






当你需要使用和学习tokenizer时,首先你需要关注:huggingface.
所以这个教程只是一个简易版本,仅供参考。
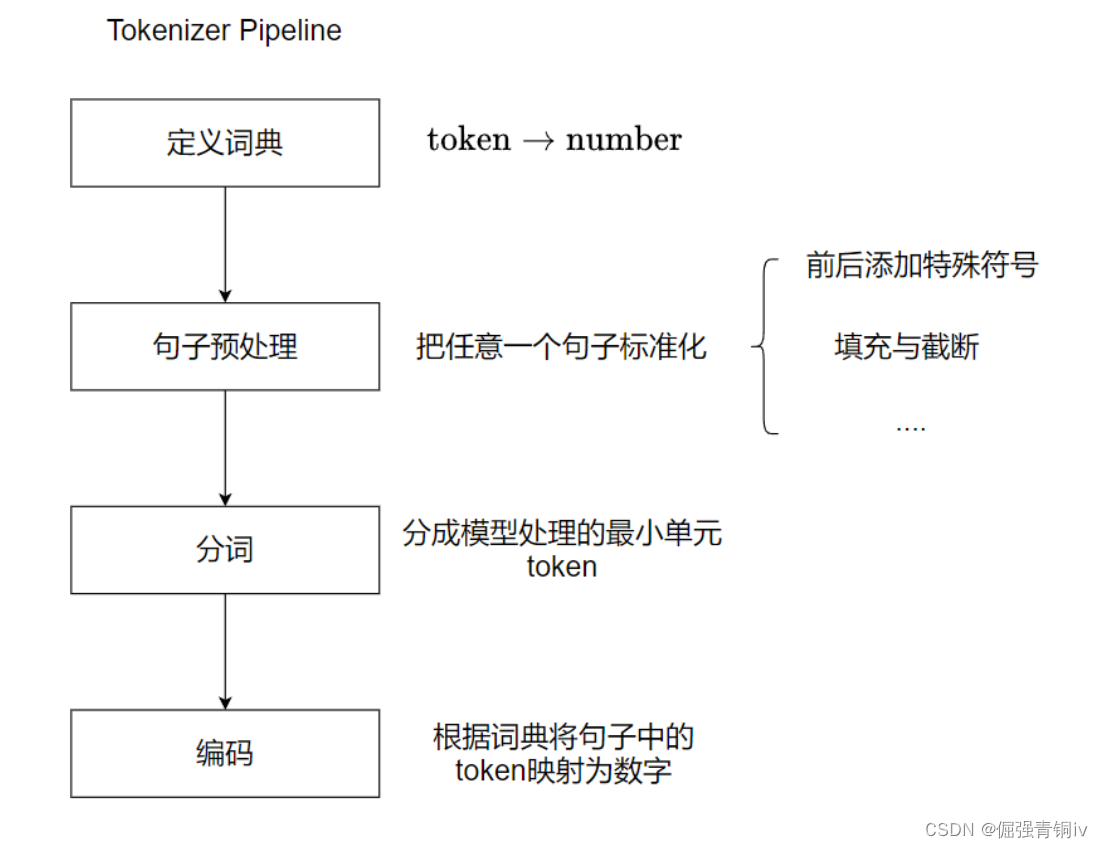
所有tokenizer的目标都是为了将语料进行分词处理,然后再输入给语言模型处理。
那么他们的输入和输出是什么就显得尤为重要,对于一个并非长期专注NLP领域的人而言,当需要用到Tokenizer时,只需要理解Tokenizer的输入和输出即可。
Tokenizer的输入
Tokenizer的输入通常是原始文本数据。这些文本数据可以是句子、段落或者整个文档。输入文本的形式取决于特定的任务需求和数据集的结构。原始文本数据在经过Tokenizer处理之前,通常不需要进行复杂的预处理,比如去除标点符号或数字,因为现代的Tokenizer设计得足够灵活,能够处理各种文本数据。
Tokenizer的输出
Tokenizer的输出是一系列的标记(tokens),这些标记可以是单词、子词(subwords)、字母或其他任何有意义的文本单位。输出的具体形式取决于Tokenizer的类型和设计。例如,有的Tokenizer可能会将“不可能”这样的词分割为“不”和“可能”两个子词;而有的则可能将其保留为一个整体。输出的标记接下来会被转换为模型能够理解的数值形式(如:索引ID),这样就可以输入到语言模型中进行进一步的处理。
重要性
理解Tokenizer的输入和输出对于使用NLP模型来说极其重要。这有助于用户选择合适的Tokenizer,确保输入的文本能够被正确地转换为模型能够处理的格式,从而获得有效的输出。了解这些基本概念,即使不深入研究NLP领域的内部机制,也能够有效地使用Tokenizer和语言模型来处理文本数据,实现如文本分类、情感分析、机器翻译等多种应用。
tokenizer的工作流程:
中英文各来一个例子
中文bert分词
简单的编码函数
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='./pretrained_bert_models/bert-base-chinese/',
cache_dir=None,
force_download=False,
)
# data
sents = [
'我爱中南大学',
'你爱自动化学院',
'他爱智能科学与技术',
]
# 基本的编码函数
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时截断
truncation=True,
#一律补PAD,直到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=25,
return_tensors=None,
)
print(out)
print(tokenizer.decode(out))
输出:
[101, 2769, 4263, 704, 1298, 1920, 2110, 102, 872, 4263, 5632, 1220, 1265, 2110, 7368, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[CLS] 我 爱 中 南 大 学 [SEP] 你 爱 自 动 化 学 院 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
这里调用了编码工具的encode()函数,这是最基本的编码函数,一次编码一个或者一对句子,在这个例子中,编码了一对句子。不是每个编码工具都有编码一对句子的功能,具体取决于不同模型的实现。在BERT中一般会编码一对句子,这和BERT的训练方式有关系,具体可参见之前写的文章。
- (1)参数text和text_pair分别为两个句子,如果只想编码一个句子,则可让text_pair传None。
- (2)参数truncation=True表明当句子长度大于max_length时,截断句子。
- (3)参 数 padding= ‘max_length’ 表 明 当 句 子 长 度 不 足
max_length时,在句子的后面补充PAD,直到max_length长度。 - (4)参数add_special_tokens=True表明需要在句子中添加特殊符号。
- (5)参数max_length=25定义了max_length的长度。
- (6)参数return_tensors=None表明返回的数据类型为list格式,也 可 以 赋 值 为 tf 、 pt 、 np , 分 别 表 示 TensorFlow 、 PyTorch 、NumPy数据格式。
进阶的编码函数
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时截断
truncation=True,
#一律补零,直到max_length长度
padding='max_length',
max_length=25,
add_special_tokens=True,
#可取值tf、pt、np,默认为返回list
return_tensors=None,
#返回token_type_ids
return_token_type_ids=True,
#返回attention_mask
return_attention_mask=True,
#返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
#返回length 标识长度
return_length=True,
)
#input_ids 编码后的词
#token_type_ids 第1个句子和特殊符号的位置是0,第2个句子的位置是1
