







模型与数据集简介
1、BLOOM-1b4-zh模型介绍
BLOOM架构类型:基于Transformer的Decoder-only结构(类似GPT),由多层Transformer解码器堆叠而成。
Langboat/BLOOM-1b4-zh 是一个基于 BLOOM 架构的中文预训练语言模型,由 Langboat(浪博科技) 开发。它是 BLOOM 系列模型的一个变体,专门针对中文语言任务进行了优化。



2、Alpaca_data_zh数据集介绍
Alpaca_data_zh 是一个专门针对中文任务的数据集,用于训练和微调语言模型(如 LLaMA、Alpaca 等),使其能够更好地理解和生成中文文本。该数据集通常用于指令微调(Instruction Tuning),旨在提升模型在中文任务上的表现,尤其是对话、问答和指令执行等任务。


一、BitFit 微调(bias)
只训练bias参数,其余参数冻结,较简单,不需要peft
1、BitFit简介

2、BitFit微调-代码实现
Step1 导入相关包
from datasets import Dataset
from transformers import (AutoTokenizer, AutoModelForCausalLM,
DataCollatorForSeq2Seq,
TrainingArguments, Trainer)Step2 加载数据集
# .load_from_disk():类方法,用于加载预先通过 .save_to_disk() 保存的数据集
ds = Dataset.load_from_disk("../data/alpaca_data_zh/")
ds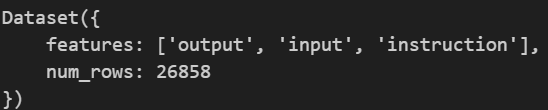
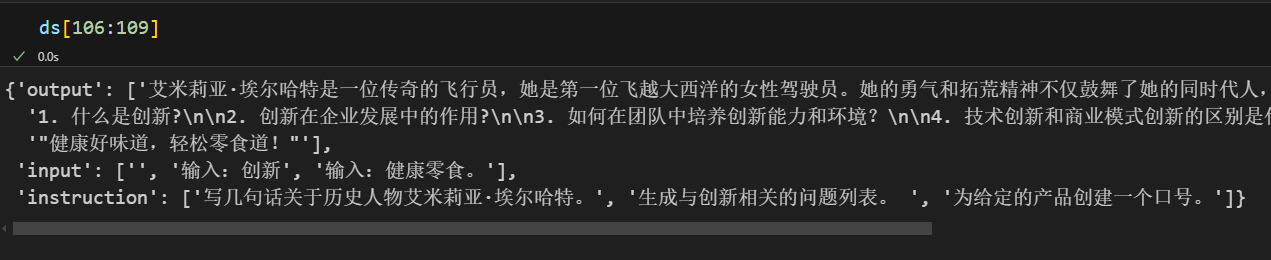
Step3 数据集预处理
tokenizer = AutoTokenizer.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh")
tokenizerdef process_func(example):
MAX_LENGTH = 256 # 定义输入序列最大长度
# input_ids, attention_mask, labels = [], [], []
# 拼接指令模板并分词(Human角色部分)
instruction = tokenizer(
"\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ",
truncation=True # 可选:若需提前截断,可在此处添加
)
# 处理回答并添加EOS标记(Assistant角色部分)
response = tokenizer(
example["output"] + tokenizer.eos_token, # 添加结束符
truncation=True # 可选:同上
)
# 合并输入和回答的token
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
# 生成labels(仅计算Assistant部分的loss)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
# 整体长度截断
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds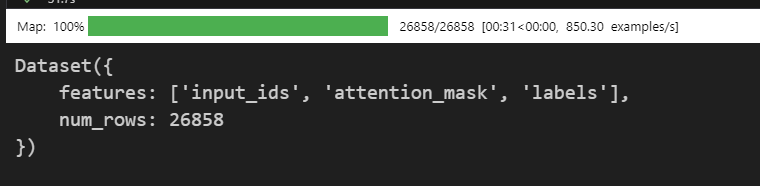


