







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、前期工作
1. 设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
2. 导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data(path='mnist.npz')
3. 归一化
数据归一化作用
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度。
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
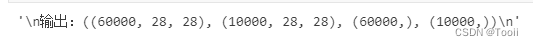
4. 可视化图片
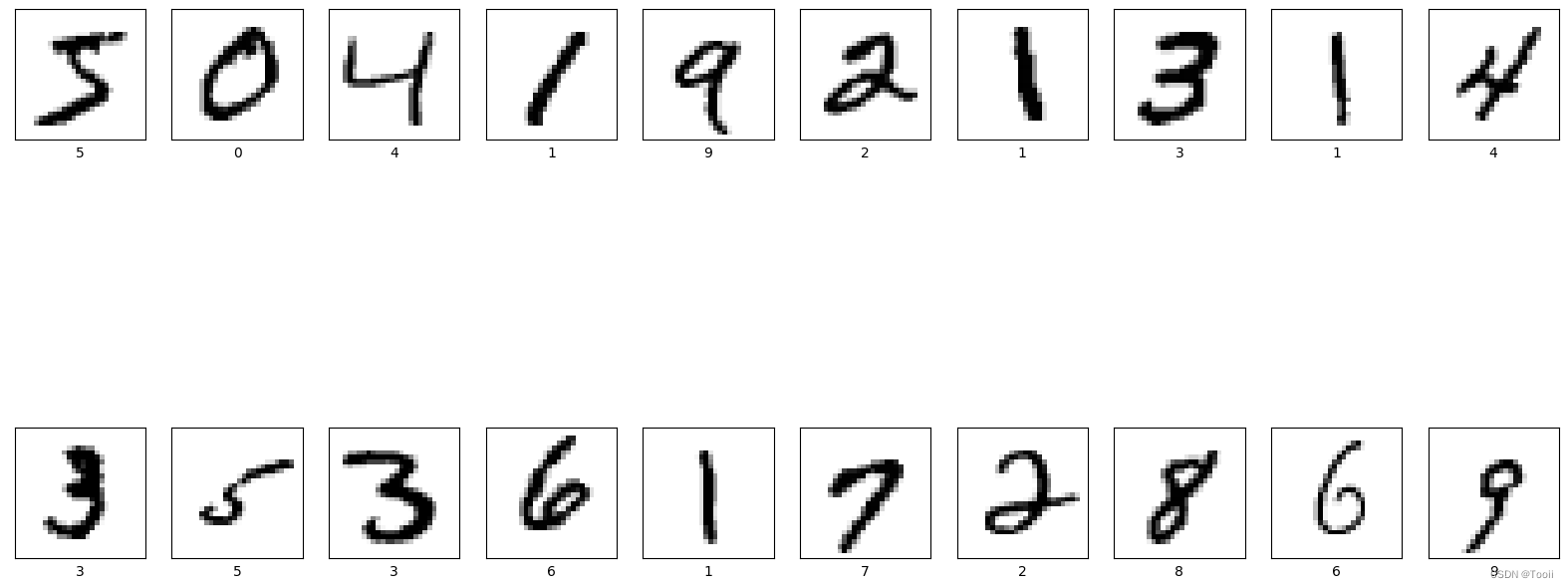
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):
# 将整个figure分成5行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()
5. 调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape

