







关注微信公众号“时序人”获取更好的阅读体验
时间序列知识整理系列
在许多真实场景中,由于采集能力或网络传输的原因,时序数据常常会有缺失,断点的情况。很多依赖时序数据进行分析的算法基本都基于时序数据是完整的前提下;许多业务也需要数据保持完整,以进行更好的可视化与分析。如何处理这些有缺失的时间序列呢?

有关时间序列的补缺工作大体上分为:删除或填充这两类。删除所考虑的不是进行填补,而是将缺失值作为特征之一输入到时序模型,例如异常检测,行为分析等;而填充是找到时序变化的规律,将值补充进去,分为统计方式填充与机器学习填充两种方式。
本文就上面时序补缺的两大类方向整理相关工作,供大家阅读。
缺失数据删除
最直接的缺失数据处理的方式,就是直接忽略这些缺失值,简称为直接删除法,该方法常用在离散型的时间序列处理中,比如用户购物行为序列,事件序列等,这类序列数据没有固定的采集间隔,一般会把数据点之间的间隔时间作为特征进行分析。
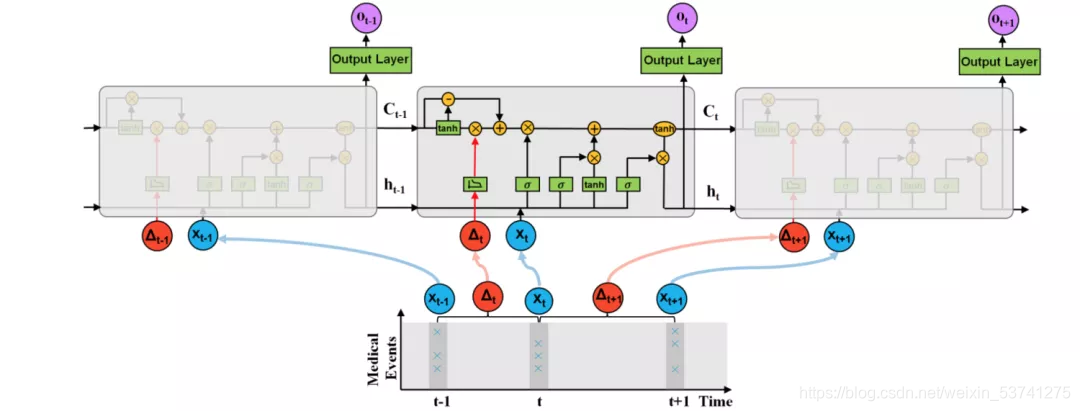
比如上图所展示了TLSTM [ 1 ] ^{[1]} [1]模型,来自KDD 2017年的工作,其将数据 X t − 1 X_{t-1} Xt−1与 X t X_t Xt之间的间隔 Δ t \Delta_t Δt作为特征进行输入。TLSTM中专门设计了一种新的门结构对这种间隔信息进行加权聚合。
当然,该类方法可能会舍弃数据中的一些重要信息,在监控/IoT/风控等这种稳定性要求高的业务中,不能适用,因为每个数据点所代表的信息都很重要。
缺失数据填补
将缺失的数据删除一般只适用于少部分对数据完整度要求不高的场景,大部分场景(例如监控、安全等)需要我们尽可能将缺失的数据填充。数据填充需要我们找到时间序列一定的变化规律,从而将值补充进去。这里与时间序列的预测有一点相似,不同的是,时间序列预测中我们看不到所要预测点后面的数据,而时序补缺中,我们可以分析缺失点前后的数据,从而更精准的对缺失数据进行填充。
数据填充基本分为统计方式填充与机器学习填充两种方式。
统计方式填充
基于统计学的填充方法是时间序列补缺中常用的方法,其计算复杂度低,易操作,在许多精度要求不高的业务场景中比较适用。
就近填充
就近填充包括:前推法LOCF,用缺失之前的最后一次观测值填补;与后推法NOCB, 使用缺失值后面的观测值进行填补。这个方法是时序当中最基本的方法。
特征值填充
特征值填充包括:均值、中值、常用值等。这类方法计算快,进行简单的统计即可实现数据的填补。其一般直接忽略数据的时序信息**,**假定时序数据里面基本没有很强趋势性。
线性插值
这个方法历史悠久。其假定时序之间变动有很强的趋势,通过拟合数据的趋势变化,进而进行填补。早期天文学缺失数据都用这个方法。
