







Abstract
This week I explored multiclass classification model, focusing on activation functions like ReLU for neural networks. I discussed the softmax function for multiclass predictions and compared it with binary classification methods. Additionally, I covered image processing with PyTorch’s transforms, including normalization and resizing. I also explained how to use the CIFAR-10 dataset with DataLoader and highlighted the importance of GPU acceleration and PyTorch’s Autograd for model training efficiency.
多分类(multiclass)
更多的激活函数
前面我们一直在使用sigmoid函数作为激活函数,sigmoid函数是一个自然的选择,因为它是一个平滑的、可微的阈值单元近似。
sigmoid
(
x
)
=
1
1
+
exp
(
−
x
)
.
\operatorname{sigmoid}(x) = \frac{1}{1 + \exp(-x)}.
sigmoid(x)=1+exp(−x)1.
sigmoid函数的图像:

当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (sigmoid可以视为softmax的特例)。 然而,sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代。
修正线性单元(Rectified linear unit,ReLU), 它实现简单,同时在各种预测任务中表现良好。 ReLU提供了一种非常简单的非线性变换。 给定元素(x),ReLU函数被定义为该元素与(0)的最大值:
ReLU
(
x
)
=
max
(
x
,
0
)
.
\operatorname{ReLU}(x) = \max(x, 0).
ReLU(x)=max(x,0).
ReLU的函数图像:

在计算效率上,sigmoid表现的不如ReLU。一方面是sigmoid的计算过程太复杂,需要指数运算和倒数运算,ReLU则相当简单粗暴。另一方面是sigmoid过于平滑,而且两边有过于平坦的部分,这会导致代价函数出现太多过于平缓的部分,导致梯度下降变得缓慢。
但我们就要全部都使用ReLU函数吗,当然不是。在我们之前一直讨论的二分类问题的神经网络模型中,我们可以在隐藏层中使用ReLU激活函数,在输出层中使用sigmoid函数:
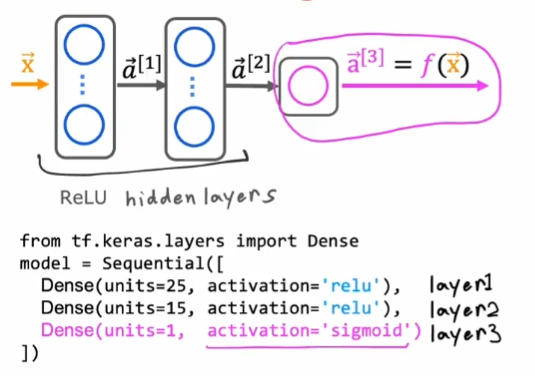
这样就兼顾了运算的效率和输出结果的准确性。
多分类问题
多分类问题实际上也仍然是一个分类问题,只是实际值y不再是0或1,而是多个数来代表多种类别。

softmax回归
为了设计出适用于多分类问题的预测函数,我们引入softmax函数。假设一共需要预测N种类别(j=1,2,3, … , N),
a
j
a_j
aj则代表在给定输入
x
⃗
\vec{x}
x的情况下第j种分类的预测值,也就是预测处于第j种分类的概率。
a
j
=
e
z
j
∑
k
=
1
N
e
z
k
=
P
(
y
=
j
∣
x
⃗
)
其中
z
j
=
w
j
⃗
x
⃗
+
b
j
j
=
1
,
2
,
3
,
.
.
.
,
N
a_j = \frac{e^{z_j}}{ \sum_{k=1}^{N}{e^{z_k} }}= P(y=j|\vec{x}) \\ 其中 z_j = \vec{w_j}\vec{x} + b_j \\ j = 1,2,3, ..., N
aj=∑k=1Nezkezj=P(y=j∣x)其中zj=wjx+bjj=1,2,3,...,N
实际上softmax在N=2时,就是sigmoid函数。也就是说sigmoid函数是softmax函数的一种特殊情况。
代价函数
我们可以通过与之前的逻辑回归对比学习softmax回归:

