






作者 | 咖啡鱼
出品 | 焉知汽车
最近MCP和A2A两个协议在人工智能世界讨论热烈。前者是让AI智能体(也就是运行在服务器上的神经网络)有一个统一的标准化接口获取任何数据源;后者是让任何两个AI智能体都能用标准统一的协议交流(也就是互换数据)。
统一标准化这个思路是计算机世界的标配思路。说远的,任何操作系统都是对底层不同的硬件操作进行统一标准化,简化应用层的使用和开发;说近的,autosar标准就是在统一标准化思想下屏蔽车辆电控硬件细节,使得主机厂开发人员可以聚焦于应用功能的开发,不用关注底层细节。
一、MCP和A2A技术细节解释
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 开发的一个开放标准,用于规范应用程序如何为大型语言模型(LLMs)和人工智能助手提供上下文。它实现了模型与外部工具和数据系统之间安全的双向连接。
核心架构是采用客户端 - 服务器模型。MCP 主机是用户与 AI 交互的程序,如 Claude 桌面应用、智能 IDE 等;MCP 服务器是将 AI 指令转化为具体操作的程序,可将外部工具或数据源(如文件系统、开发工具等)通过 MCP 协议与 LLMs 安全连接;MCP 客户端是连接到 MCP 服务器的应用程序,例如基于 LLM 的聊天机器人。
作用是通过提供与外部数据源和工具集成的标准,方便在 LLMs 基础上构建智能体和工作流,使智能体在复杂的 AI 工作流中能够返回更智能、有上下文意识的响应。
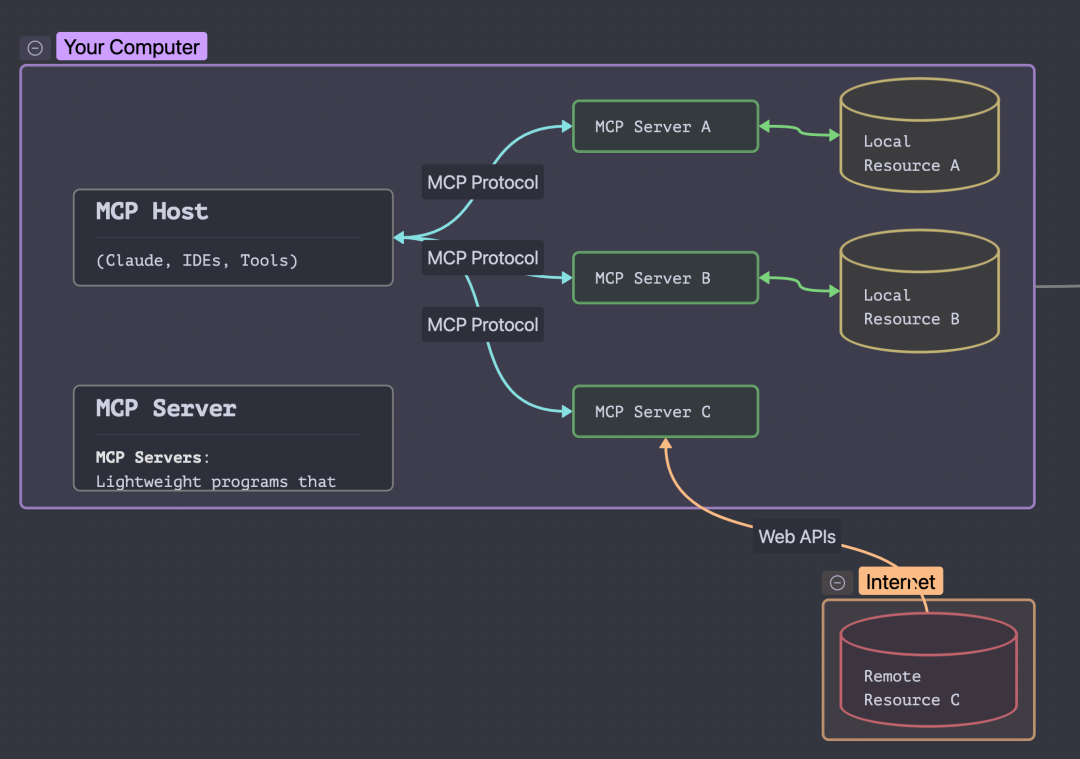
图 MCP架构,图片来自网络
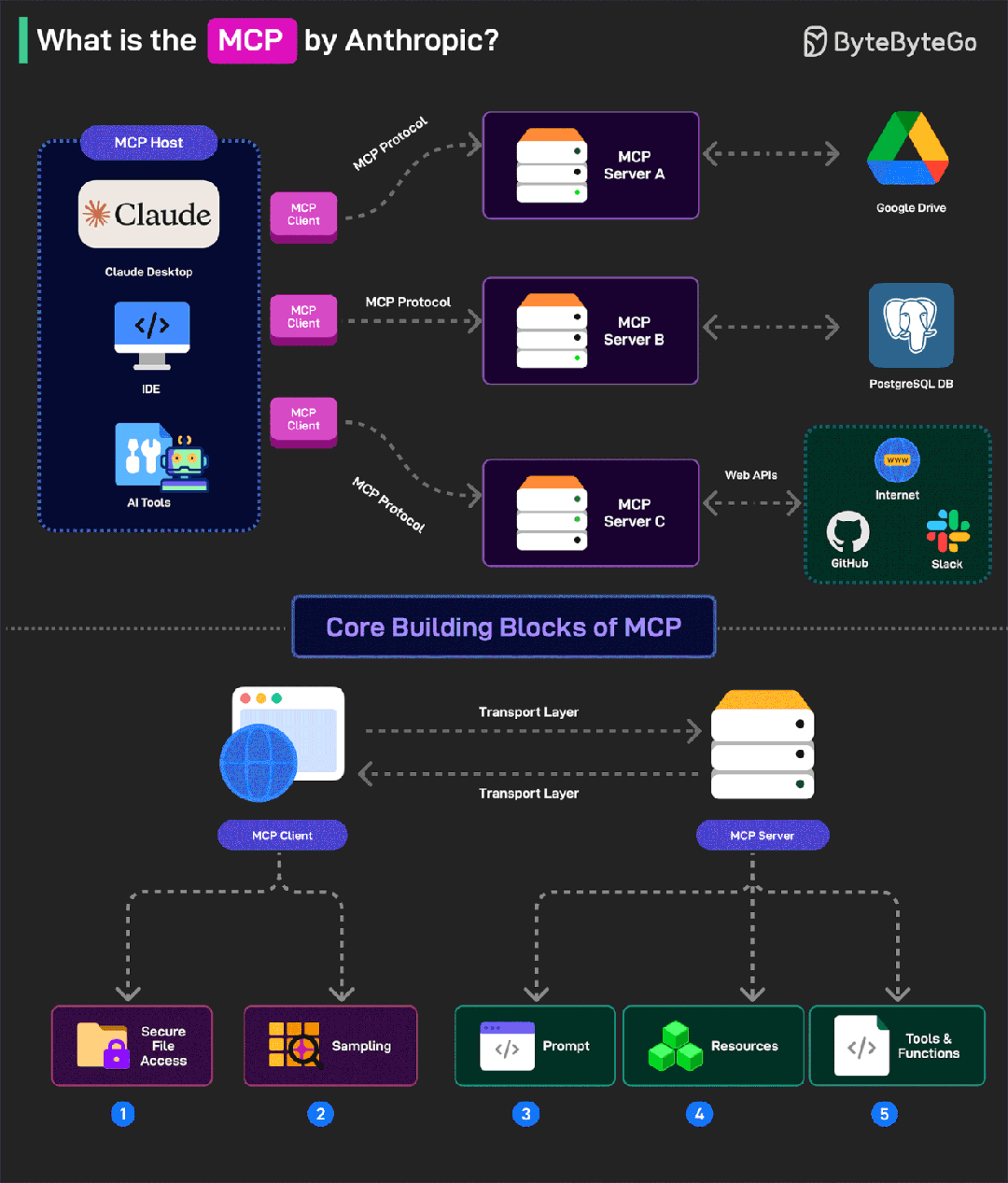
图 MCP协议工作流程图,图片来自网络
’A2A(Agent - to - Agent Protocol,智能体 - 智能体协议)是谷歌在 2025 年 4 月 9 日发布的一个新的开放协议,旨在实现 AI 智能体之间的标准化通信。
