






作者:邵可佳( 墨迹天气 算法专家 )
大家好,上次我们探索了一下和决策树模型相关的话题,但都没有深入展开去讲
今天闲来无事,和大家再聊聊决策树模型,这次谈论的话题稍微复杂一点
不要说什么决策树out之类的话,我可是不赞同的哦
也同时给大家分享几点工作中的心得,希望对大家研究算法带来新的启发和思路。
01 决策树的目标函数
通常我们在设定机器学习任务的时候,只需要使用已知的几种决策树框架,使用系统自带的目标函数即可,例如xgboost回归任务时就可以选用reg:squarederror
但有时候我们会面临一些较复杂的任务,目标函数也会变得很复杂(例如不是线性变化的loss),这时候就可以通过自定义目标函数的方式实现
相信XGBoost自定义目标函数就难倒了一批人:
一是大家很少会用到自定义目标函数的场景
二是xgboost自定义目标函数的门槛要高
神经网络自定义lossXGBoost的官方文档说明,目标函数中必须提供两个输出:grad 和 hess
https://xgboost.readthedocs.io/en/stable/tutorials/custom_metric_obj.html
grad代表梯度,hess代表grad的偏导数
注意:这里国内大部分文章将偏导和偏导数混淆不清,很容易误导人,一字之差含义却大不相同
我们一定要注意区分导数和导函数,有的文章甚至堂而皇之说导函数简称导数,简直给本已非常模糊的概念变得更加难懂,真是一场英文知识到中文知识翻译的重大车祸现场
这里明确下:
导数英文 Derivative
导函数英文 Derivative function (function一字之差,万万不能少)
偏导默认是偏导函数,求出来的结果是一个表达式,而偏导数是一个数值,所以求偏导数的方式也是不同的:
scipy.misc.derivative 用于求解导函数值 (简称导数)
sympy.diff 用于取得代数形式的导函数
好了,搞清楚了上面的点以后,还需要注意的是,不是所有的loss function都能求出正确的偏导数的,这里又是一个容易混淆的知识点,所有中文资料里都会提到,一定要先证明loss function可微,这就导致本就困难重重的目标函数设计更加雪上加霜
如何证明损失函数可微呢?其实换个说法,你就能立马明白,也无需严格证明:

设计者只需要关注一点:损失函数必须在取值范围内是连续光滑的(想象一下丝滑的曲线或曲面即可)
心得:设计好决策树模型的损失函数基本上就成功了一半,不要设置一些冷门复杂的分段的损失函数,因为你很难想象出它在解空间中表现的样子
02 决策树中的不平衡学习
现实世界中,数据平衡的样本是理想状态,而不平衡的样本是常态,如何使用不平衡的样本训练模型从而达到预期的模型效果,是算法工程师经常面对的问题
什么是不平衡学习问题:就是正负样本之间的比例不等于1:1,其中一类样本要远大于另一类样本
下图就是一个典型的不平衡样本数据的分布:

所以,所谓不平衡学习,实际是指使用不平衡的训练样本进行机器学习
那么,不平衡的样本会给机器学习带来什么样的问题?
- 非常直观的,模型采取偷懒的策略,只要始终押注在数量多的那一类,准确率就会一直很高;
- 模型根本学习不到数量少的那一类数据的分布规律
面对不平衡的样本,从直观上想想又会有哪些手段?
我们自然想到的,有以下几种策略:
- 配平样本
- 配平学习目标
- 调整损失函数
下面分别说明下:
1.配平样本
参考:https://imbalanced-learn.org/stable/references/index.html#api
- 删除较多类的样本
行话就是 undersampling 降采样
- 随机降采样(RandomUnderSampler):顾名思义,就是随机删除一定量的样本
- 质心降采样(ClusterCentroids):采取KMeans聚类的方法,生成聚类样本的质心
- 浓缩近邻降采样(CondensedNearestNeighbour):
- 编辑近邻降采样(EditedNearestNeighbours):
- 重复编辑近邻(RepeatedEditedNearestNeighbours):
……
等等,这里就不罗列了,在不同的问题选用对应的方法即可
- 增加较少类的样本
其实严格意义上来说,增加少类的样本也是建立在某种分布的假设基础上的,所以我认为除非样本实在太少,否则还是慎用
过采样 oversamping
- 随机过采样(RandomOverSamper):意思类似
- 合成少数群体过采样系列(SMOTE系列):通过最近邻的同类样本插值得到新样本
SMOTE是一个系列,可以采取各种不同的插值策略得到假想中的结果
- 降采样和过采样综合使用
按照一定的比率或规则采取大样本的降采样和小样本的过采样
2.配平学习目标
以上配平样本的技术说了这么多,视乎和决策树没啥关系,下面就聊聊和决策树相关的:
我们知道,在集成学习树中有两种重要的集成策略:boosting和bagging,所以与之对应的,就会有两类不同的目标优化方式:
- 针对boosting的样本配平算法:针对决策树在boosting过程中样本的选取(目前大多是降采样);
- 针对bagging的样本配平算法:针对决策树在bagging过程中样本的选取;
不过,除了集成学习策略,XGBoost也自带一些优化参数,可以让我们更方便的训练模型:
xgboost.DMatrix.weight: 可设置训练集每行数据的权重
xgboost.DMatrix.feature_weights: 可设置训练集每列数据的权重
通过权重的设置,可以变相的加强对小样本的学习
当然,除了可以预先设定参数,也可以通过设计自定义目标函数实现
心得:数据是模型的根本,在数据上做文章实际上是用人类的先验知识指导模型学习
03 决策树的超参数搜索
决策树模型之所以无法快速应用还有一个比较难搞的部分就是超参数搜索,不过目前已经有很多框架使得超参数的搜索越来越简单智能,从最初的gridsearch到目前的optuna到autoxgb,超参数搜索的计算成本在逐渐降低,而超参数搜索的成功率也在不断提高
1.optuna:
我们重点关注下optuna(autoxgb也是基于optuna的),看看超参数搜索到底有何神秘之处:

optuna支持多种超参数搜索策略,如上图所示,CMA-ES就是optuna支持的一种超参数搜索策略
参考:https://optuna.readthedocs.io/zh_CN/latest/tutorial/10_key_features/003_efficient_optimization_algorithms.html
optuna的采样算法:
- optuna.samplers.TPESampler 实现的 Tree-structured Parzen Estimator 算法
- optuna.samplers.CmaEsSampler 实现的 CMA-ES 算法
- optuna.samplers.GridSampler 实现的网格搜索
- optuna.samplers.RandomSampler 实现的随机搜索
其他两种倒是比较好理解,那么什么是TPE和CMA-ES呢?
TPE:树结构帕森估计,简单表述就是:假设超参数的解空间存在某种分布,不断使用两组高斯混合模型对比结果去逼近最优解;(注意:假设的前提是超参数的解空间分布是连续的)
https://zhuanlan.zhihu.com/p/55606172
CMA-ES:关于协方差自适应进化策略,这篇文章讲得很详细了,就不再多说:
https://blog.csdn.net/weixin_39478524/article/details/109368216
2.HyperGBM:
https://github.com/DataCanvasIO/HyperGBM
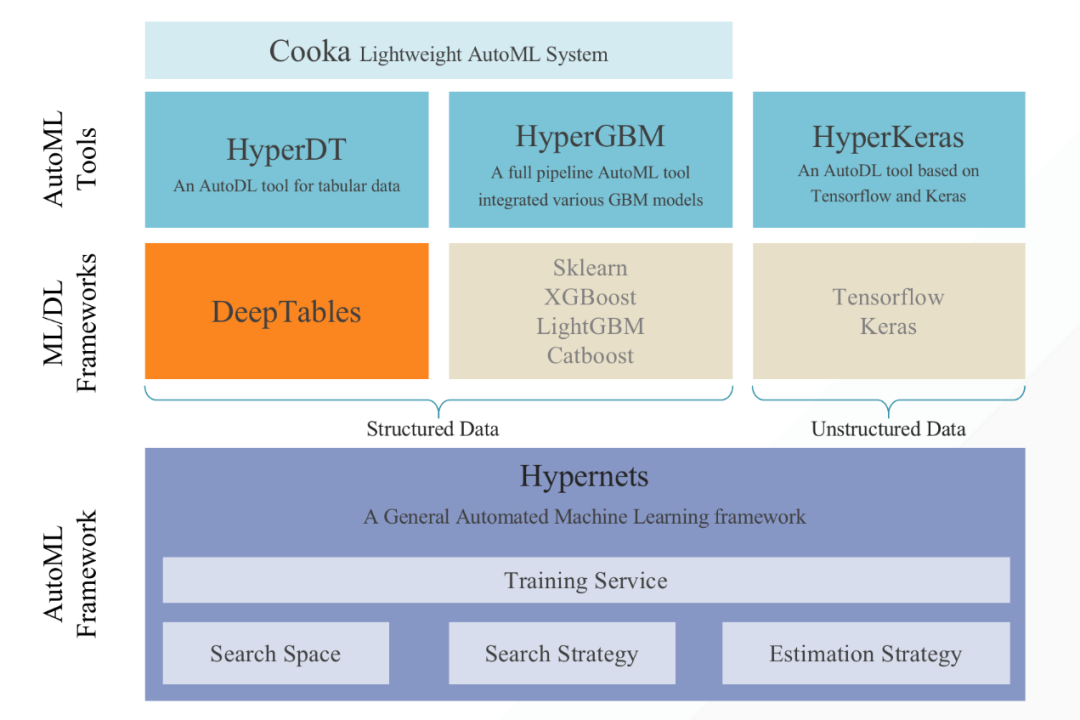
与其说HyperGBM是一款超参数搜索框架,不如将它看做是一款自动化机器学习框架更恰当,它不仅包含了决策树的部分,且包含了神经网络的部分,在算法上倒是没有发现创新点,所以更多的是当做一款工程化工具推荐给大家
心得:超参数一定程度上也反应了设计者对问题的理解,所有超参数搜索技术都是贯彻或加强这种理解,只有建立在对问题抽象的理解基础上,才有可能搜索出有效的超参数。
04 决策树与神经网络
上次给大家介绍了tabnet等结合决策树思想与神经网络思想的框架,这次再给大家介绍几款很有潜力的框架:
1.XBNet:https://github.com/tusharsarkar3/XBNet

