忆特性模拟生物神经元之间的突触连接,使得其能够模拟生物神经网络的信息处理和记忆功能。
- 应用实例与研究进展:
- 忆阻器阵列已经被广泛应用于人工智能、智能感知和神经形态计算等领域。例如,忆阻器突触阵列可以模拟生物神经网络中的突触连接,实现神经网络的训练和推理。
- 近年来,国内外学者已经成功将忆阻器运用在神经网络的STDP学习法则、Hopfield神经网络、契比雪夫神经网络和深度学习等方面。这些研究为制作具有复杂功能的神经网络硬件电路开辟了新的方向。
- 技术挑战与未来展望:
- 尽管忆阻器阵列在神经网络加速中展现出巨大的潜力,但其在实际应用中仍面临一些挑战,如稳定性、可靠性和可扩展性等问题。
- 未来的研究将致力于解决这些挑战,并进一步探索忆阻器阵列在神经网络加速中的新应用和新方法。例如,通过优化忆阻器的材料和结构来提高其稳定性和可靠性;通过设计更高效的学习算法和硬件架构来提升忆阻器阵列的性能和能效。
忆阻器阵列作为一种新型的神经形态计算器件,在神经网络加速中展现出巨大的潜力和优势。随着技术的不断发展和完善,相信忆阻器阵列将在未来的人工智能和神经形态计算领域发挥越来越重要的作用。

基于NVM的存内计算技术
NVM是一种非易失性存储器,能够在断电后保持数据不丢失。基于NVM的存内计算技术利用NVM的存储特性,在存储单元中直接执行计算操作。这种技术不仅能够解决“内存墙”问题,还能够实现持久化存储,提高系统的可靠性和稳定性。然而,基于NVM的存内计算技术也面临着一些挑战,如写入延迟较长、功耗较高等问题。
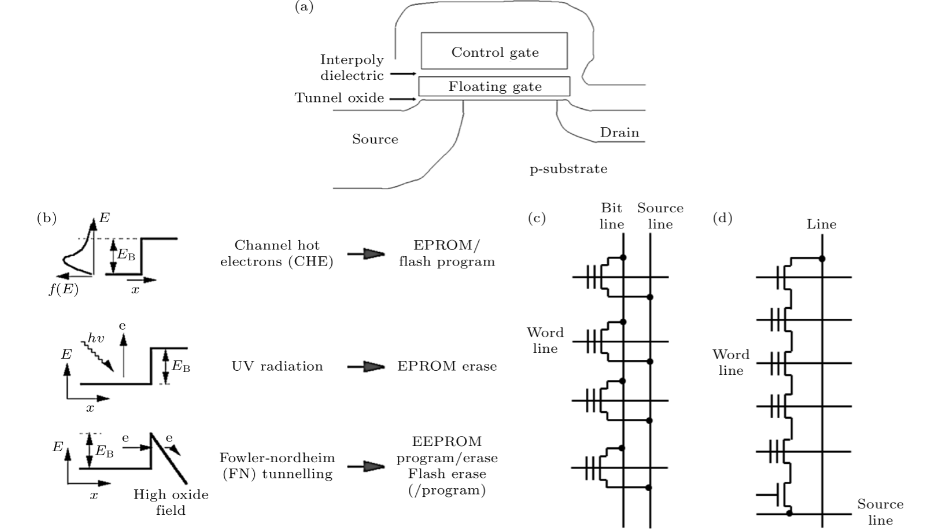
传统NVM器件flash(a) 典型器件结构; (b) flash操作模式与物理机制; (c) NOR 型阵列结构; (d) NAND型阵列结构
基于非易失性存储器(NVM, Non-Volatile Memory)的存内计算技术(In-Memory Computing, IMC)是一种新兴的计算架构,旨在克服传统冯·诺依曼架构中数据传输的瓶颈,通过在存储单元内直接进行计算,极大提高计算效率和能效。以下是基于NVM的存内计算技术的关键概念、优势、挑战及应用:
关键概念
-
非易失性存储器(NVM):
- RRAM(Resistive RAM):利用电阻变化存储数据。
- PCM(Phase-Change Memory):通过材料相变存储数据。
- MRAM(Magnetoresistive RAM):利用磁性材料的电阻变化存储数据。
-
存内计算:
- 通过在存储单元内直接执行计算操作,减少数据在存储器和处理器之间的传输,从而提高计算效率。
- 支持并行计算,特别适合矩阵乘法等神经网络基础操作。
优势
-
高效能计算:
- 由于数据无需频繁在存储器和处理器之间传输,能耗大幅降低,特别适合能效敏感的应用场景,如边缘计算和物联网设备。
-
高并行性:
- NVM支持大规模并行计算,可以同时对大量数据进行操作,极大提高计算速度。
-
数据持久性:
- NVM具备数据持久性,在断电情况下仍能保存数据,这对于需要长时间运行且数据需要高可靠性的应用非常有利。
挑战
-
写入次数和速度:
- 某些NVM技术,如RRAM和PCM,其写入速度较慢且写入次数有限,可能影响系统的整体性能和寿命。
-
精度和可靠性:
- 在存内计算过程中,精度和可靠性是关键问题。需要优化存储单元设计和计算算法,以确保计算结果的准确性。
-
电路复杂度:
- 实现存内计算需要对存储单元进行复杂的电路设计和优化,这增加了设计和制造的难度。