Step4 创建模型
#low_cpu_mem_usage=True通常用于减少模型推理时的CPU和内存使用
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh",
low_cpu_mem_usage=True,
local_files_only=True)sum(param.numel() for param in model.parameters())
当一个模型有 13 亿个参数时,在使用单精度浮点数(FP32)进行训练的情况下,完整的模型、梯度和优化器状态大约需要 20.8GB 的显存或内存。
BitFit
# 选择模型参数里面的所有bias部分
num_param = 0
for name, param in model.named_parameters():
if "bias" not in name:
param.requires_grad = False
else:
num_param += param.numel()
print(num_param)
print(num_param / sum(param.numel() for param in model.parameters()))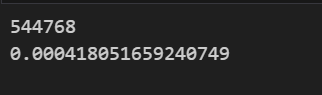
Step5 配置训练参数
args = TrainingArguments(
output_dir="./chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1
)Step6 创建训练器
trainer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)Step7 模型训练
trainer.train()model = model.cuda()
inputs = tokenizer("Human: {}\n{}".format("考试有哪些技巧?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
tokenizer.decode(model.generate(**inputs, max_length=128, do_sample=True)[0], skip_special_tokens=True)当 do_sample=False 时,这意味着在每一个时间步,模型都会选择具有最高概率的下一个词。这种方法简单快速,但可能会导致生成的文本过于保守,缺乏多样性,因为总是选择最可能的选项,可能会错过一些虽然概率较低但能产生更有趣或更合理文本的词。
当 do_sample=True 时,模型会根据词的概率分布进行随机采样。在每个时间步,下一个词的选择是基于其预测概率的随机过程。这增加了生成文本的多样性和创造性,因为即使概率较低的词也有机会被选中。为了控制这种随机性,通常还会配合使用其他参数,如temperature、top_k和top_p等,来调整采样的范围和概率分布。
Step8 模型推理
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)inputs = "Human: {}\n{}".format("考试有哪些技巧?", "").strip() + "\n\nAssistant: "
pipe(inputs, max_length=256, do_sample=True, )二、Prompt Tuning
在输入数据前加一小段提示词(人工设计/可学习提示词),仅训练增加的prompt,即一个Embedding模块
1、Prompt Tuning简介






2、代码实现
步骤与BitFit基本一样,仅需修改Step4 创建模型部分参数
Step4 创建模型
#low_cpu_mem_usage=True通常用于减少模型推理时的CPU和内存使用
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh",
low_cpu_mem_usage=True,
local_files_only=True)Prompt tuning
PEFT Step1 配置文件
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit
# Soft Prompt 是通过学习得到的连续向量表示,用于引导模型生成特定任务的输出。
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)
config
# Hard Prompt 手工设计的提示词
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM,
# prompt_tuning_init=PromptTuningInit.TEXT,
# prompt_tuning_init_text="下面是一段人与机器人的对话。",
# num_virtual_tokens=len(tokenizer("下面是一段人与机器人的对话。")["input_ids"]),
# tokenizer_name_or_path=r"D:\bigmodel_code\models\bloom-1b4-zh")
# configPEFT Step2 创建模型
model = get_peft_model(model, config)
model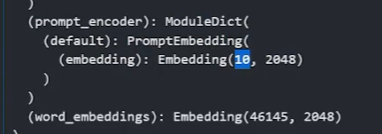