决策树可以通过boosting的策略来提升算法精度,那么是否也可以通过使用神经网络模拟boosting策略实现成功呢?XBNet就是这样一款框架,通过神经网络将决策树连接起来,进而实现boosting和bagging的自动化,是不是看起来很有趣?不过这款框架还未实现基于GPU的计算,并且神经网络的设计还需要用户指定(未来如果能结合AutoPytorch则更好),大家有兴趣可以尝试下
2.PyTorch Tabular:https://github.com/manujosephv/pytorch_tabular
这是一款集成框架,集成了常见的几种结合神经网络的table data算法,包括之前给大家介绍的tabnet
3. Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data

基本原理与XBNet类似,只不过输出部分的结构与boosting和bagging的思想更相似,如上图所示
4.Mixture Density Networks: https://publications.aston.ac.uk/id/eprint/373/1/NCRG_94_004.pdf

将神经网络中的隐层替换成高斯混合模型,实际上可以看做是一种先验知识的叠加
剩下的就不做过多介绍了,以上各种神经网络与决策树的结合体本质上都是使用神经网络代替了部分集成学习的策略,实现自动集成学习,但从抽象的数学模型来看,没有实质性的变化。从论文给出的结果也发现,比起传统的机器学习效果的提升并不是特别显著,且存在部分结果会变差的情况。
但神经网络的引入,确实减少了集成学习超参数的设置,减小了人工设置的复杂度。
所以神经网络与决策树的结合还需要更多的探索和实践的检验。期待未来能有更多的算法出现!
心得:神经网络也不是万能的灵丹妙药,但让工具变得自动化和友好,一直是人类不断的追求,所以很多问题方法不重要,简单好用才是真的香!
总结
本文从决策树模型比较常见和热门的三个点(自定义目标函数、超参数搜索、与神经网络结合)给大家介绍了一下作者个人收集的经验和心得,希望对读者有所帮助!
好了,以上给大家有侃了一堆,大家也不要盲目相信,抱着拿来主义的态度注定还是会吃亏的,文中恐怕也有不少错漏的地方,希望大家多多批评指正!















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