线性插补的方法包括一元线性回归,多元线性回归,岭回归等,有关方法可以参考之前的文章:《TS技术课堂 | 时间序列回归》
季节性+线性插值
经济数据或者季节波动数据,尝尝不符合简单的线性变化强假设。对这样的数据进行补缺,一般的线性插值法效果比较差。这里需要模型同时捕捉时序数据的季节性和总体趋势性,进而对数据的演变模式更好的拟合,实现缺失值数据的补充。
除了这些统计方法, 一般来说每个领域里面缺失值都肯定还要借鉴专业知识来判断。比如以国家军费缺失数据为例,如果你知道因为战乱带来的缺失。那么战时数据比和平年代数据就更合适,很简单就近填补。
机器学习方式填充
随着计算能力的大幅提升,现今许多的场景下的时间序列补缺都采用了机器学习的方式,常见的方法包括基于最近邻方法(KNN),循环神经网络(RNN),随机森林和矩阵分解的缺失值填充算法。
有监督数据填充
这类的方法的本质是以缺失点附近的数据作为特征,预测缺失点的数据,通过海量的历史数据中挖掘相似的变化模型,从而进行更精准的数据填充。包括:
- KNN:找到缺失点附近数据最相似的若干个历史数据点,对缺失值进行填补
- RNN:通过循环神经网络拟合时序数据的变化趋势,对缺失数据进行填补。这里一般多使用双向RNN
- 随机森林:这里一缺失点附近的数据作为特征,缺失数据作为要预测的值,在海量数据中训练一个高拟合随机树,对缺失点进行预测。
- 生成网络:近些年随着生成对抗网络(GAN)的兴起,许多方法开始尝试做时间序列的生成,通过生成模型捕捉时间序列的分布特征,对时序数据进行再生成,进而填补数据。
多值插补
多值插补是近些年兴起的时序数据补缺方法,其主要应用于包括时空数据在内的多维时间序列问题。其补全数据不仅只关注自身的时序演变,同时关注相邻时序,特别是有影响关系的时序指标之间的影响。例如在交通中,某一路段的交通量与其上游、下游路段的交通量直接相关。这类方法依赖于缺失数据不同属性间关系,寻找最类似样本,对于突发情况下的数据丢失,异常数据点(离群点)的补全有更好的适应性。
-
矩阵分解:不同的时间序列之间往往相互关联,通过矩阵分解等方法学习时序矩阵的整体特征,对时间特性矩阵进行低秩逼近,从而修补缺失数据。该类方法计算复杂度低 O ( n ) O(n) O(n),可以处理较大规模的数据,如NeurIPS2016的TRMF [ 2 ] ^{[2]} [2]。
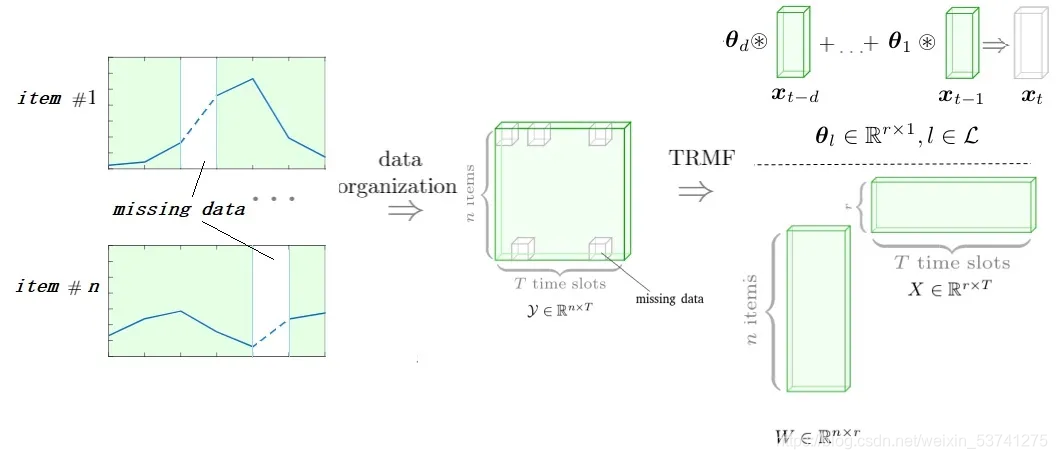
-
组合分析:对于不同学科的数据补缺可能都有默认或者建议的方法,比如社会学或者人口学对于无应答的问卷数据,就是假定用类似用户数据进行填补。很多的场景下的数据填补需要填补的数据具有合理性,填补模型可解释。面对这样的情况,我们尝尝难以理解矩阵分解类方法填补数据背后所依赖的关系。因此,近年来一些方法考虑分析多源时序数据实体之间的外在属性,构建可解释的关联关系,组合多源时序及其关系进行数据的填补。
