







本节介绍深度学习的需要掌握的基础python语法并引出一个小的实例,注意需要安装完整环境
numpy
根据我们之前的学习,我们了解到python进行深度学习都是通过矩阵运算得出来的,所以,我们引入numpy来进行矩阵的运算。
import numpy #矩阵
import numpy as np
import torch
#tensor 张量、多维矩阵,放在torch里面运算
list1 = [[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]]
array = np.array(list1) #放进向量里面,写成向量形式
print(list1)
print(array)
array2 = np.array(list1)
print(array2)
print(np.concatenate((array, array2), axis=1))
array()使数组变成向量,np.concatenate()函数作用为将两个矩阵合并,axis为矩阵扩张方向。,输出后结果为:
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
[[ 1 2 3 4 5 1 2 3 4 5]
[ 6 7 8 9 10 6 7 8 9 10]
[11 12 13 14 15 11 12 13 14 15]]
list1[1:3]表示输出数组下标从[1,3),也就是从0个开始数,第一个和第二个,
同样,array[1:3]表示输出矩阵第[1,3)行。
如果想要输出矩阵中特定的第几行几列,可以多写,比如array[1:3,1:3]
print(list1[1:3])
print(array[1:3])
print((array[1:3, 1:3])) //输出矩阵中第1行到第2行,第1列到第2列
输出为:
[[6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]
[[ 6 7 8 9 10]
[11 12 13 14 15]]
[[ 7 8]
[12 13]]
如果要取第几列,可以用以下方法:
idx = [1, 3]
print(array[:, idx])
输出为:
[[ 2 4]
[ 7 9]
[12 14]]
转为张量,tensor
把矩阵放到tensor神经网络,用torch求每个节点的导数
tensor = torch.tensor(array)
print(tensor)
输出:
tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]], dtype=torch.int32)
torch基本作用-求导
代码如下(示例):
x = torch.tensor(3.0)
x.requires_grad_(True) #表示x需要计算梯度
print(x)
y = x**2
y.backward() #backward用来求每个值的梯度
print(x.grad) #x平方求导 2x ,x = 3 ,所以为6
输出为:
tensor(3., requires_grad=True)
tensor(6.)
此时,x已经在张量网上,需要对x进行操作的话,需要把x取下来,用到detach。
创建张量
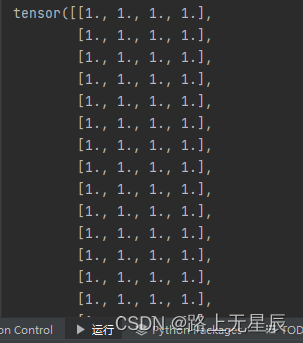
tensor1 = torch.ones((100, 4))
print(tensor1)
输出后,就可以创建一个高为100,宽为4,元素为1的张量。
创建随机函数,正态分布,方差、均值
tensor1 = torch.normal(0, 1, (15, 5))
print(tensor1)
小的回归代码实例
首先,我们需要引入数据
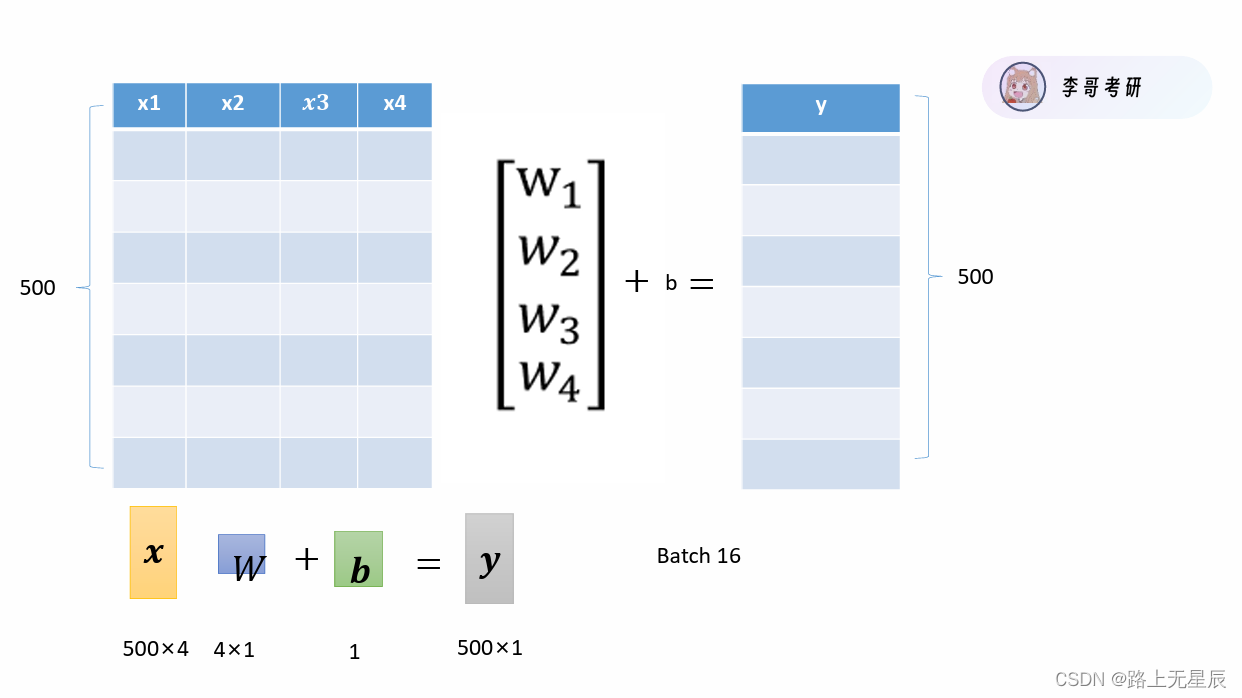
 输入外貌、性格、财富、内涵,输出恋爱次数,w为权重、b为偏差
输入外貌、性格、财富、内涵,输出恋爱次数,w为权重、b为偏差
我们需要以下这些数据,w和b我们都会有真实值,x和y需要创建数据。
永远记得我们求的不是x和y,而是希望预测值w和b与真实值相近
#引入必须的包
import torch #求导用
import matplotlib.pyplot as plt # 画图
import random # 随机数
def create_data(w, b, data_num): #生成数据,需要w(矩阵)和b,
x = torch.normal(0, 1, (data_num, len(w))) #生成随机数矩阵,方差为0,均值为1,形状有data_num行,len(w)列
y = torch.matmul(x, w) + b #y = x * w + b
noise = torch.normal(0, 0.1, y.shape) #一些噪声,模拟真实情况,与y保持同型
y += noise #将噪声加到y值上
return x, y #返回生成的数据x和y