功能是使智能体能够直接相互通信,安全地交换信息,并在工具、服务和企业系统之间协调行动。
工作方式是智能体通过 HTTP 暴露公共卡片使自身可被发现,卡片包含主机 / DNS 信息、版本、智能体技能列表等。A2A 支持基于任务持续时间和交互性的多种客户端 - 服务器通信方法,如请求 / 响应轮询、服务器发送事件(SSE)、推送通知等。

图 A2A协议基本概念,图片来自网络
所谓公共卡片(agent card)看起来像一个新概念,实际只是智能体的身份认证信息+自我描述,比如“我是一个文生图的大模型”。
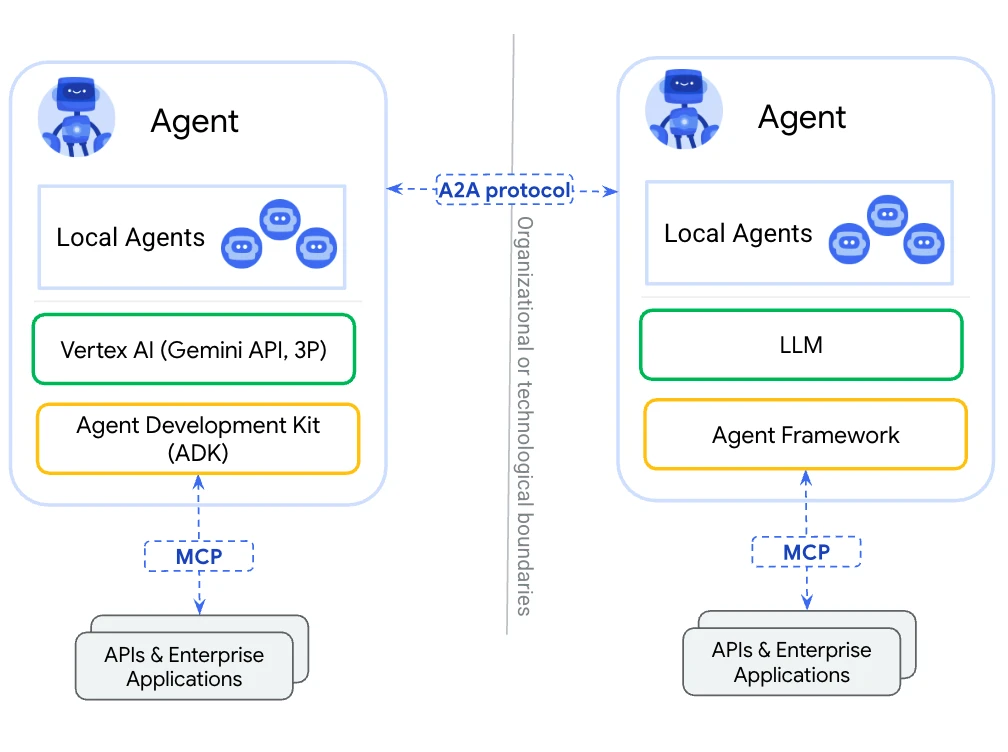
图
两个智能体Agent通过A2A协议交互,图片来自网络上图中一个细节值得注意,MCP协议并没有参与智能体之间的交互,而是仅仅服务于单个智能体,帮单个智能体获取各种数据源的数据。
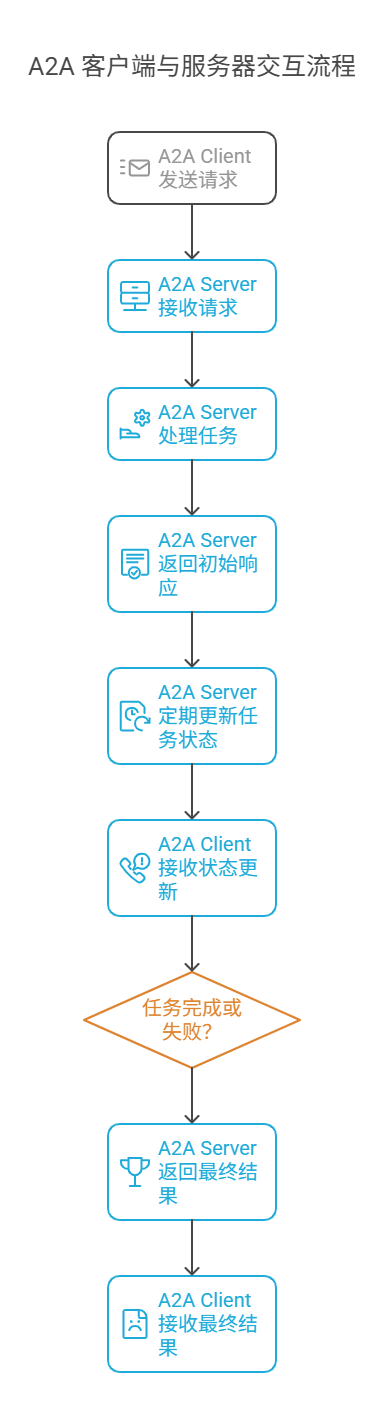
图 A2A协议的运行流程
图中流程的描述如下:
AI智能体一般都部署在Client客户端中,Server主要是个协调和转发的角色,但是不排除Server里面也部署智能体用于协调和转发工作。
1.请求发送:A2A Client 向 A2A Server 发送请求,启动一个任务。这个请求包含了任务的详细信息和所需的操作。
2.请求处理:A2A Server 接收到请求后,开始处理任务,并返回一个初始响应,告知任务的当前状态。
3.状态更新:任务在执行过程中会经历多个状态变化。A2A Server 会定期更新任务状态,并将这些状态信息反馈给 A2A Client。
4.任务完成或失败:任务最终会完成或失败。A2A Server 会将最终结果返回给 A2A Client,告知任务的执行结果。
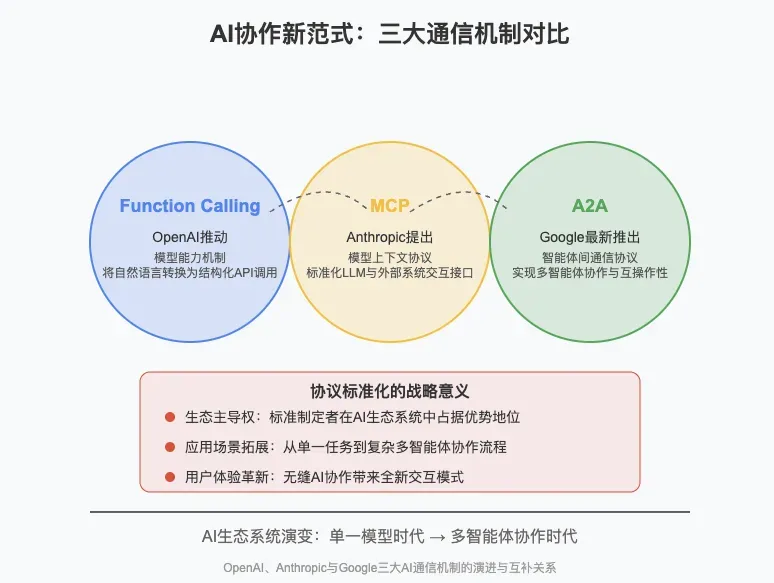
二、AI协作的三个范式---函数调用,MCP,A2A
