







文章目录
Abstract
This week’s report focuses on the basics of neural networks and multilayer perceptrons (MLP). It discusses the concept of neurons and their mathematical models as a solution. The report explains how MLP are structured with input, hidden, and output layers, and the significance of forward propagation in computing predictions. It also includes exercises from the accompanying lecture notes, which involve constructing neural networks using TensorFlow and implementing dense layers using NumPy for a deeper understanding of the underlying operations. Lastly, it touches on back propagation for optimizing neural networks and introduces PyTorch tensors and operations, as well as torchvision transforms for image processing.
机器学习
神经网络基础-多层感知机(MLP)
非线性假设
无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
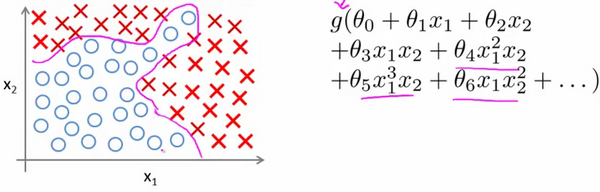
当我们使用
x
1
x_1
x1,
x
2
x_2
x2的多次项式进行预测时,我们可以应用的很好。假设我们有非常多的特征,例如大于100个变量,我们希望用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合
x
1
x
2
+
x
1
x
3
+
.
.
.
+
x
99
x
100
x_1x_2+x_1x_3+...+x_{99}x_{100}
x1x2+x1x3+...+x99x100,我们也会有接近5000个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。
普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我们需要神经网络。
模型表示
神经元与大脑
每个神经元是可以被认为一个处理单元/神经核processing unit/Nucleus,主要包含:
- 多个输入/树突(input/Dendrite)
- 一个输出/轴突(output/Axon)

现在神经网络被用在各个领域,然而今天的神经网络几乎与大脑的学习方式毫无关系。如今的神经网络领域发展也已经远离了企图构建模拟大脑为出发点。
神经元的数学模型
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(激活单元activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被称为权重(weight)。
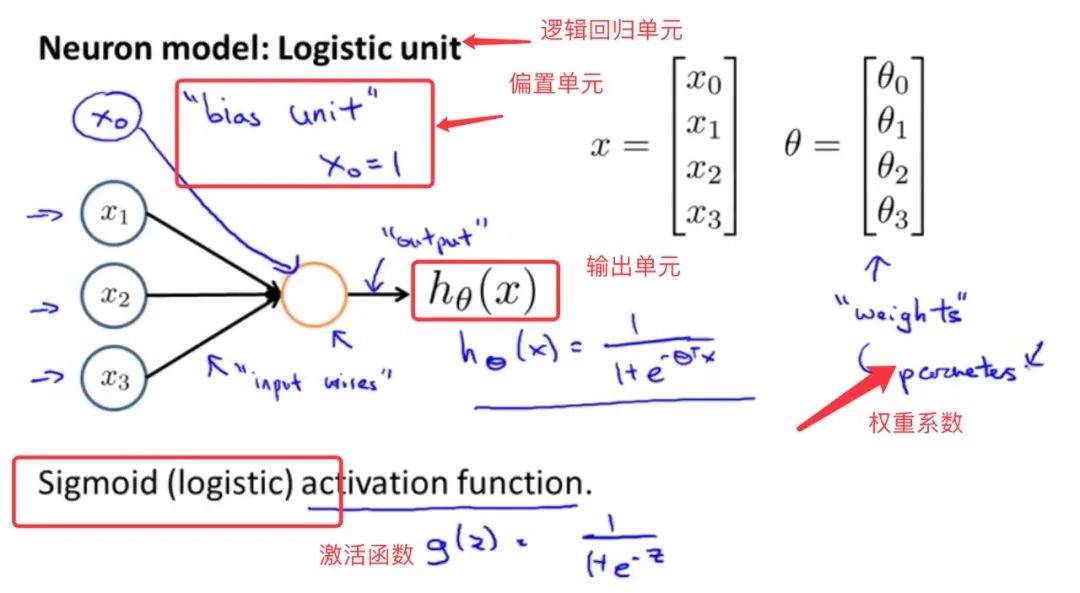
通俗来讲,每一个激活单元都在充当一个逻辑回归的模型角色:

