







文章目录
Abstract
This week’s blog discusses overfitting and underfitting in machine learning, focusing on regularization as a solution. Overfitting happens when a model is too complex and performs poorly on new data. Regularization reduces overfitting by shrinking model parameters, simplifying the model. The blog also covers its application in linear and logistic regression, and explores early stopping as a technique to prevent overfitting during training. Additionally, the blog introduces research on emotion generation models based on human needs, reviewing key emotional theories and the importance of personalized AI. The week ends with progress on a machine learning course and drafting a research paper, noting areas for improvement in writing and literature review.
机器学习
正则化(Regularization)
过拟合和欠拟合
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到**过拟合(over-fitting)和欠拟合(under-fitting)**的问题,可能会导致它们效果很差。
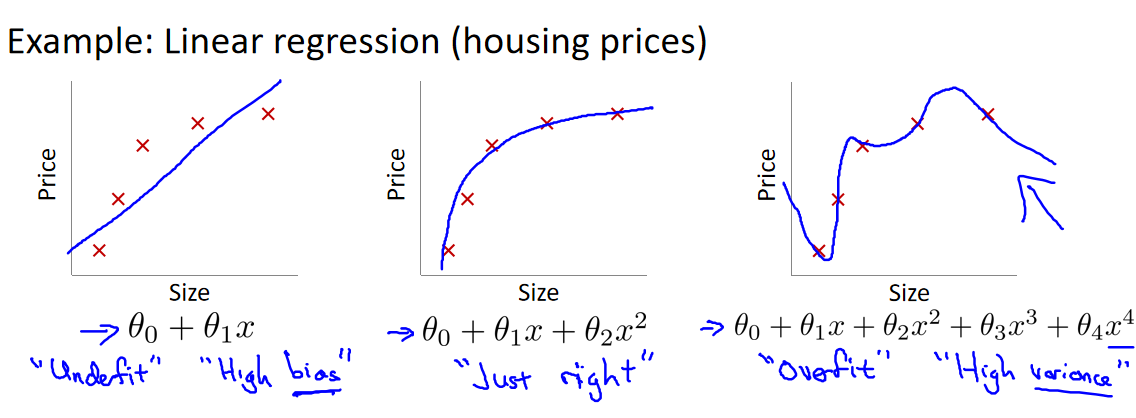
-
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;
-
第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;
-
中间的模型似乎最合适。
定义:如果一味追求提高对训练数据的预测能力,所选模型的复杂度则往往会比真模型更高。这种现象称为过拟合 (over-fitting) 。过拟合是指学习时选择的模型所包含的参数过多,以至出现模型对己知数据预测得很好,但对未知数据预测得很差的现象。(《统计学习方法》)
解决过拟合通常有三种方法:
1.收集更多的数据样本。更多的数据使拟合更稳定。
2.选择重要的特征,丢弃无关紧要的特征。使用多余的特征加入模型会使其摇摆不定。
3.利用正则化减少参数(w)的大小。
正则化的思想
直观地解释参数大小对拟合情况的影响:

当参数过多而且过大时,就可能出现过拟合的情况,如右边。所以我们如果能使得 w 3 w_3 w3和 w 4 w_4 w4非常小以至于接近0,那就可以解决过拟合,如左图。但是我们不一定知道哪些参数应该被减小,所以我们可以对所有参数都进行减小。
总之,正则化基于这样的思想:参数值越小,模型越简单。因为一个模型的特征变少了,那他过拟合的可能性也变小了。
正则化的线性回归
我们通过对代价函数增加一个正则化项,来做到正则化。正则化的线性回归的代价函数:
J ( w , b ) = 1 2 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) 2 + λ 2 m ∑ j = 0 n − 1 w j 2 (1) J(\mathbf{w},b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})^2 + \frac{\lambda}{2m} \sum_{j=0}^{n-1} w_j^2 \tag{1} J(w,b)=2m1i=0∑m−1(fw,b(x(i))−y(i))2+2mλj=0∑n−1wj2(1)
where: f w , b ( x ( i ) ) = w ⋅ x ( i ) + b f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = \mathbf{w} \cdot \mathbf{x}^{(i)} + b fw,b(x(i))=w⋅x(i)+b
为什么增加的正则化项 λ 2 m ∑ j = 0 n − 1 w j 2 \frac{\lambda}{2m} \sum_{j=0}^{n-1} w_j^2 2mλ∑j=0n−1wj2可以使w的值减小呢?
加入 ∑ j = 0 n − 1 w j 2 \sum_{j=0}^{n-1} w_j^2 ∑j=0n−1wj2使得在梯度下降时,代价变得更大,也就是说对所有参数w都进行惩罚,而且w值越大惩罚也越大,这样使所有参数都进行缩小,从而精简模型,解决过拟合。
λ \lambda λ是正则化参数,如果我们令 λ \lambda λ的值很小很接近0的话,那么正则化项将接近0,从而不能使得参数减小,过拟合得不到解决。

