







一、研究背景
存在问题:
大多数语义分割方法,如U-Net(基于cnn的)和SegFormer(基于transformer的),都是根据图像特征来解决分割任务。由于遥感图像的复杂性,它们经常面临以下挑战:
- 由于判别信息不足而导致不同类别之间的混淆;
- 忽略或缺乏细粒度信息。
多模态机器学习从多个数据模态中学习,可以为同一个场景提供互补的信息,从而增强场景的表示和理解。
主要贡献:
-
使用预训练的 CLIP Transformer 文本编码器作为文本编码器,以及在 SegFormer 中具有强大特征提取能力的 MiT 图像编码器作为图像编码器。提出了一种多模态多尺度特征融合解码器,用于整合多模态和多尺度信息。
-
用可学习的文本提示替换 CLIP 中的固定文本提示,这使得模型能够学习到更适合遥感图像语义分割任务的文本提示。
-
使用OHEM(online hard example mining)来关注困难样本,从而提高对这些样本的学习能力。从而缓解了样本不平衡的问题。
二、模型架构
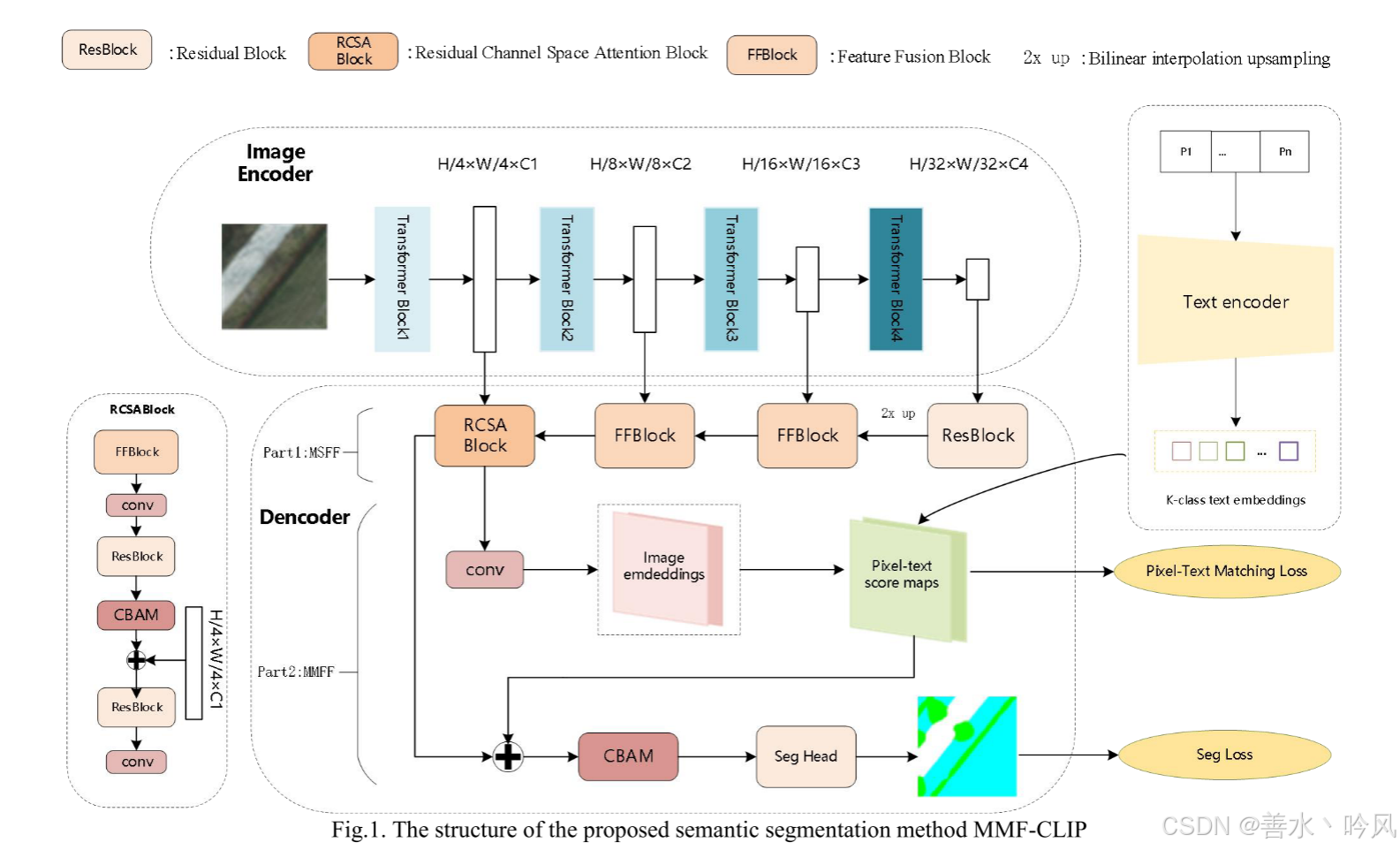
所提出的图像-文本多模态模型MMF-CLIP包括一个文本编码器、一个图像编码器和一个多模态多尺度特征融合解码器。模型的结构如图1所示。
图像编码器与SegFormer模型的编码部分相同,对应图1中的Image Encoder部分。考虑到模型的效率和复杂性,这里使用的是SegFormer中MiT系列中相对轻量级的MiT- b3编码器。图像编码器分别提取输入图像分辨率为1/4、1/8、1/16和1/32的四层特征图。
MiT-b3编码器:
1. 整体架构设计
MIT-B3的结构分为4个处理阶段(Stage 1~4),每个阶段包含多个Transformer块,具体配置如下:
| 阶段(Stage) | Transformer块数量 | 特征图分辨率(输入为H×W) | 嵌入维度(Channel) | 注意力头数(Heads) |
|---|---|---|---|---|
| Stage 1 | 3 | H/4 × W/4 | 64 | 1 |
| Stage 2 | 4 | H/8 × W/8 | 128 | 2 |
| Stage 3 | 18 | H/16 × W/16 | 320 | 5 |
| Stage 4 | 3 | H/32 × W/32 | 512 | 8 |
- 输入处理:输入图像首先通过一个重叠卷积(Overlap Patch Embedding)将图像分割为重叠的块(patch),降低分辨率并提取初始特征。
- 分阶段处理:每个阶段通过多个Transformer块处理特征图,并在阶段间通过下采样模块(含卷积和归一化层)进一步降低分辨率。
2. 核心组件解析
(1) Mix Transformer Block
每个Transformer块包含以下关键组件:
- 高效自注意力(Efficient Self-Attention):
- 通过序列缩减(Sequence Reduction)降低计算复杂度(例如将序列长度压缩到原来的1/4)。
- 采用多头注意力机制,不同阶段头数不同(如Stage 3用5头)。
- 混合前馈网络(Mix-FFN):
- 结合深度可分离卷积(DWConv)和全连接层,增强局部特征建模能力。
- 公式:输出=Conv3×3(GELU(Linear(x)))+Linear(x)