加载训练好的PEFT模型
from peft import PeftModel
# 在一个jupyter文件中,如果前面已经加载了模型,并对模型做了一定修改,则需要重新加载原始模型
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh")
peft_model = PeftModel.from_pretrained(model=model, model_id="./chatbot/checkpoint-20/")三、P-tuning
与prompt-tuning一样,增加一个Embedding模块,只是在prompt-tuning上有所改进,向量由LSTM或MLP生成
1、简介
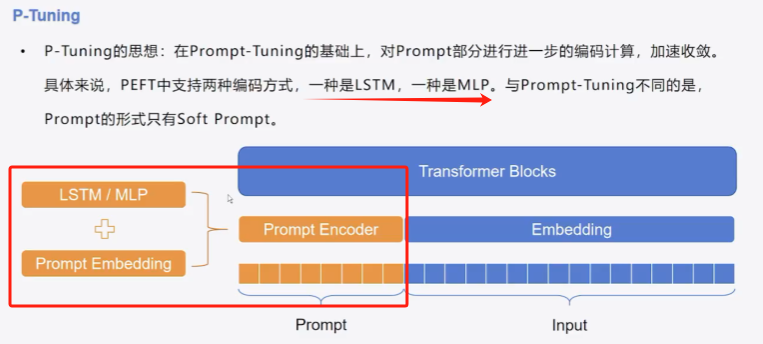
LSTM(Long Short-Term Memory,长短期记忆网络) 是一种特殊的循环神经网络(RNN),专为解决传统RNN在处理长序列数据时的梯度消失/爆炸问题而设计。


2、代码实现
步骤与前面的基本一样,仅需修改Step4 创建模型部分参数
Step4 创建模型
#low_cpu_mem_usage=True通常用于减少模型推理时的CPU和内存使用
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh",
low_cpu_mem_usage=True,
local_files_only=True)P-tuning
PEFT Step1 配置文件
from peft import PromptEncoderConfig, TaskType, get_peft_model, PromptEncoderReparameterizationType
config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM,
num_virtual_tokens=10,
encoder_reparameterization_type=PromptEncoderReparameterizationType.MLP,
encoder_dropout=0.1,
encoder_num_layers=5,
encoder_hidden_size=1024)
configPEFT Step2 创建模型
model = get_peft_model(model, config)
model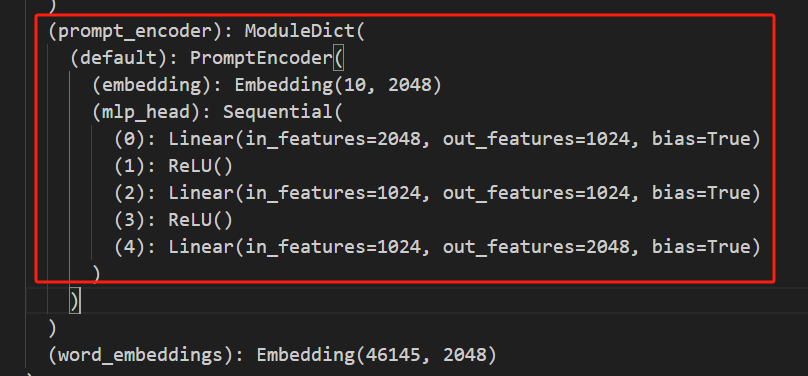