神经网络模型
我们设计出了类似于神经元的神经网络,效果如下:将许多神经元堆叠在一起成为一层,每一层都输出(连接)到下一层,直到生成最后的输出。 我们可以把前L−1层看作表示,把最后一层看作线性预测器。 这种架构通常称为多层感知机(multilayer perceptron),通常缩写为MLP。
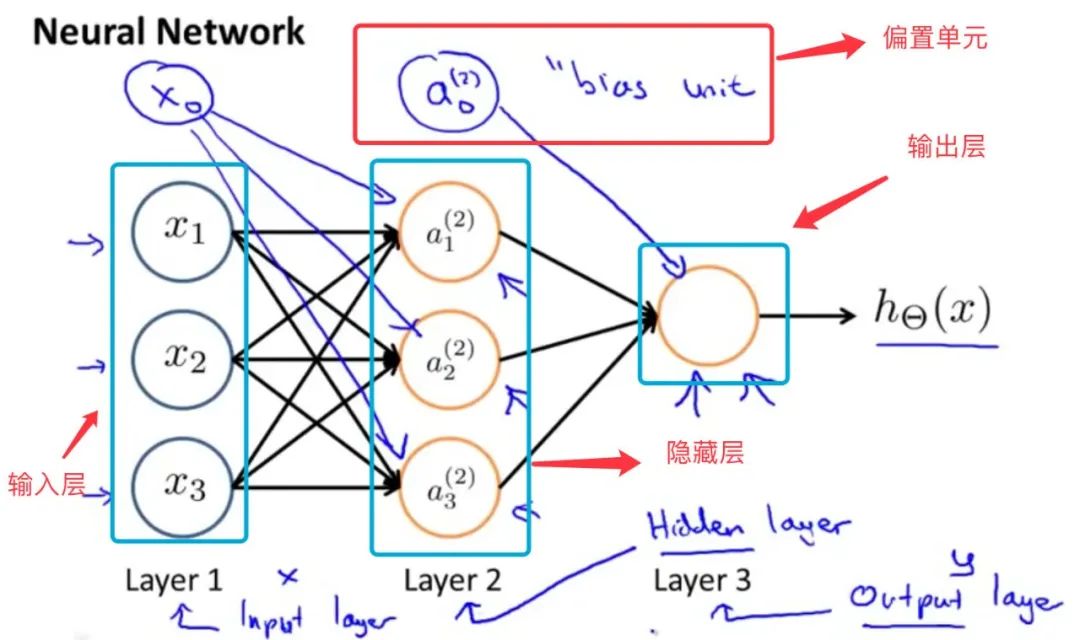
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单位(bias unit)
神经网络层
因为神经网络层级很多,我们添加标记来方便描述数学模型:
- a j [ i ] a_j^{[i]} aj[i]代表第i层的第j个激活单元的激活值
- w ⃗ j [ i ] \vec{w}_j^{[i]} wj[i]矢量代表第i层的第j个激活单元的权重
- b j [ i ] {b}_j^{[i]} bj[i]代表第i层的第j个激活单元的偏置值
于是我们得到了第i层第j个激活单元的输出表达式:

前向传播(forward propagation)
神经网络为了根据输入数据计算出预测结果,要进行前向传播(forward propagation)。这个过程中,每一层的输出会成为下一层的输入,直到最后一层。
具体步骤如下:
- 输入层 —> 隐藏层计算:输入层接收原始数据输入,数据在第一层隐藏层中通过加权求和,然后通过激活函数进行非线性变换,然后将计算出的激活值输入到下一层。
- 隐藏层 —> 隐藏层计算:接收上一层隐藏层输入,数据在每一层(隐藏层)中通过加权求和,然后通过激活函数进行非线性变换,然后将计算出的激活值输入到下一层。
- 隐藏层 —> 输出层计算:输出层使用前一层(最后一层隐藏层)的输出作为输入,通过激活函数进行非线性变换后,再通过一个设定了阈值的预测函数,得到最终的预测结果。
下面通过一个手写数字识别的抽象神经网络来解释前向传播过程,此模型输入8*8=64的图像数据,输出0或者1,0代表“数字不是1”,1代表“数字是1”。