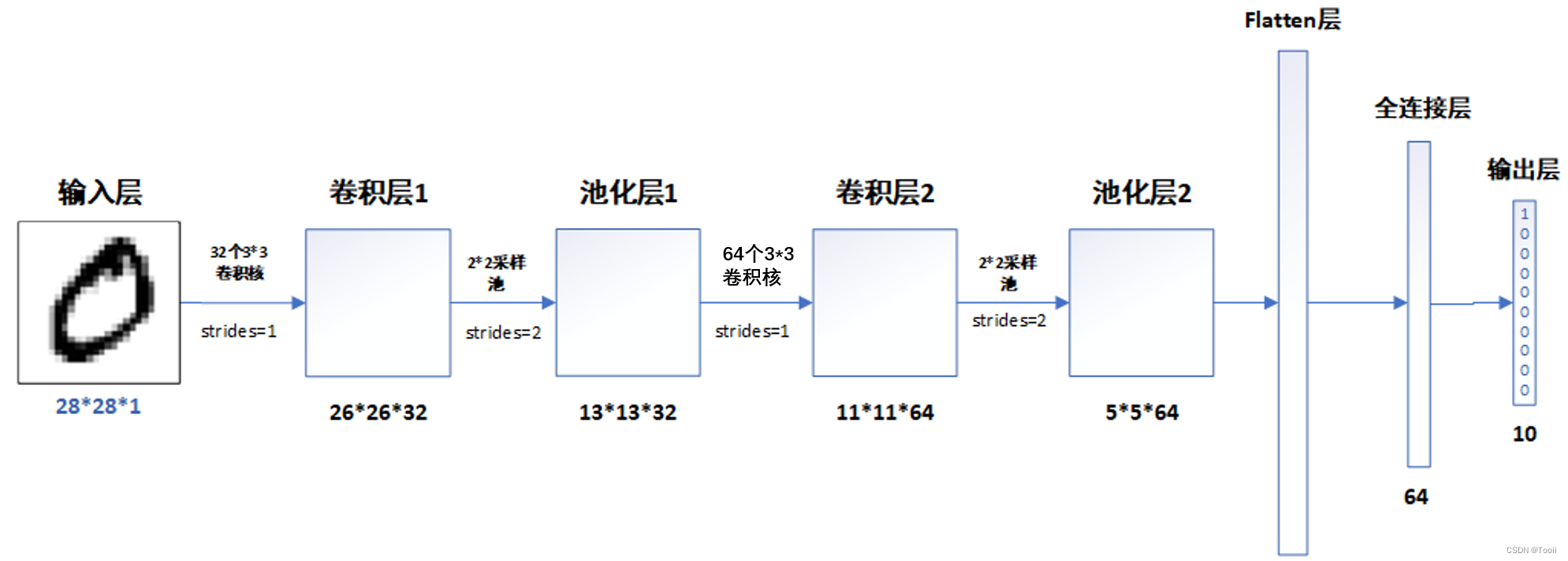
二、构建CNN网络模型
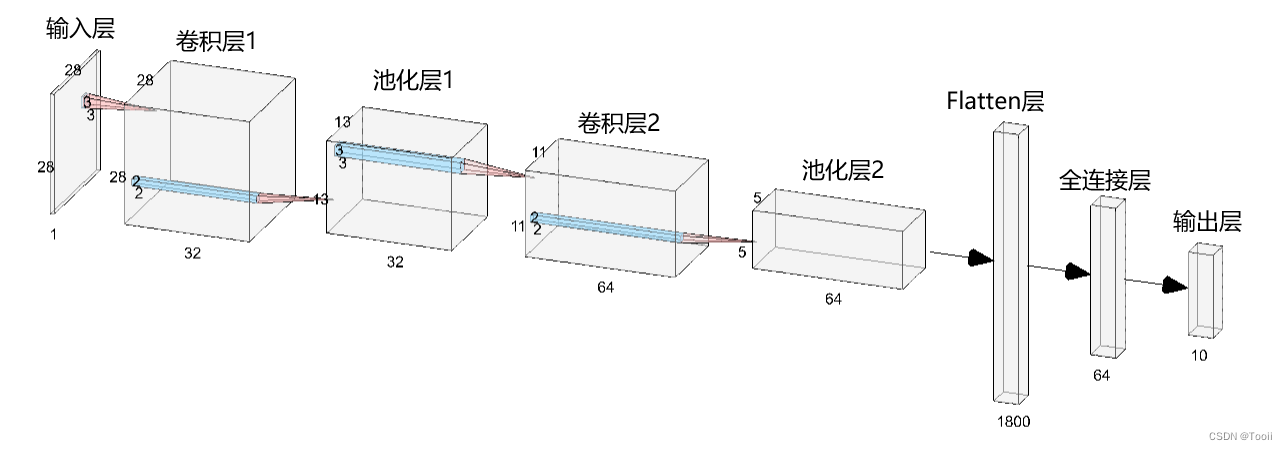
网络结构图:
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
#池化层1,2*2采样
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
#池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
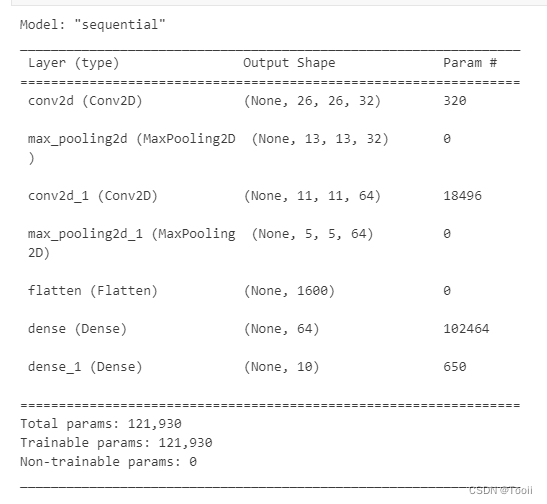
model.summary()
三、编译模型
"""
这里设置优化器、损失函数以及metrics
这三者具体介绍可参考我的博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])
四、训练模型
"""
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
关于model.fit()函数的具体介绍可参考我的博客:
https://blog.csdn.net/qq_38251616/category_10258234.html
"""
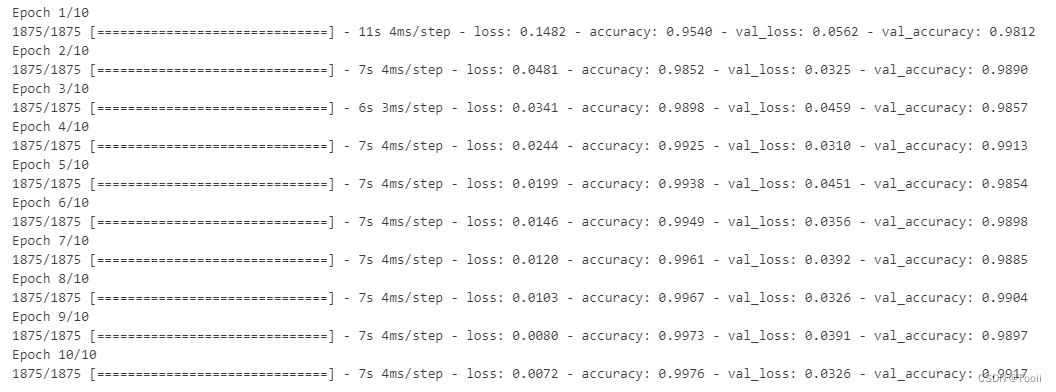