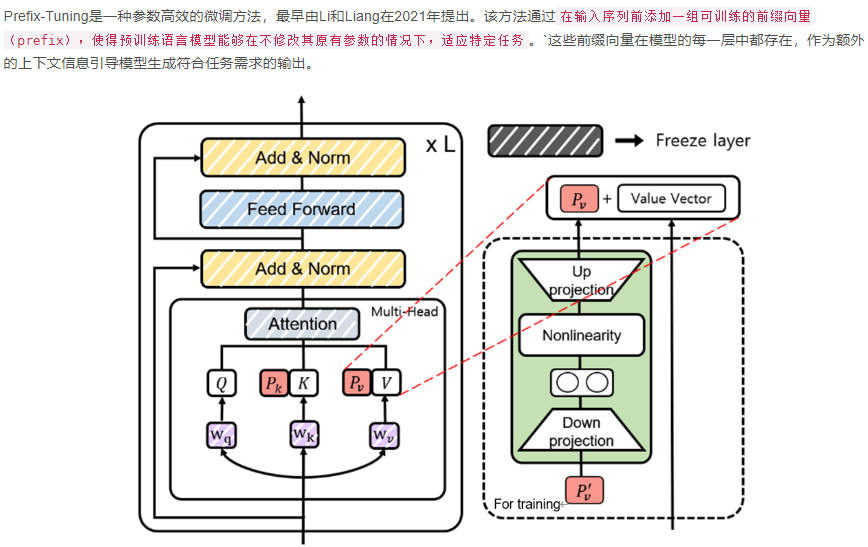
四、Prefix-tuning
增加可训练的前缀向量,作用于transformer每一层的 k 和 v
Prefix-Tuning 的核心思想是在每一层 Transformer 的自注意力机制中引入一组可训练的前缀向量,这些前缀向量作为额外的键和值,影响注意力的分布,从而引导模型适应特定任务。
1、简介
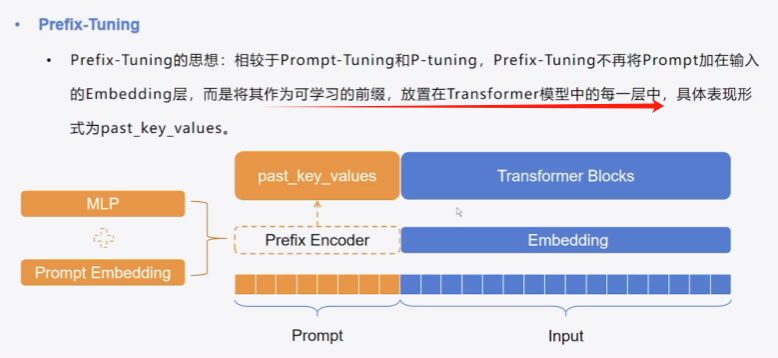



2、代码实现
步骤与前面的基本一样,仅需修改Step4 创建模型部分参数
Step4 创建模型
#low_cpu_mem_usage=True通常用于减少模型推理时的CPU和内存使用
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh",
low_cpu_mem_usage=True,
local_files_only=True)Prefix-tuning
PEFT Step1 配置文件
from peft import PrefixTuningConfig, get_peft_model, TaskType
#num_virtual_tokens 虚拟token的数量,换句话说就是提示(prompt)
#prefix_projection 是否投影前缀嵌入(token),默认值为false,表示使用P-Tuning, 如果为true,则表示使用 Prefix Tuning
config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10, prefix_projection=True)
configPEFT Step2 创建模型
model = get_peft_model(model, config)
model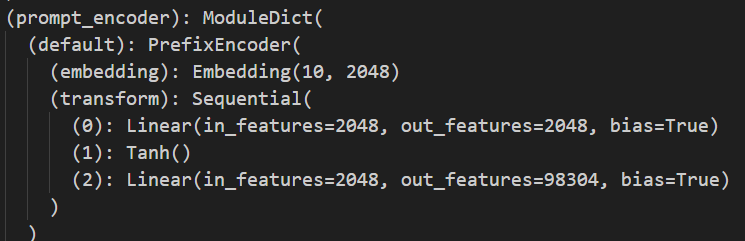