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#attention_mask PAD的位置是0,其他位置是1
#length 返回句子长度
for k, v in out.items():
print(k, ':', v)
tokenizer.decode(out['input_ids'])
输出:
input_ids : [101, 2769, 4263, 704, 1298, 1920, 2110, 102, 872, 4263, 5632, 1220, 1265, 2110, 7368, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0]
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
length : 25
'[CLS] 我 爱 中 南 大 学 [SEP] 你 爱 自 动 化 学 院 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]'
和之前不同,这里调用了encode_plus()函数,这是一个进阶版的编码函数,它会返回更加复杂的编码结果。和encode()函数一样,encode_plus()函数也可以编码一个句子或者一对句子,在这个例子中,编码了一对句子。
参数return_token_type_ids 、return_attention_mask 、return_special_tokens_mask、return_length表明需要返回相应的编码结果,如果指定为False,则不会返回对应的内容。
接下来对编码的结果分别进行说明。
- (1)输出input_ids:编码后的词,也就是encode()函数的输出。
- (2)输出token_type_ids:因为编码的是两个句子,这个list用于表明编码结果中哪些位置是第1个句子,哪些位置是第2个句子。具体表现为,第2个句子的位置是1,其他位置是0。
- (3)输出special_tokens_mask:用于表明编码结果中哪些位置是特殊符号,具体表现为,特殊符号的位置是1,其他位置是0。
- (4) 输 出 attention_mask : 用 于 表 明 编 码 结 果 中 哪 些 位 置 是PAD。具体表现为,PAD的位置是0,其他位置是1。
- (5)输出length:表明编码后句子的长度。
批量编码函数
以上介绍的函数,都是一次编码一对或者一个句子,在实际工程中需要处理的数据往往是成千上万的,为了提高效率,可以使用batch_encode_plus ()函数批量地进行数据处理,代码如下:
#批量编码成对的句子
out = tokenizer.batch_encode_plus(
#编码成对的句子
batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2])],
add_special_tokens=True,
#当句子长度大于max_length时截断
truncation=True,
#一律补零,直到max_length长度
padding='max_length',
max_length=25,
#可取值tf、pt、np,默认为返回list
return_tensors=None,
#返回token_type_ids
return_token_type_ids=True,
#返回attention_mask
return_attention_mask=True,
#返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
#返回offsets_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用
#return_offsets_mapping=True,
#返回length 标识长度
return_length=True,
)
#input_ids 编码后的词
#token_type_ids 第1个句子和特殊符号的位置是0,第2个句子的位置是1
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#attention_mask PAD的位置是0,其他位置是1
#length 返回句子长度
for k, v in out.items():
print(k, ':', v)
print(tokenizer.decode(out['input_ids'][0]))
print(tokenizer.decode(out['input_ids'][1]))
参数batch_text_or_text_pairs用于编码一批句子,示例中为成对的句子,如果需要编码的是一个一个的句子,则修改为如下的形式即可
batch_text_or_text_pairs=[sents[0], sents[1]]
input_ids : [[101, 2769, 4263, 704, 1298, 1920, 2110, 102, 872, 4263, 5632, 1220, 1265, 2110, 7368, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 800, 4263, 3255, 5543, 4906, 2110, 680, 2825, 3318, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
