







 文章介绍了CLIP和BLIP在图文匹配领域的技术升级,包括BLIP对数据质量提升的方法(Captioner-Filter)、融合ITM和LM任务的MED框架,以及BLIP2如何通过Q-Former解决模型规模扩大的问题。
文章介绍了CLIP和BLIP在图文匹配领域的技术升级,包括BLIP对数据质量提升的方法(Captioner-Filter)、融合ITM和LM任务的MED框架,以及BLIP2如何通过Q-Former解决模型规模扩大的问题。
CLIP
使用网络上爬取得到的大量图文对进行对比学习,图文匹配的是正样本,图文不匹配的是负样本,使匹配样本的embedding之间的距离尽可能小,不匹配样本间的距离尽可能大。
缺点:网上爬的数据质量差,不能进行生成式任务。
BLIP
CLIP只有ITC(Image Text Contrastive)任务,但不能做生成式的任务,而BLIP则提出了一个新的框架将ITM(Image Text Match)和LM(Language Model,即生成文本)的任务融合在一个框架里,称为Mutimodal mixture of Encoder-Decoder (MED)。
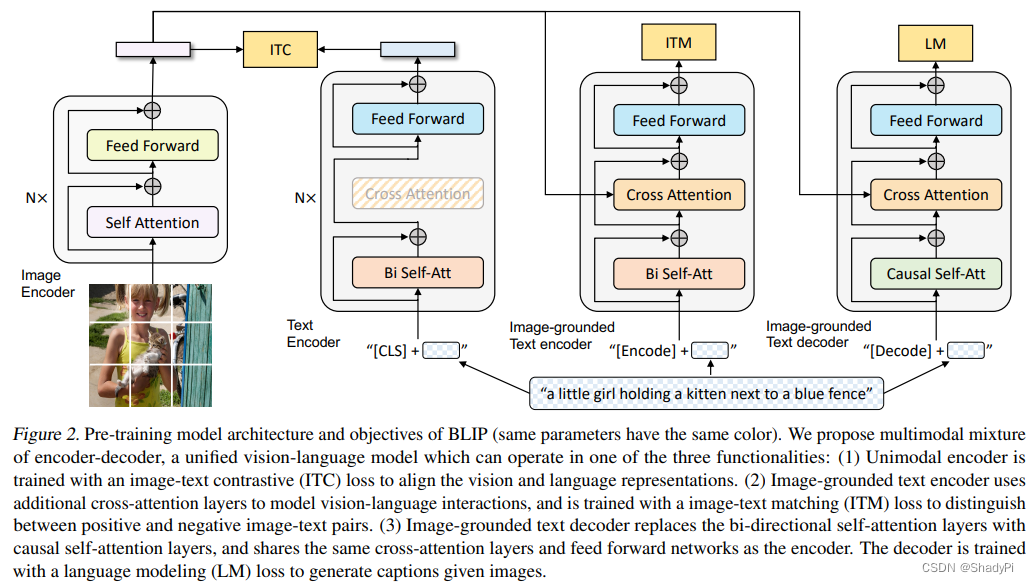
ITC做的任务跟CLIP几乎一致;而ITM的任务是一个二分类,输出图文是否匹配;LM任务就是根据图片输出对应文本。这三个任务将在同一框架下一起训练。
对于CLIP中爬取的数据噪声太多的问题,BLIP也提出了一个全新框架,Captioner-Filter框架,类似一个数据增强训练框架。左侧浅紫色的部分对应上图的整个训练框架, T w T_w Tw和 T s T_s T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