隐藏层layer1含有25个单元,将输入数据向量x(64,),经过每个单元的激活函数计算后输出,整一层的激活值作为激活向量 a ⃗ [ 1 ] \vec{a}^{[1]} a[1](25,)输出到下一层。

隐藏层layer2含有15个单元,将上一层的激活向量 a ⃗ [ 1 ] \vec{a}^{[1]} a[1](25,)作为输入,经过每个单元的激活函数计算后输出,整一层的激活值作为激活向量 a ⃗ [ 2 ] \vec{a}^{[2]} a[2](15,)输出到下一层。

输出层layer3只有1个单元,将上一层的激活向量 a ⃗ [ 2 ] \vec{a}^{[2]} a[2](15,)作为输入,单元的激活函数计算后输出一个激活值 a [ 3 ] a^{[3]} a[3],再经过一个简单的逻辑判断(如果激活值>=0.5则最终预测值为1,否则预测值为0)输出预测值 y ^ \hat{y} y^
作业练习1-excise1
以下三个作业练习都来自配套讲义实验C2_W1_Assignment.ipynb,注意本课程使用的深度学习框架是TensorFlow,所以涉及框架到部分将使用tensorflow进行实现。
Tensorflow模型是逐层构建的。你需要指定每一层的输出维度,这将决定下一层的输入维度。下面,使用Keras Sequential model和Dense Layer和sigmoid函数来构建上面描述的网络:
# UNQ_C1
# GRADED CELL: Sequential model
model = Sequential(
[
tf.keras.Input(shape=(400,)), #specify input size 输入层
### START CODE HERE ###
Dense(25, activation="sigmoid"), # 隐藏层layer1
Dense(15, activation="sigmoid"), # 隐藏层layer2
Dense(1, activation="sigmoid") # 输出层layer3
### END CODE HERE ###
], name = "my_model"
)
作业练习2-excise2
假如我们不使用现成的框架,为了更好的了解运算原理,使用NumPy构建自己的Dense层:
# UNQ_C2
# GRADED FUNCTION: my_dense
def my_dense(a_in, W, b, g):
"""
Computes dense layer
Args:
a_in (ndarray (n, )) : Data, 1 example
W (ndarray (n,j)) : Weight matrix, n features per unit, j units
b (ndarray (j, )) : bias vector, j units
g activation function (e.g. sigmoid, relu..)
Returns
a_out (ndarray (j,)) : j units
"""
units = W.shape[1]
a_out = np.zeros(units)
### START CODE HERE ###
units = W.shape[1]
a_out = np.zeros(units)
for j in range(units):
w = W[:,j] # Select weights for unit j. These are in column j of W
z = np.dot(w, a_in) + b[j] # dot product of w and a_in + b
a_out[j] = g(z) # apply activation to z
### END CODE HERE ###
return(a_out)
作业练习3-excise3
但是使用for循环不能很好的处理大量数据,效率低下,所以应该用矩阵乘法来优化上面的计算,事实上深度学习框架背后的原理正是使用了大量的矩阵运算来提高效率
# UNQ_C3
# UNGRADED FUNCTION: my_dense_v
def my_dense_v(A_in, W, b, g):
"""
Computes dense layer
Args:
A_in (ndarray (m,n)) : Data, m examples, n features each
W (ndarray (n,j)) : Weight matrix, n features per unit, j units
b (ndarray (1,j)) : bias vector, j units
g activation function (e.g. sigmoid, relu..)
Returns
A_out (tf.Tensor or ndarray (m,j)) : m examples, j units
"""
### START CODE HERE ###
Z = np.matmul(A_in, W) + b # 矩阵乘法
A_out = g(Z)
### END CODE HERE ###
return(A_out)
反向传播(back propagation)
如果我们像逻辑回归那样利用梯度下降来优化参数的话,跟之前一样,梯度下降法也是通过求 J ( θ ) 的偏导数来更新参数的话,我们需要计算所有权重的梯度,求导和计算将变得非常复杂。所以我们引入误差反向传播算法来简化计算。