length : [16, 11]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
[CLS] 我 爱 中 南 大 学 [SEP] 你 爱 自 动 化 学 院 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[CLS] 他 爱 智 能 科 学 与 技 术 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
可以看到,这里的输出都是二维的list了,表明这是一个批量的编码。这个函数会多次用到。
对字典的操作
#获取字典
vocab = tokenizer.get_vocab()
type(vocab), len(vocab), '智能' in vocab
(dict, 21128, False)
可以看到,字典本身是个dict类型的数据。在BERT的字典中,共有21128个词,并且“智能”这个词并不存在于字典中。既然“智能”并不存在于字典中,可以把这个新词添加到字典中,代码如下:
#第2章/添加新词
tokenizer.add_tokens(new_tokens=['智能', '自动化', '中南大学'])
这里添加了3个新词,分别为’智能’, ‘自动化’, ‘中南大学’。也可以添加新的符号,代码如下:
#添加新符号
tokenizer.add_special_tokens({'eos_token': '[EOS]'})
接下来试试用添加了新词的字典编码句子,代码如下:
#编码新添加的词
out=tokenizer.encode(
text='我爱中南大学自动化学院智能科学与技术系[EOS]',
text_pair=None,
#当句子长度大于max_length时截断
truncation=True,
#一律补PAD,直到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=20,
return_tensors=None,
)
print(out)
tokenizer.decode(out)
[101, 2769, 4263, 21130, 21129, 2110, 7368, 21128, 4906, 2110, 680, 2825, 3318, 5143, 21131, 102, 0, 0, 0, 0]
'[CLS] 我 爱 中南大学 自动化 学 院 智能 科 学 与 技 术 系 [EOS] [SEP] [PAD] [PAD] [PAD] [PAD]'
可以看到,“智能”,“中南大学”,"自动化"已经被识别为一个词,而不是多个词,新的特殊符号[EOS]也被正确识别。
英文bert分词
跟上面中文分词的原理差不多,只不过英文分词更加容易理解和处理。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='../../pretrained_models/pretrained_bert_models/bert_base_uncased/',
cache_dir=None,
force_download=False,
)
sents = [
'I love CSU',
'you love shcool of automation',
'he loves Artificial Intelligence',
]
# 基本的编码函数
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时截断
truncation=True,
#一律补PAD,直到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=20,
return_tensors=None,
)
print(out)
print(tokenizer.decode(out))
# 进阶编码
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时截断
truncation=True,
#一律补零,直到max_length长度
padding='max_length',
max_length=25,
add_special_tokens=True,
#可取值tf、pt、np,默认为返回list
return_tensors=None,
#返回token_type_ids
return_token_type_ids=True,
#返回attention_mask
return_attention_mask=True,
#返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
#返回length 标识长度
return_length=True,
)
#input_ids 编码后的词
#token_type_ids 第1个句子和特殊符号的位置是0,第2个句子的位置是1
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#attention_mask PAD的位置是0,其他位置是1
#length 返回句子长度
for k, v in out.items():
print(k, ':', v)
print(tokenizer.decode(out['input_ids']))
#批量编码成对的句子
out = tokenizer.batch_encode_plus(
#编码成对的句子
batch_text_or_text_pairs=[(sents[0], sents[1]), (sents[2])],
add_special_tokens=True,