五、ia3
1、简介
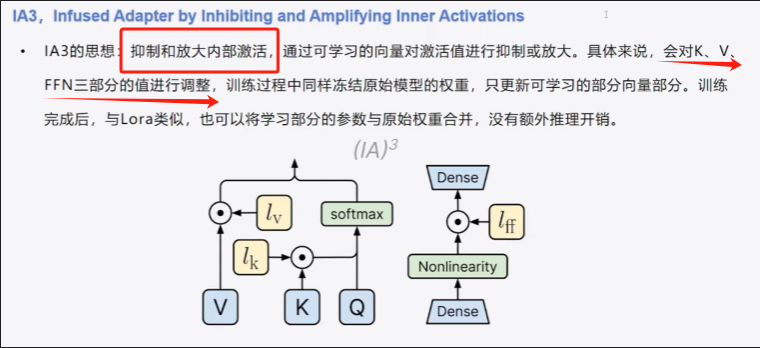
2、代码实现
步骤与前面的基本一样,仅需修改Step4 创建模型部分参数
Step4 创建模型
#low_cpu_mem_usage=True通常用于减少模型推理时的CPU和内存使用
model = AutoModelForCausalLM.from_pretrained(r"D:\bigmodel_code\models\bloom-1b4-zh",
low_cpu_mem_usage=True,
local_files_only=True)IA3
PEFT Step1 配置文件
from peft import IA3Config, TaskType, get_peft_model
config = IA3Config(task_type=TaskType.CAUSAL_LM)
configPEFT Step2 创建模型
model = get_peft_model(model, config)
model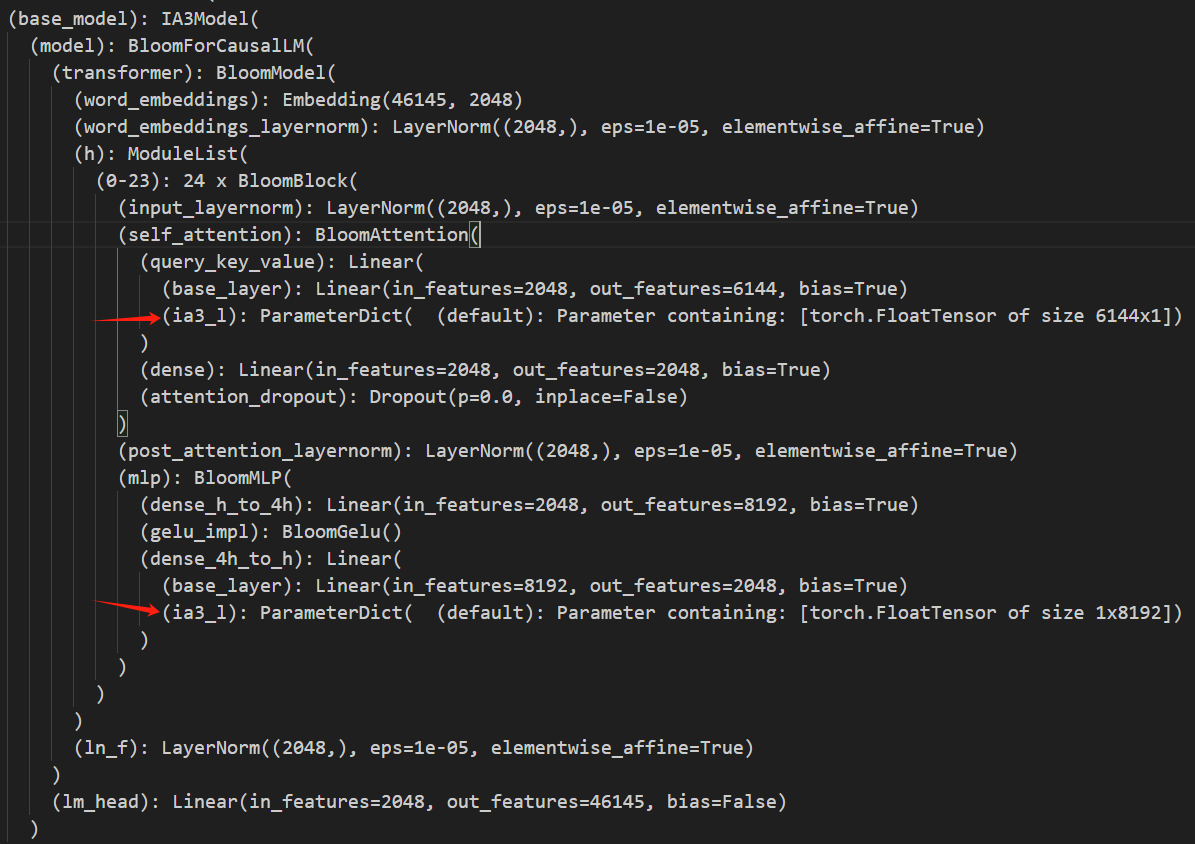