但若的 λ \lambda λ值过大,那么所有的参数都会趋近于0,这样我们所得到的只能是一条平行于x轴的直线。因为我们不对参数b正则化,所以最后只能得到 f ( x ) = b f(x)=b f(x)=b

所以对于正则化,我们要取一个合理的 λ \lambda λ 的值,这样才能更好的应用正则化。
除以m使得正则化这一项能随着数据规模进行缩放。
1/2则是为了求导形式简洁。
对正则化的线性回归的代价函数求导:
∂
J
(
w
,
b
)
∂
w
j
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
w
j
∂
J
(
w
,
b
)
∂
b
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
\begin{align*} \frac{\partial J(\mathbf{w},b)}{\partial w_j} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_{j}^{(i)} + \frac{\lambda}{m} w_j \\ \frac{\partial J(\mathbf{w},b)}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) \end{align*}
∂wj∂J(w,b)∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))xj(i)+mλwj=m1i=0∑m−1(fw,b(x(i))−y(i))
正则化的逻辑回归
同样,正则化的逻辑回归的代价函数:
J ( w , b ) = 1 m ∑ i = 0 m − 1 [ − y ( i ) log ( f w , b ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) ] + λ 2 m ∑ j = 0 n − 1 w j 2 (3) J(\mathbf{w},b) = \frac{1}{m} \sum_{i=0}^{m-1} \left[ -y^{(i)} \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - y^{(i)}\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \right] + \frac{\lambda}{2m} \sum_{j=0}^{n-1} w_j^2 \tag{3} J(w,b)=m1i=0∑m−1[−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))]+2mλj=0∑n−1wj2(3)
where:
f w , b ( x ( i ) ) = s i g m o i d ( w ⋅ x ( i ) + b ) (4) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = sigmoid(\mathbf{w} \cdot \mathbf{x}^{(i)} + b) \tag{4} fw,b(x(i))=sigmoid(w⋅x(i)+b)(4)
对正则化的逻辑回归的代价函数求导,形式与线性回归是完全相同的,我们在逻辑回归中已经推导过:
∂
J
(
w
,
b
)
∂
w
j
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
+
λ
m
w
j
∂
J
(
w
,
b
)
∂
b
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
\begin{align*} \frac{\partial J(\mathbf{w},b)}{\partial w_j} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_{j}^{(i)} + \frac{\lambda}{m} w_j \\ \frac{\partial J(\mathbf{w},b)}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) \end{align*}
∂wj∂J(w,b)∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))xj(i)+mλwj=m1i=0∑m−1(fw,b(x(i))−y(i))
提前停止
对于梯度下降这一类迭代学习的算法,还有一个与众不同的正则化方法,就是在验证误差达到最小值时停止训练,该方法叫作**“提前停止法”(即“早停”Early Stopping)**。
训练的复杂模型(高阶多项式回归模型),经过一轮一轮的训练,训练集上的预测误差(RMSE)自然不断下降,同样其在验证集上的预测误差也随之下降。但是,一段时间之后,验证误差停止下降反而开始回升。这说明模型开始过拟合训练数据。

通过早期停止法,一旦验证误差达到最小值就立刻停止训练。这是一个非常简单而有效的正则化技巧。
基于需求的人工智能情感生成模型-背景调研
引言
现有的人工智能情感模型,大多都是基于收集互联网数据进行训练而的来的情感模型,这种情感模型是广义上社会的情感模型,缺乏个性化与灵动。本研究提出的基于需求的情感生成模型是基于个体需求变化而产生情感变化的模型,能够使得人工智能的情感生成更加具有个性化、灵动性、因果性与可解释性。
人类情感研究的基础
人类情感一直是心理学和神经科学领域的重要研究主题。在历史上,学者们对情感的起源与机制提出了多种观点,形成了不同的理论学派。传统情感研究可分为几大代表性学派:
詹姆斯-兰格理论:詹姆斯-兰格情感理论是现代心理学最早的情感理论之一。该理论由威廉·詹姆斯 (William James) 和卡尔·兰格 (Carl Lange) 于 19 世纪提出,假设生理刺激(唤醒)会导致自主神经系统做出反应,进而导致个体体验情绪。(1)神经系统的反应可能包括心跳加快、肌肉紧张、出汗等。根据这一理论,生理反应先于情感行为。总之简单说,此理论认为情感体验是对身体状态的感知,例如“我们感到害怕,因为我们在颤抖”。

坎农-巴德理论:坎农-巴德理论与詹姆斯-兰格理论相对立,坎农(Cannon)和巴德(Bard )认为情感体验与生理反应是同时发生的,甚至,即使身体没有表现出生理反应,也可以体验到情绪。(2)

沙克特-辛格(情感二因素理论):另一个较新的理论是沙克特-辛格(Schacter-Singer)情绪理论,它引入认知评价。
理论借鉴了詹姆斯-兰格理论理论和坎农-巴德理论的元素,提出生理唤醒首先发生,但这种反应对于不同的情绪通常是相似的。该理论认为,生理反应通过促进某种认知评价,或者预估自己体内发生变化的方式,促成了情感体验。