应用实例
-
深度学习加速器:
- 采用NVM存内计算技术的深度学习加速器可以大幅提升神经网络的训练和推理速度。例如,利用RRAM进行矩阵乘法加速,显著提高卷积神经网络(CNN)的处理性能。
-
物联网设备:
- 在资源受限的物联网设备中,NVM存内计算技术可以提供高能效的计算能力,适合实时数据处理和低功耗应用。
-
边缘计算:
- 基于NVM的边缘计算设备可以在靠近数据源的地方进行高效计算,减少数据传输延迟和带宽需求,适合自动驾驶、智能监控等场景。
未来发展方向
-
材料和器件优化:
- 不断优化NVM材料和器件,提升写入速度和寿命,增强可靠性和精度。
-
架构设计:
- 开发更高效的存内计算架构,结合机器学习和算法优化,实现更高的计算性能。
-
标准化和生态系统:
- 建立统一的标准和开发生态系统,推动NVM存内计算技术的广泛应用和普及。
基于NVM的存内计算技术代表了一种革命性的计算架构,能够有效克服传统架构的瓶颈,为高效、低功耗计算提供新的解决方案。随着技术的不断发展和成熟,它将在更多领域展现出广阔的应用前景。
总结
SRAM(静态随机存取存储器)在存内计算技术中的应用展示了显著的潜力和挑战。基于SRAM的存内计算通过整合数据存储和计算功能,减少了数据传输延迟,提升了计算速度,并且功耗较低。其核心优势在于高存取速度和集成度,适用于中小算力、端侧设备如可穿戴设备和边缘计算等场景。
在逻辑运算方面,SRAM通过修改存储单元结构,实现了逻辑与非(NAND)、逻辑或非(NOR)等操作,进一步提高计算效率。研究者提出了创新架构,如8T和10T SRAM单元,以改善传统6T SRAM单元的缺陷,提供更高的噪声容限和稳定性。
SRAM在神经网络中的应用集中在存算一体技术上,通过即存即算的方式优化数据处理效率,降低功耗。然而,其在大算力、大容量神经网络场景中仍面临存储密度低、静态功耗高等限制。实际应用如台积电的基于6T SRAM的计算宏展示了其在深度学习中的潜力。
忆阻器阵列作为另一种存内计算技术,通过高集成度和低功耗特性,支持大规模并行计算,适用于人工智能和神经形态计算。然而,稳定性和可扩展性仍是需要克服的挑战。
基于NVM(非易失性存储器)的存内计算技术,如RRAM、PCM和MRAM,具有持久性和高并行计算能力,适合能效敏感的应用场景如边缘计算和物联网设备。虽然写入速度较慢和次数有限等问题仍存在,优化材料和器件、开发高效架构将是未来研究的重点。
总体而言,基于SRAM和NVM的存内计算技术正在突破传统冯·诺依曼架构的瓶颈,为高效、低功耗计算提供了新的解决方案。随着技术的不断创新和优化,这些技术在更多领域展现出广阔的应用前景。
参考文献
- 知存科技
- 中国移动研究院
- 电子与信息学报—存内计算芯片研究进展及应用
- 中科院—基于NorFlash的表积神经网络量化
- 卢北辰,杨兵.面向存算架构的神经网络数字系统设计[J/OL].微电子学与计算机:1-10
- 杨茜,王远博,王承智,等.基于MRAM的新型存内计算范式[J/OL].单片机与嵌入式系统应用,1-13
- 唐成峰,胡炜.应用于忆阻器阵列存内计算的低延时低能耗新型感知放大器[J].微电子学与计算机,2024,41(02):58-66.
- 张章,施刚,王启帆,等.基于SRAM和NVM的存内计算技术综述[J/OL].计算机研究与发展:



















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











