







在自然语言处理任务中,首先要考虑词如何在计算机中表示。通常,有两种方式:one-hot representation 和 distribution representation。
一、离散表示 ont-hot representation
n个词就需要n维向量来表示。
1. 我 [1,0,0,0]
2. 爱 [0,1,0,0]
3. 北京 [0,0,1,0]
4. 天安门 [0,0,0,1]
两个问题:
- 向量的维数为词表的大小。
- 不能展示词与词之间的关系。
二、分布式表示distribution representation
distribution representation 表示将词表示成一个定长的连续的稠密向量。
优点:
- 词之间存在相似关系,是词之间存在“距离”概念。
- 词向量能够包含更多信息,并且每一维都有特定的含义。
word embedding 指的是将词转化为一种分布式表示,又称词向量。
三、如何生成词向量
可分为「基于统计」的方法和「基于语言模型」的方法。
3.1 基于统计方法
共现: 单词i出现在单词j的环境中。
共现矩阵:单词对共现次数的统计表。
共现矩阵为对称矩阵,统计频次是针对语料库中所有语句,具有全局特征。同时一定程度上能表达词之间的关系。
构建共现矩阵
现有语料: I like deep learning. I like NLP. I enjoy flying. 以窗半径为1来指定上下文环境。
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数作为当前word 的vector。
X[0,1]:表示 like 出现在 I 的环境中(I like或like i)的次数为2
X[0,2]:表示 enjoy 出现在 i的环境中(I enjoy 或 enjoy i) 的次数为1
X[1,3]:表示 deep 出现在 like 的环境中(like deep 或 deep like)的次数1
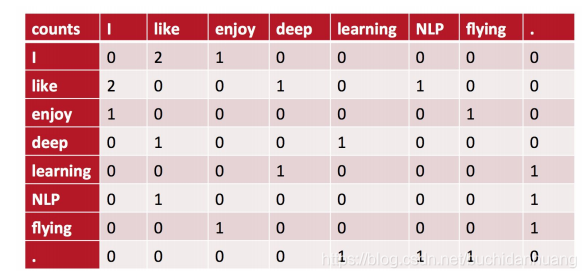
1. I [0, 2, 1, 0, 0, 0, 0, 0]
2. like [2, 0, 0, 1, 0, 1, 0, 0]
3. enjoy[1, 0, 0, 0, 0, 0, 1, 0]
4. deep [1, 0, 0, 0, 1, 0, 0, 0]
计算共现概率
设 X 为共现矩阵
X(i,j) 表示词 j 出现在中心词 i 环境中的次数。
Xi 表示任意词出现在中心词 i 环境中的次数。
Pij 表示词j出现在中心词i环境中的概率,这一概率称为词 i和词j 的「共现概率」。
 |  |
共现矩阵定义的词向量在一定程度上缓解了ont-hot representation方法词向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
奇异值分解SVD
对原始词向量进行降维。
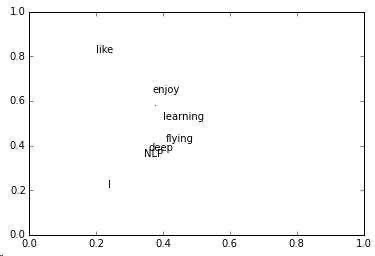
对上面共现矩阵进行SVD分解,得到矩阵正交矩阵U,再对U进行归一化得到矩阵如下:

语义相近的词在向量空间相近,甚至可以一定程度上反映word间的线性关系。
3.2 基于语言模型
语言模型生成词向量是通过训练神经网络语言模型NNLM,词向量作为语言模型的附带产出。
NNML背后的基本思想是对现在上下文环境里的词进行预测,这种对上下文环境的预测本质上也是一种对共现统计特征的学习。
比较著名的采用 neural network Language model生成词向量的方法有:Skip-gram,CBOW,LBL,NNLM,C&W,GloVe
3.3 word embedding
将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入。
king [0.99, 0.99, 0.05, 0.7]
Queen [0.99, 0.05, 0.93, 06]
Woman [0.02, 0.01, 0.999, 0.5]
Prince [0.98, 0.02, 094, 0.1]
下图是将一个3维词向量表示转为2维词向量表示。