拉扎勒斯(情感认知评估理论):拉扎勒斯(Lazarus)的情绪认知评估理论则强调了认知在情感生成中的作用。他认为情感来源于个体对环境的评估,情感并非单纯的生理反应,而是认知、评价、思考之后的结果。这一理论突出强调了个体主观对外界刺激的解读对情感生成的影响。(3)

这些情感派为人类情感的理解提供了多样化的视角和理论基础,可以发现随着情感学派的迭代,对情感的解释也逐渐从生理表现过渡到认知评价。这在某种意义上揭示了情感计算和情感人工智能的可行性。
人工智能情感研究的意义
在人类生活中,情感可以影响我们的判断力和行为反应,而对于人工智能而言,情感理解与表达则是实现人机交互自然化的重要途径。研究情感机器人是弱人工智能向强人工智能发展的趋势。也可以说,研发情感机器人(陪护机器人和聊天机器人)是社会发展的需要。
**罗莎琳德·皮卡德(Rosalind Picard)**是情感计算领域的开创者,她的研究表明,将情感融入人工智能系统不仅可以改善人机交互,还能使机器在某些任务中表现得更加智能和富有同理心。(4)
为什么人类要赋予人工智能情感呢?皮卡德提出了人类赋予机器一定情感能力的四个动机:第一个目标是创造出能够模仿活生生的人类和动物的机器人及类似的人造角色——例如,创造人形机器人(humanoid robot);第二个目标是使机器变得能智能,尽管找到一个有关机器智能性的、被广为接受的定义几乎不可能;第三个目标是通过建构情感模型来更好的了解人类的情感;第四个目标是使机器与人类之互动和沟通起来能够不那么让人沮丧和绝望。
有多少人记得微软 Office 的智能助手 Clippy?你或许不知道的是,当比尔·盖茨宣布 Clippy 将被取消,大家都给他起立鼓掌。很多人推文:“Clippy 应该被吊死!”。但是为什么他们这么恨 Clippy?Clippy 其实是个很聪明的机器学习 AI,它能准确判断你在 Word 里写的是信件还是普通文章。我认为,大家不喜欢 Clippy 的原因是:它看起来太开心了。而当 Clippy 在 Office 中出现的时候,你的心情如何?恐怕是苦逼(因为在工作)。
当你心情不好的时候,别人看到你,如果他/它有智能,他会改变表情、不再看起来开心,以免刺激到你。但做到这一点,它们需要能感知、识别你的状态;它们需要理解该状态,知道什么才是恰当的反应;它们还需要能够模拟、表现出那个恰当的回应。
---------------------------------------------------------皮卡德在AAAI 2017上的演讲(5)

需求和人类情感
马斯洛假设人类不断向自我实现的方向成长,并将人类的需求分为五个层次。从较低的层次来看,马斯洛的需求层次分为生理需求、安全需求、社会需求、社会需求/爱与归属、尊重和自我实现。人类被认为是按照从低层次向上的顺序来满足自己的需求。作为将这种需求融入机器人的一个例子,Ishiguro等人展示了Android ERICA(6)。然而,如何设置机器人应该具有的需求以及以这种方式设置需求的基础取决于研究人员。
我们希望在本文中,将一种改进的五层需求理论整合到代理模型系统中,并提出了一种基于需求来改变情感的方法。
参考文献
- The Science of Emotion: Exploring the Basics of Emotional Psychology.
- Cannon-Bard Theory and Physiological Reactions to Emotions, Verywell Mind. https://www.verywellmind.com/what-is-the-cannon-bard-theory-2794965.
- R. S. Lazarus, A. D. Kanner, S. Folkman, “EMOTIONS: A COGNITIVE–PHENOMENOLOGICAL ANALYSIS” in Theories of Emotion (Elsevier, 1980; https://linkinghub.elsevier.com/retrieve/pii/B9780125587013500144), pp. 189–217.
- Affective Computing, Rosalind Picard
. https://mitpress.mit.edu/9780262661157/affective-computing/. - 阳烁, 王硕, 人类情感与机器情感:人工智能领域的情感研究. 美术馆, 63–71 (2020).
- H. Ishiguro, T. Minato, T. Koyama, Development of an Autonomous Android with Conversational Capability based on Intention and Desire意図欲求を持つ自律対話アンドロイドの研究開発. Journal of the Robotics Society of Japan 37, 312–317 (2019).
总结
本周完成了机器学习正则化的学习,主要学习了正则化的原理和在线性回归逻辑回归中的应用。同时完成了吴恩达机器学习课程(一)监督学习,下周开始学习第二部分,(二):高级学习算法 Advanced Learning Algorithms。
本周对论文(题目:基于需求的人工智能情感生成模型)进行了前期的背景调研和引言起草。但是对于文献的检索和阅读还不熟练,文章的书写也多有不流畅的地方,参考文献也有诸多差错。下一阶段需要修改和重新排编。















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