(2) 重叠块嵌入(Overlap Patch Embedding)
- 作用:将输入图像分割为重叠的块(避免非重叠块导致的边缘信息丢失)。
- 实现方式:使用步幅小于块尺寸的卷积(例如7×7卷积,步幅4,填充2)。
3. 输出特征图
MIT-B3输出4个不同分辨率的特征图,用于后续的语义分割解码器:
- Stage 1 → 1/4分辨率(保留细节,适合小目标分割)
- Stage 2 → 1/8分辨率(平衡细节与语义)
- Stage 3 → 1/16分辨率(高层语义特征)
- Stage 4 → 1/32分辨率(全局上下文信息)
2.1 文本编码器
与CLIP不同,文本提示被设计为可学习的参数。通过标注样本的损失进行学习,文本编码器提取对遥感图像分割有益的文本上下文信息,从而提供使用文本特征对目标任务建模的能力。文本编码器的输入是:
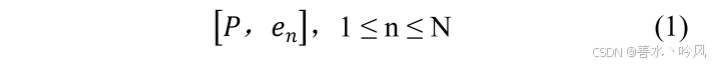 其中
其中 是可学习的文本上下文,而
是第 n 个类别的名称嵌入。N 表示类别的数量,n 表示第 n 个类别,C 表示向量的维度。文本编码器是一个具有 12 层的 Transformer 模型,包含 8 个注意力头。它拥有 6300 万参数,并通过 CLIP 的预训练结果进行初始化(文本编码器的参数继承自CLIP的文本编码器,保留CLIP在大量图文对上学到的语义对齐能力)。文本编码器将 N 维的输入潜在标签集嵌入到一个连续的向量空间中,提取文本特征,并输出 N 个向量。嵌入层、编码器的输入和输出的向量维度均为 512,即 C 是 512 维的。
2.2多模态多尺度特征融合解码器
第一部分MSFF:该部分的目的是将图像编码器输出的图像特征在四个不同的层次上进行融合,从而对多尺度信息进行对齐(同一模态空间对,齐宽高一致,上采样;不同模态语义对齐),提高特征的可分辨性。通过四个块逐步将高层语义信息特征图融合到低层特征图中,保留更多的原始输入信息。
MSFF中,第一个块(ResBlock)是一个残差模块,包含两层3x3卷积,中间归一化和ReLU层。它通过跳跃连接学习输入和输出之间的残差信息。
第二个和第三个块是特征融合块(FFBlock)。FFBlock由两个resblock并行实现,并有两个输入。第一个输入是ResBlock或之前的FFBlock的输出,第二个输入来自图像编码器中Transformer Block 2或3的输出。第二个输入首先通过1x1卷积将通道数调整为256,然后通过ResBlock进行处理。处理后的结果被添加到第一个输入,然后发送到ResBlock进行融合,然后进行双线性插值进行上采样。最后,利用1x1卷积层增加特征映射的非线性映射关系。
双线性插值:
第四个块是剩余通道空间注意块(RCSABlock),它包含两个resblock和一个CBAM块。CBAM是一种通道空间注意模块,旨在基于特征的空间上下文信息,在融合有偏差的细节信息特征时,动态增强对细节特征的感知。在第一部分中获得融合了多尺度信息的图像特征后,我们进入第二部分。
第二部分MMFF:本部分旨在对图像特征和文本特征进行对齐和融合,增强多模态特征的表示能力。首先,MMFF通过像素-文本分数图对齐多模态特征,并明确地将像素-文本分数图集成到图像特征中。然后,利用通道空间注意机制自适应调整多模态特征图的特征分布,从通道和空间两个维度增强多模态特征,挖掘模态间的互补信息。