六、PEFT 进阶操作

1、自定义模型适配
import torch
from torch import nn
from peft import LoraConfig, get_peft_model, PeftModelnet1 = nn.Sequential(
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 2)
)
net1
config = LoraConfig(target_modules=["0"])
model1 = get_peft_model(net1, config)
model1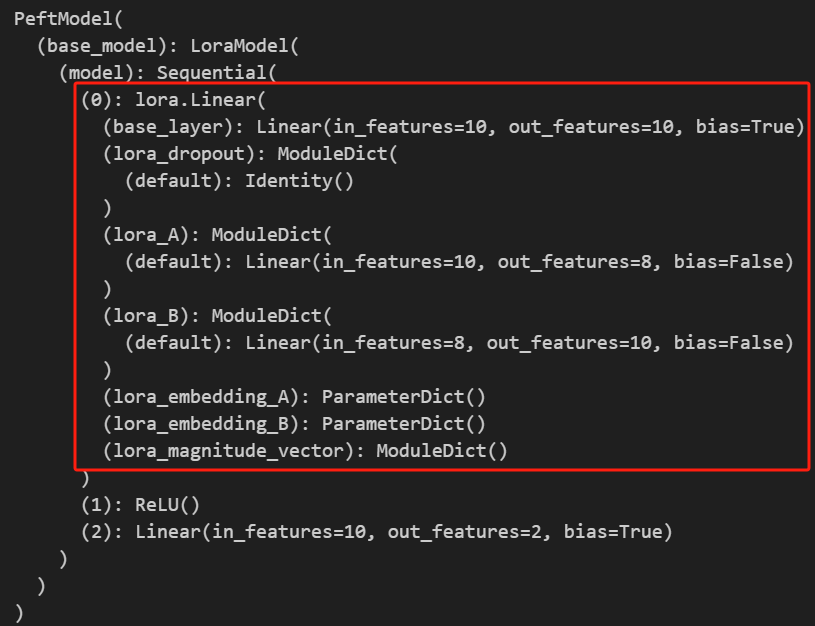
2、多适配器加载与切换
net1 = nn.Sequential(
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 2)
)
net1
config1 = LoraConfig(target_modules=["0"])
model2 = get_peft_model(net2, config1)
model2.save_pretrained("./loraA")
config2 = LoraConfig(target_modules=["2"])
model2 = get_peft_model(net2, config2)
model2.save_pretrained("./loraB")# 初始化模型
net2 = nn.Sequential(
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 2)
)
# 加载适配器A
model2 = PeftModel.from_pretrained(net2, model_id="./loraA/", adapter_name="adapter_A")
# 加载适配器B
model2.load_adapter("./loraB/", adapter_name="adapter_B")# 查看正在启用的适配器
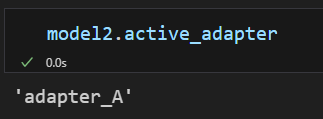
model2.set_adapter("adapter_B")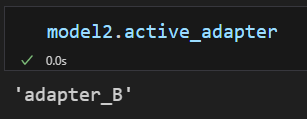
3、禁用适配器
with model2.disable_adapter():
print(model2(torch.arange(0, 10).view(1, 10).float()))
print(model2.active_adapter)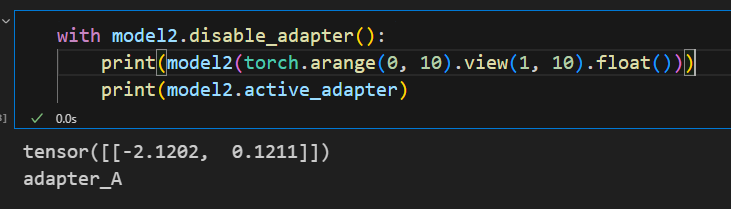

















 5688
5688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