在softmax回归中我们使用了交叉熵损失函数(cross-entropy loss function),它是分类问题最常用的损失函数之一。 而在逻辑回归中使用的二元交叉熵损失函数,是它的一种特殊情况。
L
(
a
,
y
)
=
{
−
l
o
g
(
a
1
)
,
if
y
=
1
.
⋮
−
l
o
g
(
a
N
)
,
if
y
=
N
\begin{equation} L(\mathbf{a},y)=\begin{cases} -log(a_1), & \text{if $y=1$}.\\ &\vdots\\ -log(a_N), & \text{if $y=N$} \end{cases} \end{equation}
L(a,y)=⎩
⎨
⎧−log(a1),−log(aN),if y=1.⋮if y=N
则平均损失就是代价函数:
J
(
w
,
b
)
=
−
1
m
[
∑
i
=
1
m
L
(
a
,
y
)
]
\begin{align} J(\mathbf{w},b) = -\frac{1}{m} \left[ \sum_{i=1}^{m} L(\mathbf{a},y) \right] \end{align}
J(w,b)=−m1[i=1∑mL(a,y)]
将softmax用于神经网络
我们将之前用于手写数字识别的神经网络来修改,之前它只有一个输出单元来输出0或者1,0代表“数字不是1”,1代表“数字是1”。而现在将输出层换成softmax回归,并且有10个神经元,再将隐藏层的激活函数换为ReLU函数。

输出层输出一个向量 a ⃗ [ 3 ] \vec{a}^{[3]} a[3](10,),代表在输入为 x ⃗ \vec{x} x条件下预测手写数字分别为0~9的概率。
这样我们就得到了一个用于多分类的神经网络。
pytorch
transforms
Normalize
transforms.Normalize用于规范化(归一化)图像数据。规范化是将数据按比例缩放,使之落入一个特定的小范围内,通常是 [0, 1] 或者 [-1, 1]。这样做有助于模型的训练,因为它确保了不同特征的尺度一致,防止某些特征因为数值范围大而在训练过程中占据主导地位。
创建Normalize实例,对图像tensor进行操作,可以发现图像数据已经变化:
from torchvision import transforms
from PIL import Image
from matplotlib import pyplot as plt
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path) # 使用PIL会得到Image对象的图片
trans_tensor = transforms.ToTensor() # 创建一个转换实例
img_tensor = trans_tensor(img) # 转换成tensor
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 规范化需要参数均值和标准差,这里是假定数值
img_norm = trans_norm(img_tensor)
print(img_tensor[0, 0, 0])
print(img_norm[0, 0, 0])
在图像处理中,PyTorch张量通常以[通道, 高度, 宽度]的格式存储。然而,matplotlib的imshow函数期望图像数据以[高度, 宽度, 通道]的格式提供。tensor可以使用 .permute(1, 2, 0) 来将其重新排列为 [高度, 宽度, 通道]。
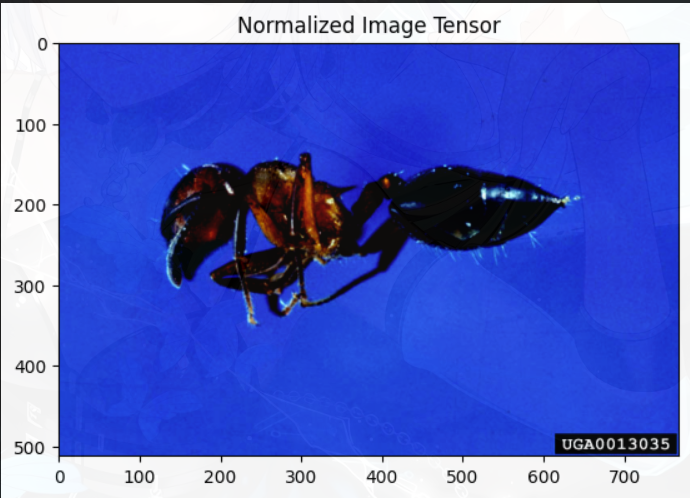
使用plt将图片展示出来,可以直观的看到规范化后图片的变化:
plt.imshow(img_tensor.permute(1, 2, 0))
plt.title('Original Image Tensor')
plt.show()

plt.imshow(img_norm.permute(1, 2, 0))
plt.title('Normalized Image Tensor')
plt.show()
Resize
transforms.Resize对PIL.Image对象进行操作。如果传入一个整数,图像将被缩放为指定的尺寸,同时保持原始图像的宽高比。如果传入一个元组,比如 (h, w),图像将被缩放到指定的宽和高。
trans_resize = transforms.Resize((512, 512))
img_resize = trans_resize(img)
print(img.size) # (768, 512)
print(img_resize.size) # (512, 512)
trans_resize = transforms.Resize(256)
img_resize = trans_resize(img)
print(img.size) # (768, 512)
print(img_resize.size) # (384, 256)
RandomCrop
transforms.RandomCrop 用于对图像进行随机裁剪。传入size参数如果是一个整数,表示裁剪的宽和高都是这个值;如果是一个元组,表示裁剪的宽和高。在训练深度学习模型时,为了提高模型的泛化能力,通常会对训练数据进行随机裁剪等操作。随机裁剪可能会裁剪掉图像的重要部分。
trans_rand = transforms.RandomCrop(256)
for i in range(10):
img_crop = trans_rand(img)
plt.imshow(img_crop)
plt.show()
在这里插入图片描述
Compose
transforms.Compose用于将多个图像变换操作组合成一个复合变换。这在数据预处理阶段非常有用,因为通常需要对图像进行一系列的变换操作,比如裁剪、缩放、归一化等。比如前面介绍的ToTensor, Normalize, Resize都可以顺序连接为一个Compose变换。
# 使用Compose将这些变换操作组合起来
trans_compose = transforms.Compose([
transforms.RandomCrop(256), # 随机裁剪
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
# 应用trans_compose
img_compose = trans_compose(img)
# 展示变换
plt.imshow(img)
plt.show()
plt.imshow(img_compose.permute(1, 2, 0))
plt.show()