业界一般认为,AI智能体获取数据和相互交互,最先是函数调用。
在函数调用背景下,获取每一种数据源都要单独编程,开发和维护成本很高;因此出现AI智能体的MCP协议,使得对于不同的数据源(SQL,csv,excel,应用API接口等等),只需要几乎一样的编程代码,而不用考虑数据源的访问细节。
类似的,在函数调用的背景下,一个智能体访问另外一个智能体,不仅仅知道对方特别的API及其语法,甚至还需要知道对方运行所在的服务器的操作系统类型和版本,才能有针对性的编程访问对方。甚至所用的编程语言都是受限制的。
图
AI协作范式的三步走,图片来自网络2.1 MCP实例:
比如用MCP访问不同数据源,我们首先安装SDK
pip install mcp-client # 官方SDK
from mcp_client import MCPClient
# 初始化客户端(只需配置一次)
client = MCPClient(
servers={
"sql": "postgresql://user:pass@localhost:5432/db",
"api": "https://api.example.com/v1",
"file": "/data/files" # CSV/Excel目录
}
)
# 统一查询方法
def query_data(source_type, query):
return client.execute(
source=source_type, # 标识数据源类型
query=query, # 统一查询语法
params={} # 可选参数
)
#查询SQL数据库
# 无需编写SQL驱动代码
result = query_data(
source_type="sql",
query={
"operation": "select",
"table": "users",
"conditions": {"age": {"$gt": 18}}
}
)