在我们使用word embedding后,word之间会存在某些关系,比如: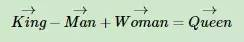
在向量空间中表示如下:
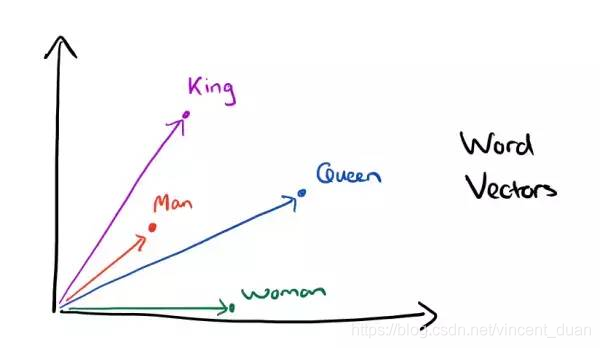
因为分布式表示的词向量包含着词的上下文信息。
上下文信息
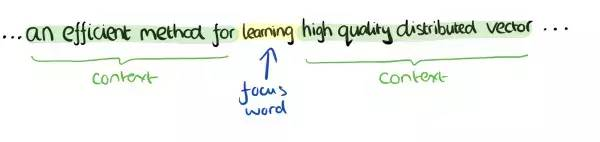
词learning上下文信息可以是其左右两边的content标记的内容。
近义词
拥有相似或相同上下文的多个词可能是近义词或同义词
CBOW就是通过当前中心词的上下文单词信息预测当前中心词。
 |  |
最左一列为当前词的上下文,且用 one-hot 编码,维度V-dim,即所有上下文词形成 X(C, V-dim)
输入层和隐含层之间:W(V-dim, N) , N 为自己定义的 X*W = H(C, N)
隐含层和输出层之间:W(N, Vdim), H(C,N)*W(N,V-dim) = O(C, V-dim)
在输出层经过Softmax归一化后:CVdim* 矩阵,每一列向量V-dim个位置中选择概率最大的数字对应的位置所表示的词为预测结果。
5. 降维度
CBOW中最终要的是输入层和隐含层的 W(V-dim,N) 矩阵。
首先,我们要将词转换为分布式表示的词嵌入,先对词进行one-hot编码,表示为每个词 V-dim维向量,与 W(V-dim,N) 相乘后就是选择W矩阵的第 i 行,即将词表示为N维向量(通常N远小于V,常用为300远小于词表不重复词个个数),即将长度为V-dim 的 ont-hot 编码稀疏 word vectors 转换为稠密的长度为N的 word embedding 表示。
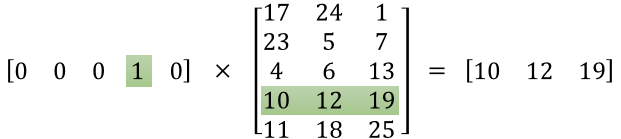
如果我们要查找某个词的word vector时,我们只需将它与*W(V-dim, N)*相乘即可。
四、词向量的训练
词向量效果的影响因素:
- 增加词向量的维度能够增加词向量的效果。
- 在同一领域语料下,语料越多越好,增加不相关语料会降低词向量的效果。
- 大的上下文窗口训练的词向量更多反映主题信息,而小的上下文窗口训练的词向量更多反映词的功能和上下文语义信息。
- 语料的纯度越高,词向量的效果越好。因此,在利用语料训练词向量时,对语料进行预处理能够提高词向量的效果。
词向量的歧义问题
例如,词”苹果“可以指代水果,也可以指代苹果手机。
在对“苹果”进行训练时,将会对其对应的词向量向两个方向拉伸,进而造成词向量的歧义。
词向量的歧义将会对词向量的应用效果产生影响。
例如,对苹果进行序列标注,指代手机的苹果对应打上品牌词标签,而指代水果的苹果打上产品词标签。
对同一个词打上多种不同的标签而采用同一个词向量,将降低词性标注的效果。
通常,解决这一问题的方法是对词向量进行聚类,以多个向量来表示同一个词。
五、总结
- 词向量比统计特征包含更多信息,但是并不知道包含了哪些信息(比如每维特征代表的意义)。
- 词向量的训练采用无监督方式,不能很好的利用先验信息,
- 词向量是神经网络语言模型的副产物,其损失函数不是由具体应用构建。因此,不是词向量训练的越好,应用效果越好。
预训练语言模型要从 word vector 说起。word vector利用文本数据,构造出词之间的共现关系,一般将在一句话中共现的词作为正样本,随机负采样构造负样本,采用CBOW或Skip-Gram的方式进行训练,以此达到让经常共现的词,能够具有相似向量化表示。其本质是NLP中的一个先验:频繁在文本中共现的两个词,往往语义是相近的。然而,词向量的问题也比较明显,同一个词在不同的语境中,含义往往是不同的,而词向量对于某一个词只能生成一个固定的向量,无法结合语境上下文信息进行调整。
一. 文本表示方法 (representation)
1. 词袋模型(BOW)
one-hot
tf-df
2. 主题模型
LDA
LSA
3. 基于词向量的静态表征
word2vec
fastText
glove
4. 基于词向量的动态表征
ELMo
GPT
BERT
4. 词向量函数
5. GloVe模型算法
1)从共现矩阵中随机采集一批非零词对作为一个mini-batch的训练数据;
2)随机初始化这些训练数据的word vector以及随机初始化两个偏置;
3)将word vector做内积和平移操作,并和 log(Xij) 计算损值失,计算梯度;
4)通过反向传播更新word vectors 和 偏置
5)不断进行迭代操作,直到结束。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









