







简介
上一篇文章我们阐述了从范式角度解决non-iid数据的方法,本文我们将阐述一些其他方法。
FedSkip:
在FedSkip1中,中央服务器会定期地跳过联邦聚合,并直接将接收到的客户机模型分散到跨客户机中。这种通过散射操作的路由允许本地模型访问多个客户端中的数据,以获得更好的最佳追求。
跳过聚合的轮次集合定义为:
I
skip
=
{
t
∣
t
∈
R
+
&
&
1
<
t
<
T
&
&
t
m
o
d
Δ
≠
0
}
I_{\text {skip }}=\left\{t \mid t \in \mathbb{R}^{+} \& \& 1<t<T \& \& t \bmod \Delta \neq 0\right\}
Iskip ={t∣t∈R+&&1<t<T&&tmodΔ=0}
当轮次t属于这个集合时,即
t
∈
I
skip
时
t \in I_{\text {skip }} 时
t∈Iskip 时,执行“联邦跳过聚合”而不是传统的联邦平均。
Δ是一个控制跳过频率的参数。例如,如果Δ=3,那么每三轮就会跳过一次聚合。此时服务器将跳过聚合,并在下一轮中通过洗牌将这些客户端模型分散到不同的客户端。
在第t轮开始时,参与训练的第k个客户端模型将根据阶段接收不同的初始化,如以下情况所示:
w
k
t
←
{
w
0
,
t
=
0
w
^
k
t
−
1
,
t
∈
I
s
k
i
p
∑
k
=
1
K
p
k
t
w
k
t
−
1
,
otherwise
\mathbf{w}_{k}^{t} \leftarrow\left\{\begin{array}{ll} \mathbf{w}^{0}, & t=0 \\ \hat{\mathbf{w}}_{k}^{t-1}, & t \in I_{s k i p} \\ \sum_{k=1}^{K} p_{k}^{t} \mathbf{w}_{k}^{t-1}, & \text { otherwise } \end{array}\right.
wkt←⎩
⎨
⎧w0,w^kt−1,∑k=1Kpktwkt−1,t=0t∈Iskip otherwise
其中,
w
^
k
t
−
1
.
\hat{w}_{k}^{t-1} .
w^kt−1.是
{
w
^
1
t
−
1
,
w
^
2
t
−
1
,
…
,
w
^
K
t
−
1
}
(
{
w
1
t
−
1
,
w
2
t
−
1
,
…
,
w
K
t
−
1
}
.
\left\{ \hat{w}_{1}^{t-1}, \hat{w}_{2}^{t-1}, \ldots, \hat{w}_{K}^{t-1} \right\}(\left\{ w_{1}^{t-1}, w_{2}^{t-1}, \ldots, w_{K}^{t-1} \right\} .
{w^1t−1,w^2t−1,…,w^Kt−1}({w1t−1,w2t−1,…,wKt−1}.的洗牌)中的第k个模型,
p
k
t
p_{k}^{t}
pkt 是第k个局部模型在联邦跳过聚合的一个周期内累积使用相对于所有局部模型累积使用样本数量的样本数比例,公式如下:
p
k
t
=
∑
n
=
t
−
Δ
t
N
k
n
∑
k
=
1
K
∑
n
=
t
−
Δ
t
N
k
n
p_{k}^{t}=\frac{\sum_{n=t-\Delta}^{t} N_{k_{n}}}{\sum_{k=1}^{K} \sum_{n=t-\Delta}^{t} N_{k_{n}}}
pkt=∑k=1K∑n=t−ΔtNkn∑n=t−ΔtNkn
N
k
n
N_{k_n}
Nkn 是第n轮中第k个模型的样本数量。
FedSkip使局部模型能够访问多个客户端的数据进行训练,从而在异构环境中改善局部模型的最优解。此外,周期性地跳过聚合和洗牌局部模型的操作并不破坏隐私,因为它发生在服务器中,每个本地客户端都不知道其本地模型来自何处,以及它是平均模型还是跳过的模型。
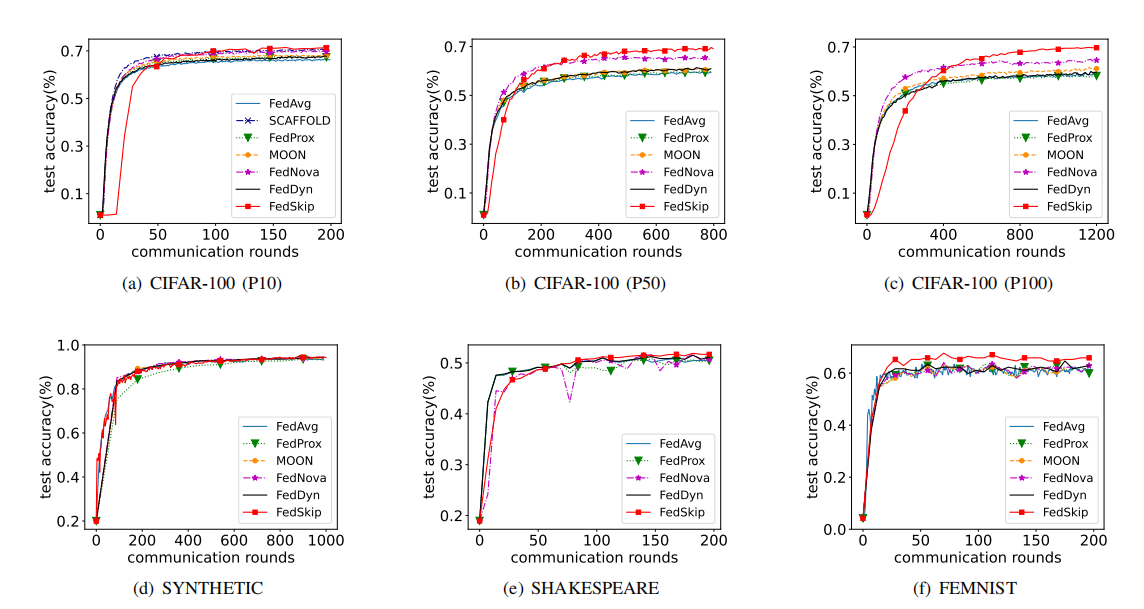
Fedskip的收敛速度较慢,早期轮次训练效果差,需要更多通信轮次(communication rounds),但其收敛后在多个数据集上展现了更优的精度(无论在IID还是non-IID场景下)。
Virtual Homogeneity Learning
VHL2,这篇论文在所有客户端之间共享一个独立于私有数据集的虚拟同构数据集,为每个客户端矫正私有数据的异构性。算法流程如下:

VHL的具体方法为:
- 创建虚拟数据集:VHL的第一步是创建一个与自然数据集独立并可分离的虚拟数据集。这使用未训练的style-GAN生成噪声,并可以使用其他方法来完成。
- 训练本地模型:接下来,使用虚拟数据集训练本地模型,并使用特定的本地目标函数进行优化。
- 对FedAvg的修改:VHL与传统的FedAvg有所不同。首先,服务器需要将虚拟数据集发送给所有选定的客户端。然后,客户端使用自然的和虚拟数据来优化其本地模型。
- 兼容其他联邦学习算法:VHL可以与其他联邦学习算法(如FedProx)相结合。
文章的核心问题是如何构建这个虚拟数据集。引入来自不同分布的大量虚拟数据将导致训练分布不同于测试分布,泛化性能较差。在论文中使用了域适应的方式。在这里,作者提到了一种策略,即通过找到一个特征提取器来最小化源分布和目标分布之间的分布差异,使得源域和目标域在学习的特征空间中有相似的分布。对于协变量偏移,会最小化边缘分布的差异;对于条件偏移,会基于标签进行条件化分布的差异;而对于数据集偏移,会处理联合分布的差异。在本文中,作者将虚拟分布视为源域,将自然分布视为目标域。这可能意味着作者试图通过使虚拟分布(源域)与自然分布(目标域)更为相似,以改进他们的模型或算法的表现。
作者使用未预训练的StyleGAN-v2生成虚拟数据集的方法。具体来说,服务器使用StyleGAN根据来自不同高斯分布的不同的潜在样式和噪声生成图片。
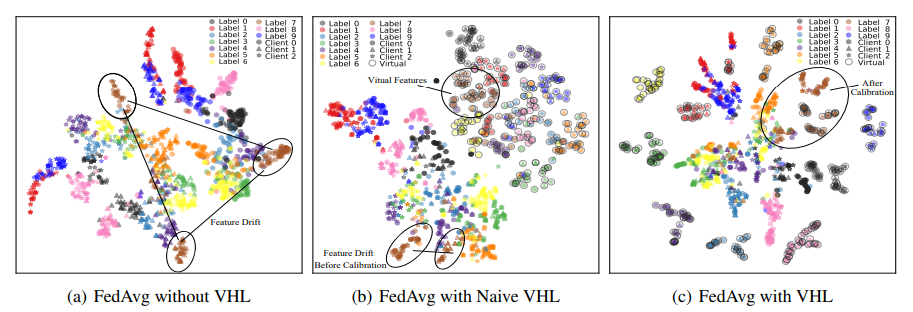
实验中如上图图使用FedAvg训练的3个不同客户端模型上的数据特征的t-SNE可视化。不同的颜色代表不同的数据类别,不同的形状代表不同的客户端,虚线圆圈表示虚拟数据。Naive VHL意味着使用私有自然数据和共享虚拟数据进行训练,而不进行特征校准。实验表明了同一类的共享噪声数据在客户端之间具有相似的特征分布。
论文实验结果是VHL比Fedavg、FedProx、SCAFFOLD等取得更好效果,不展开了。
Fan Z, Wang Y, Yao J, et al. Fedskip: Combatting statistical heterogeneity with federated skip aggregation[C]//2022 IEEE International Conference on Data Mining (ICDM). IEEE, 2022: 131-140. ↩︎
Tang Z, Zhang Y, Shi S, et al. Virtual homogeneity learning: Defending against data heterogeneity in federated learning[C]//International Conference on Machine Learning. PMLR, 2022: 21111-21132.]: ↩︎

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