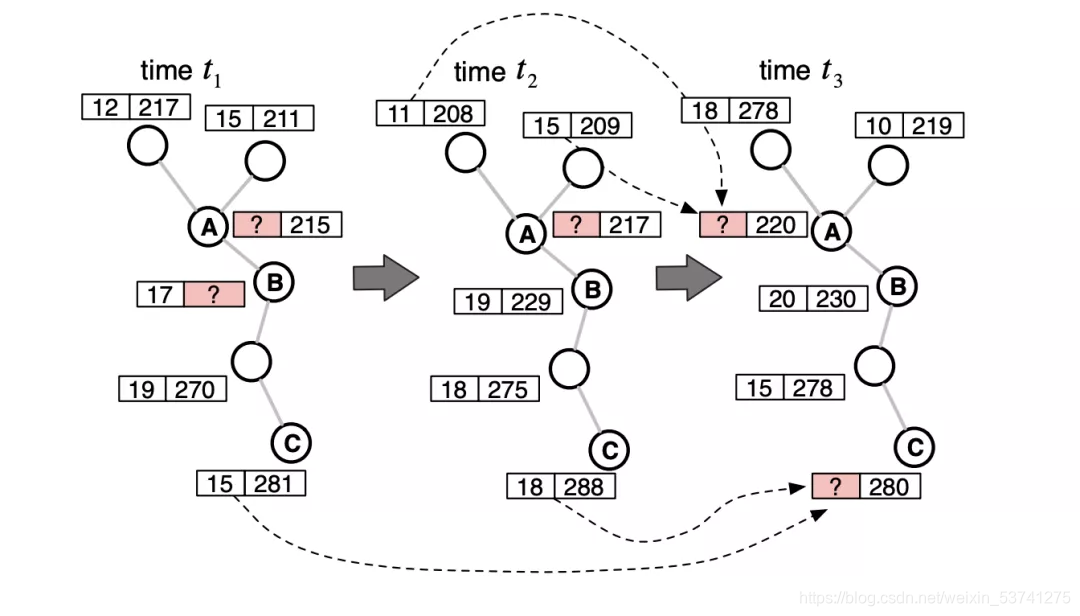
上图所示的WWW 2019 [ 3 ] ^{[3]} [3]的工作,其基于用户的邻里关系,关联不同用户的用电数据,对缺失的数据进行填补。
开源工具
Sklearn实现了多种基于统计方法的缺失数据补全算法
该仓库实现了基于链式方程法的多维时序补缺算法
该仓库实现了基于随机森林的一种非参数混合类型补缺算法
该仓库实现了通过迭代软阈值SVD的完成矩阵进行补缺的算法
该仓库实现了基于社群关系进行多源时间序列补缺的算法
该仓库实现了当前主流的基于矩阵分解的时间序列缺失值填充算法和预测算法
- …
总结
时间序列数据的补缺, 有很多不同的方法。在进行补缺之前,第一步需要我们对缺失的性质做出判断:如果是Missing at Random还是Missing Not at Random,一般前者删除,后者填充。但是填充不一定能带来更好结果,要先自己根据缺失比例和原因进行判断。
最后,如果你对数据生成机制很熟悉的情况下,可能一些简单方法就可以实现很好的数据补缺。对于本身纯粹依赖算法,不能给出解释机制的时间序列补缺是不能完全信服的,因为缺失本身表明这些样本信息不足。这里尝尝需要增加专业知识的判断,因为专业知识判断就相当于额外增补信息。
参考
[1] Inci M. Baytas, Cao Xiao, Xi Zhang, Fei Wang, Anil K. Jain, and Jiayu Zhou. Patient Subtyping via Time-Aware LSTM Networks. KDD 2017.
[2] Yu, H. F., Rao, N., & Dhillon, I. S.Temporal regularized matrix factorization for high-dimensional time series prediction. NeurIPS 2016.
[3] Zongtao, L; Yang, Y; Wei, H; Zhongyi, T; Ning, L and Fei, W. How Do Your Neighbors Disclose Your Information: Social-Aware Time Series Imputation. WWW 2019
更多原创内容与系列分享,欢迎关注微信公众号“时序人”获取。


















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