即第二部分:MMFF。第一步是将融合多尺度信息的图像特征的通道大小调整到512维。使用内积计算文本特征与图像特征的每个像素点之间的相似度,从而得到高分辨率的像素文本评分图,其大小为原始图像的四分之一。定义为:
 其中,S 表示像素 - 文本分数图,z 表示卷积层输出的图像特征,t 表示文本特征。H 和 W 分别表示原始图像的长度和宽度,N 表示类别数量。在第二步中,将分数图和图像特征进行拼接,以获得多模态特征,将语言信息明确地融入图像特征中。接下来通过 CBAM 通道空间注意力机制调整多模态特征的分布,增强重要区域的响应,抑制不相关区域的响应,从而增强像素 - 文本分数图的有效引导。最后是一个简单的分割头(Seg Head)。分割头包括一个 1x1 卷积层,用于将特征的维度降低到类别数量,一个归一化层,一个 ReLU 层和一个 softmax 激活函数,用于预测每个像素的类别。
其中,S 表示像素 - 文本分数图,z 表示卷积层输出的图像特征,t 表示文本特征。H 和 W 分别表示原始图像的长度和宽度,N 表示类别数量。在第二步中,将分数图和图像特征进行拼接,以获得多模态特征,将语言信息明确地融入图像特征中。接下来通过 CBAM 通道空间注意力机制调整多模态特征的分布,增强重要区域的响应,抑制不相关区域的响应,从而增强像素 - 文本分数图的有效引导。最后是一个简单的分割头(Seg Head)。分割头包括一个 1x1 卷积层,用于将特征的维度降低到类别数量,一个归一化层,一个 ReLU 层和一个 softmax 激活函数,用于预测每个像素的类别。
2.3 损失函数
MMF-CLIP 的损失函数 包含两部分:分割损失
和像素 - 文本分数图损失
。
计算分割头的预测损失。当将像素 - 文本分数图视为一种分割结果时,我们可以增加一个辅助损失,即
。OHEM 交叉熵损失是一种在线筛选出具有更高损失值的hard examples以进行梯度更新的交叉熵损失。

在这里,S 表示像素 - 文本分数图,和
分别表示分割头的预测结果和真实标签。t=0.07 是温度系数。
hard examples作用
假设你在训练一个「车辆检测模型」:
- 简单样本:清晰的大卡车(模型轻松检测)。
- 难样本:
- 被树遮挡的自行车(模型漏检)。
- 远处的小汽车(模型误认为是行人)。
- 反光路面上的摩托车(模型完全忽略)。
难例挖掘的作用:
- 训练时,模型会优先关注这些「难样本」。
- 相当于告诉模型:「别总盯着简单的卡车看!多练练自行车和摩托车!」
- 最终模型在复杂场景下的检测能力大幅提升。
副作用和注意事项
-
走火入魔风险:
- 如果只练超难题目(比如极端模糊的图像),可能会忽略基础知识(简单样本)。
- 解决办法:控制难例比例(比如每10题里选2题难题)。
-
噪音干扰:
- 如果某道题答案标错了(标注错误),一直练反而学歪。
- 解决办法:结合其他方法(如Focal Loss)降低噪声影响。
MMF-CLIP中t的实际意义
在遥感图像分割任务中:
- 高
t值:- 模型更倾向于认为“建筑”和“道路”等相似类别的文本描述差异不大,可能导致分割边界模糊。
- 低
t值:- 模型严格区分“建筑”和“植被”的文本语义,分割边界更清晰,但可能对小目标(如汽车)过拟合。
实际中,t通常作为超参数通过实验调优(例如t=0.07是CLIP的默认值)。

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