#当句子长度大于max_length时截断
truncation=True,
#一律补零,直到max_length长度
padding='max_length',
max_length=25,
#可取值tf、pt、np,默认为返回list
return_tensors=None,
#返回token_type_ids
return_token_type_ids=True,
#返回attention_mask
return_attention_mask=True,
#返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
#返回offsets_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用
#return_offsets_mapping=True,
#返回length 标识长度
return_length=True,
)
#input_ids 编码后的词
#token_type_ids 第1个句子和特殊符号的位置是0,第2个句子的位置是1
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#attention_mask PAD的位置是0,其他位置是1
#length 返回句子长度
for k, v in out.items():
print(k, ':', v)
print(tokenizer.decode(out['input_ids'][0]))
print(tokenizer.decode(out['input_ids'][1]))
#获取字典
vocab = tokenizer.get_vocab()
type(vocab), len(vocab), '[EOS]' in vocab
#添加CSU
tokenizer.add_tokens(new_tokens=['CSU'])
tokenizer.add_special_tokens({'eos_token': '[EOS]'})
#编码新添加的词
out=tokenizer.encode(
text='I love CSU[EOS]',
text_pair=None,
#当句子长度大于max_length时截断
truncation=True,
#一律补PAD,直到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=10,
return_tensors=None,
)
print(out)
print(tokenizer.decode(out))
输出:
[101, 1045, 2293, 20116, 2226, 102, 2017, 2293, 14021, 3597, 4747, 1997, 19309, 102, 0, 0, 0, 0, 0, 0]
[CLS] i love csu [SEP] you love shcool of automation [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
input_ids : [101, 1045, 2293, 20116, 2226, 102, 2017, 2293, 14021, 3597, 4747, 1997, 19309, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
token_type_ids : [0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
special_tokens_mask : [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
length : 25
[CLS] i love csu [SEP] you love shcool of automation [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
input_ids : [[101, 1045, 2293, 20116, 2226, 102, 2017, 2293, 14021, 3597, 4747, 1997, 19309, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 2002, 7459, 7976, 4454, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
length : [14, 6]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
[CLS] i love csu [SEP] you love shcool of automation [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[CLS] he loves artificial intelligence [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
[101, 1045, 2293, 30522, 30523, 102, 0, 0, 0, 0]
[CLS] i love csu [EOS] [SEP] [PAD] [PAD] [PAD] [PAD]















 3245
3245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