torchvision的数据集
CIFAR-10
CIFAR-10 数据集是计算机视觉领域中常用的一个小型图像数据集,它被广泛用于训练和评估卷积神经网络(CNN)。该数据集由加拿大高级研究所(Canadian Institute For Advanced Research)提供,因此得名CIFAR。
CIFAR-10 包含60,000张32x32的彩色图像,分为10个类别,每个类别有6,000张图像。数据集中的图像被分为10个类别,分别是飞机、汽车、鸟类、猫、鹿、狗、青蛙、马、船和卡车,数据集被分为50,000张训练图像和10,000张测试图像。

在PyTorch的torchvision库中,CIFAR-10 数据集可以通过简单的API调用来加载:
import torchvision
from torchcision import transforms
# 下载并加载训练集
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=transforms.ToTensor())
# 下载并加载测试集
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=transforms.ToTensor())
DataLoader
DataLoader用于封装数据集,提供批量加载、打乱、多线程加载等功能。它是实现高效数据加载和预处理的关键组件。
- dataset:要加载的数据集。
- batch_size:每个批次的样本数。
- shuffle:是否在每个epoch开始时打乱数据集。
- num_workers:加载数据时使用的子进程数。
- drop_last:如果为True,会丢弃最后一个不完整的批次。
使用DataLoad加载CIFAR10数据集:
from torch.utils.data import DataLoader
data_loader = DataLoader(dataset=train_set, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
for img, labels in data_loader:
# 在这里实现训练逻辑
pass
GPU加速
在深度学习训练中,GPU(图形处理器)加速是非常重要的一部分。GPU的并行计算能力使得其比CPU在大规模矩阵运算上更具优势。PyTorch提供了简单易用的API,让我们可以很容易地在CPU和GPU之间切换计算。
在PyTorch中,我们可以使用torch.cuda.is_available()来检查:
import torch
# 检查是否有可用的GPU
if torch.cuda.is_available():
print("There is a GPU available.") # True
else:
print("There is no GPU available.") # False
如果存在可用的GPU,我们可以使用.to()方法将tensor移动到GPU上:
# 创建一个tensor
x = torch.tensor([1.0, 2.0])
# 移动tensor到GPU上
if torch.cuda.is_available():
x = x.to('cuda')
我们也可以直接在创建tensor的时候就指定其加速设备:
# 直接在GPU上创建tensor
if torch.cuda.is_available():
x = torch.tensor([1.0, 2.0], device='cuda')
在进行模型训练时,我们通常会将模型和数据都移动到GPU上:
# 创建一个简单的模型
model = torch.nn.Linear(10, 1)
# 创建一些数据
data = torch.randn(100, 10)
# 移动模型和数据到GPU
if torch.cuda.is_available():
model = model.to('cuda')
data = data.to('cuda')
自动求导
PyTorch 的自动求导(Autograd)是一个动态的自动微分系统,专门用于构建和训练深度学习模型。它允许用户以非常直观和自然的方式来定义数学计算,并自动计算梯度。
在PyTorch中,我们可以设置tensor.requires_grad=True来追踪其上的所有操作。完成计算后,我们可以调用.backward()方法,PyTorch会自动计算和存储梯度。这个梯度可以通过.grad属性进行访问。
import torch
# 创建一个张量,并设置 requires_grad=True 来自动计算梯度
x = torch.rand(2, 2, requires_grad=True)
y = torch.rand(2, 2, requires_grad=True)
# 定义一个简单的运算
z = x + y
z = z ** 2 # z = (x + y)^2
# 反向传播,计算梯度
z.backward()
# 输出梯度
print(x.grad, y.grad)
总结
本周学习了用于多分类的softmax回归,并将其用于神经网络中,与二分类方法(逻辑回归)进行了对比。学习了如何使用Pytorch的transforms进行图像处理,包括规范化和调整大小。如何使用DataLoader加载CIFAR-10数据集,以及使用GPU加速和PyTorch的Autograd提高模型训练效率方面。















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









