






一、训练环境
Windows10下编译好的darknet
编译过程:https://blog.csdn.net/weixin_54603153/article/details/119980266?spm=1001.2014.3001.5501)
源码地址:https://github.com/AlexeyAB/darknet
二、制作自己的数据集
1.首先在darknet-master(我们下载好的源码)文件夹下创建放数据集的文件夹

Annotations放标签xml文件,
JPEGImages放照片,
Main什么都不放创就行了,一会脚本会自动给里面生成
labels不用创,一会脚本会自动生成
2.运行脚本make1把图片分为训练集,测试卷,验证集
import os
import random
trainval_percent = 1 #可以自己修改
train_percent = 0.9 #可以自己修改
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
txtsavepath = 'VOCdevkit/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('VOCdevkit/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
这时我们得到

3.把对于xml转化为txt格式,运行make2
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["yes_mask", "no_mask"] #改为自己数据集的label
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)): #注意路径
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()生成如下文件,生成labels和三个txt文件,labels里面装的就是把我们的标签文件xml转化为txt格式

以上我们就把数据集都制作好了
三、准备训练所需的文件和预训练权重
1.到源码网站下载预训练权重

下载好直接放在darknet-master文件夹里就行
2.创建及修改cfg文件
cfg为模型结构文件,位置在darknet-master/cfg里面,需要根据自己的数据、运行环境、训练方式进行修改。以yolov4-tiny.cfg为例,选择复制改为yolov4-tiny-new.cfg
修改yolov4-tiny-new.cfg的几个地方
这些参数都根据自己的需要去修改
[net]
batch=96 # 每次iteration训练的时候,输入的图片数量
subdivisions=48 # 将每一次的batch数量,分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration
width=512 # 大小为32的倍数
momentum=0.9 # 动量,影响梯度下降到最优的速度,一般默认0.9
decay=0.0005 # 权重衰减正则系数,防止过拟合
angle=0 # 旋转角度,生成更多训练样本
saturation=1.5 # 调整饱和度
exposure=1.5 # 调整曝光度
hue=.1 # 调整色调
learning_rate=0.001
burn_in=1000 # 学习率控制的参数,在迭代次数大于burn_in时,采用policy的更新方式:0.001 * pow(iterations/1000, 4)
max_batches=500200 # 最大迭代次数
policy=steps
steps=400000,450000 # 学习率变动步长,Steps和scales相互对应, 这两个参数设置学习率的变化, 根据batch_num调整学习率
scales=.1,.1 # 学习率变动因子,迭代到400000次时,学习率x0.1; 450000次迭代时,学习率又会在前一个学习率的基础上x0.1
接下载来修改所有yolo层的classes,以及yolo层前一个卷积层的filters(计算方式为filters=(classes + 5)x3)
我习惯的直接ctrl+f搜索classes,能搜索到两个,然后把classes修改为我们的类别数,然后再找到这个classes上面离得最近的filters改为(classes+5)*3,总共改两组

3.创建ok文件夹和names文件
我这里是方便管理,专门把我们训练所需要的文件放在了一起,文件夹如下:
ok创建在darknet-master文件下
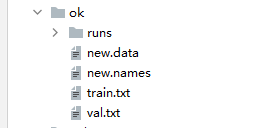
train.txt和val.txt是我在VOCdevkit/VOC2007里面复制过来的,这俩文件是我们创建数据集运行完make2的时候生成的,这里为了方便管理我就放在了ok下。
new.data内容如下:(这个new.data就相当于一个指挥部,放置我们训练时需要文件的路径)
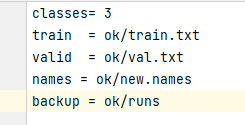
classes是类别,train写入我们放入ok文件夹的训练集地址,valid写入我们放入ok文件夹的验证集地址,names是我们创建的names文本地址,backup是放置训练结果的文件夹的地址
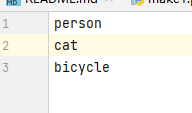
new.names内容是填写训练类别的:
四、训练
1.在darknet-master文件目录下打开cmd,输入

其中ok/new.data就是那个我们写入很多路径的指挥部的位置,
cfg/yolov4-tiny-new.cfg就是我们在前面修改的cfg文件的位置,
yolov4-tiny.conv.29是我们下载的预训练权重的位置 它是直接放在darknet-master源文件夹下的所以前面就不用写子文件中名字了
2.如果中间训练断了,我们继续训练
在darknet-master文件目录下打开cmd,输入
darknet.exe detector train ok/new.data cfg/yolov4-tiny-new.cfg ok/runs/yolov4-tiny-new_last.weights前面都和初次训练一样,只是最后把预训练权重换成了我们ok/runs里面最后一次训练得到的权重
以上就是训练过程















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