num = 500 #创建500个数
true_w = torch.tensor([8.1, 2, 2, 4]) #w的真实值,需要转为张量才能运算
true_b = torch.tensor(1.1) #b的真实值,需要转为张量才能运算
X, Y = create_data(true_w, true_b, num) #创建出一笔X 500,4和Y 500,1的数据
plt.scatter(X[:, 0], Y, 1) #scatter用来画散点图
plt.show() #显示图像
def data_provider(data, label, batchsize): #数据提供器,每次访问就提供一笔数据,而不是所有数据处理完的loss
length = len(label) #求label长度
indices = list(range(length)) #将label下标表示为一个列表
random.shuffle(indices) #打乱
for each in range(0, length, batchsize): #取数,batchsize为步长
get_indices = indices[each:each + batchsize]#本次要取的下标
get_data = data[get_indices] #取data
get_label = label[get_indices] #取label
yield get_data, get_label #yield作用除了return,还有存档,下次访问直接从断点开始
batchsize = 16 #一次取16组数据,每16个数据算一笔loss
for batch_x, batch_y in data_provider(X, Y, batchsize): #X和Y为之前创建的数据
print(batch_x, batch_y)
break #停止这层循环
def fun(x, w, b): #定义函数,有了数据之后,我们需要定义一个预测函数,以求预测值
pred_y = torch.matmul(x, w) + b #预测函数
return pred_y
def maeloss(pred_y, y): #loss函数,预测值和真实值
loss = torch.sum(abs(pred_y - y)) / len(y) #abs取绝对值,torch.sum()求和,接着除以n(也就是len(y))
return loss
def sgd(paras, lr): #梯度下降,para为参数,lr为人定的学习率,
with torch.no_grad(): #接下来的计算 不计算梯度, 回传不计算梯度
for para in paras:
para -= para.grad * lr #更新para
para.grad.zero_() #更新后梯度归零
lr = 0.03 #神经网络训练,学习率
w_0 = torch.normal(0, 0.01, true_w.shape, requires_grad=True) #随机选取w0,计算梯度,更新w。 与true_w保持一致,需要计算梯度
b_0 = torch.tensor(0.01, requires_grad=True) #计算梯度
print(w_0, b_0)
epochs = 50 #超参数,如果一轮训练不完,可以训练多轮
for epoch in range(epochs): #循环训练
data_loss = 0
for batch_x, batch_y in data_provider(X, Y, batchsize): #取一笔数据
pred = fun(batch_x, w_0, b_0) #猜测的pred,得到一组预测值
loss = maeloss(pred, batch_y) #计算loss,pred为上面的预测函数,batch_y为之前取的真实值
loss.backward() #计算所有梯度
sgd([w_0, b_0], lr) #梯度回传,w_0和b_0在sgd里面直接更新
data_loss += loss #记录这轮的loss值
print("epoch %03d: loss %.6f" % (epoch, data_loss)) #epoch轮次,3位整数,loss
print("原来的函数值:", true_w, true_b)
print(w_0, b_0) #训练结束
idx = 3 #以下为画图
plt.plot(X[:, idx].detach().numpy(), X[:, idx].detach().numpy() * w_0[idx].detach().numpy() + b_0.detach().numpy(),
label="pred")
plt.scatter(X[:, idx], Y, 1)
plt.show()
总结
自勉:菜就多练,不会就多看















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