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))
五、预测
通过下面的网络结构我们可以简单理解为,输入一张图片,将会得到一组数,这组代表这张图片上的数字为0~9中每一个数字的几率(并非概率),out数字越大可能性越大,仅此而已。
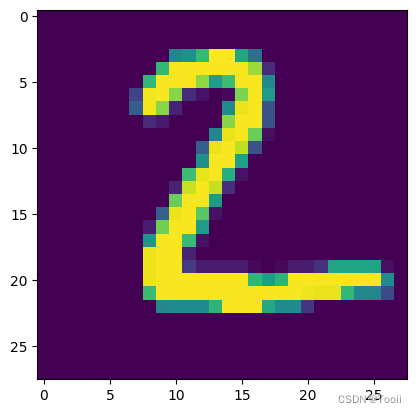
在这一步中部分同学会因为 matplotlib 版本原因报 Invalid shape (28, 28, 1) for image data 的错误提示,可以将代码改为 plt.imshow(test_images[1].reshape(28,28)) 。
plt.imshow(test_images[1])
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果

六、知识点详解
本文使用的是最简单的CNN模型- -LeNet-5,如果是第一次接触深度学习的话,可以先试着把代码跑通,然后再尝试去理解其中的代码。
1. MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/(下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单
MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是28*28,数据集样本如下:

如果我们把每一张图片中的像素转换为向量,则得到长度为28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。

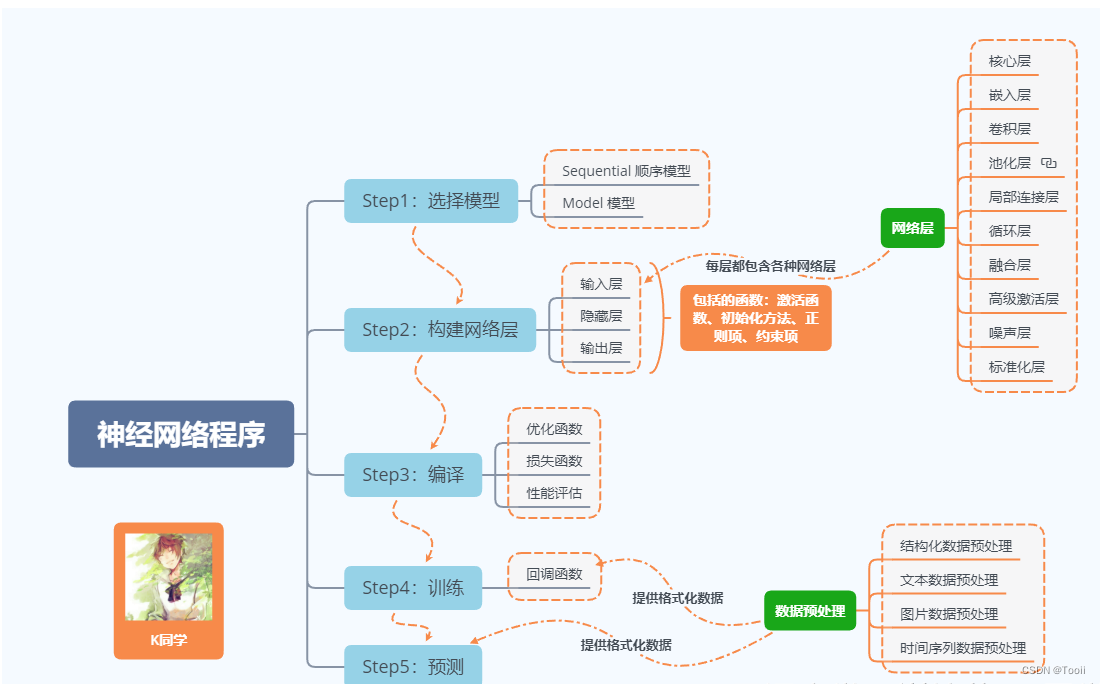
2. 神经网络程序说明
神经网络程序可以简单概括如下:
3. 网络结构说明
各层的作用
- 输入层:用于将数据输入到训练网络
- 卷积层:使用卷积核提取图片特征
- 池化层:进行下采样,用更高层的抽象表示图像特征
- Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡
- 全连接层:起到“特征提取器”的作用
- 输出层:输出结果
六、个人收获
通过学习本文,我对深度学习中的卷积神经网络(CNN)有了更深入的了解。从设置GPU开始,到导入数据、归一化、可视化图片,再到构建、编译、训练模型,全方位地了解了CNN的基本流程。特别是对于MNIST手写数字数据集的介绍和神经网络结构的说明,让我更加清晰地理解了CNN的工作原理。















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