以此4层神经网络为例,为简化计算没有添加偏置值。
代价函数这里我们考虑最简单的情况,k=1,并且只考虑一个训练样本。
J
(
θ
)
=
−
y
log
(
h
(
x
)
)
−
(
1
−
y
)
log
(
1
−
h
(
x
)
)
J(\theta) = -y \log(h(x)) - ( 1 - y) \log ( 1 - h(x))
J(θ)=−ylog(h(x))−(1−y)log(1−h(x))
也就是我们在逻辑回归中使用的代价函数,这个函数实际上称为二元交叉熵损失函数(Binary Cross-Entropy Lossfunction)
激活函数g是sigmoid函数。
推导过程如下:
我们得到每一层的误差后就可以得到每一层的梯度了:

于是有了每一层的梯度后就可以对每一层进行权重更新了
θ ( i − 1 ) : = θ ( i − 1 ) + α D i \theta^{(i-1)} := \theta^{(i-1)} + \alpha D^{i} θ(i−1):=θ(i−1)+αDi (注意这里第i层的权重上标为i-1)
由此可见,通过循环以下步骤更新优化神经网络:
- 我们通过定义一个误差 δ \delta δ,从而从后向前一步一步推出每层神经元的误差。(使用链式求导)
- 而得到误差后,我们推出每一层的梯度 D D D。(使用链式求导)
- 得到梯度之后就可以对每一层的权重进行更新。
- 这一轮权重更新完之后,再进行一次前向传播更新预测值。
pytorch
Tensor
Tensor(张量)是PyTorch中最基本的数据结构,你可以将其视为多维数组或者矩阵。PyTorch tensor和NumPy array非常相似,但是tensor还可以在GPU上运算,而NumPy array则只能在CPU上运算。
一些创建tensor的方法:
# 创建一个未初始化的5x3矩阵
x = torch.empty(5, 3)
print(x)
# 创建一个随机初始化的5x3矩阵
x = torch.rand(5, 3)
print(x)
# 创建一个5x3的零矩阵,类型为long
x = torch.zeros(5, 3, dtype=torch.long)
print(x)
# 直接从数据创建tensor
x = torch.tensor([5.5, 3])
print(x)
对tensor的一些操作:
# 索引和切片
print(x_data[0, 1]) # 输出第二行第二列的元素
# 修改 Tensor
x_data[0, 1] = 5
# 改变形状
x_reshaped = x_data.view(1, 4) # 将 x_data 改为 1x4 的形状
# 计算两个 Tensor 的和
y_data = torch.ones_like(x_data)
z_data = x_data + y_data
transforms
transforms是torchvison中的一个工具库,它提供了一系列用于图像处理的预定义函数,这些函数可以改变图像的大小、颜色、裁剪等方面,常用于机器学习和计算机视觉任务中的数据预处理和数据增强。
ToTensor
ToTensor可以将Iamge或者ndarray对象转换成tensor,从而方便对图像数据的处理
from torchvision import transforms
from PIL import Image
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path) # 使用PIL会得到Image对象的图片
img_trans = transforms.ToTensor() # 创建一个转换实例
img_tensor = img_trans(img) # 转换成tensor
from torchvision import transforms
import cv2
img_path = "dataset/train/ants/0013035.jpg"
img = cv2.imread(img_path) # 使用cv2会得到ndarray对象的图片
img_trans = transforms.ToTensor() # 创建一个转换实例
img_tensor = img_trans(img) # 转换成tensor
总结
本周学习了神经网络的基础结构,这是一种非常重要的算法,对前向传播和反向传播进行了推导,但是对于推导过程的细节任然有不懂的地方,推导过程也进行了简化,还需要进一步理解。pytorch学习了基本的数据形式tensor,以及通过tansforms将图片转换为tensor。















 6076
6076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