print(result) # 自动返回Pandas DataFrame
#读取CSV/Excel文件
# 自动识别文件格式
result = query_data(
source_type="file",
query={
"path": "sales.csv",
"format": "auto", # 自动检测
"filter": {"region": "Asia"}
}
)
#调用REST API
# 无需处理HTTP请求
result = query_data(
source_type="api",
query={
"endpoint": "/users",
"method": "GET",
"headers": {"Authorization": "Bearer xxx"}
}
)
# 跨数据源联合查询
# 同时查询SQL和API并合并结果
combined = client.execute_batch([
{"source": "sql", "query": {"table": "products"}},
{"source": "api", "query": {"endpoint": "/inventory"}}
])
可以看出:
1、用MCP访问各种数据源代码量小得多
2、其实MCP就是个跨源获取数据的统一工具,可以给AI智能体使用,也可以用于一般的数据处理场景。MCP并没有和AI智能体绑死。
MCP代码量对比如下:
| 操作 | 传统代码行数 | MCP代码行数 | 维护点数量 |
| SQL查询 | 15-20 | 3-5 | 5→1 |
| API调用 | 10-15 | 3-5 | 4→1 |
| 新增数据源类型 | 需新写模块 | 仅配置 | N→0 |
数据来源:MCP官方基准测试报告
2.2 A2A协议实例:
我们先给出不用A2A的传统方式示例,以供对比用:
# 智能体A代码(调用方)
import requests
import json
class TextAgent:
def request_image(self, prompt):
# 1. 硬编码通信细节
url = "http://agent-b.example.com/generate"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer xyz"
}
payload = {"prompt": prompt}
# 2. 手动处理HTTP通信
try:
response = requests.post(url, headers=headers, data=json.dumps(payload))
response.raise_for_status()
return response.json()["image_url"]
except Exception as e:
# 3. 自定义错误处理
print(f"调用失败: {e}")
return None
# 使用示例
agent_a = TextAgent()
image_url = agent_a.request_image("画一只坐在沙发上的猫")
下面A2A协议交互方式,核心优势是通过标准化协议自动处理通信、身份验证和任务编排。其实一眼可见,代码比上面短多了。
Python代码
# 智能体A代码(A2A版本)
from a2a_sdk import AgentClient
class TextAgent:
def __init__(self):
# 1. 初始化A2A客户端(配置一次)
self.client = AgentClient(
discovery_server="a2a://discovery.example.com"
)
def request_image(self, prompt):
# 2. 声明式调用(无需关心通信细节)
response = self.client.execute(
target_agent="image-generator", # 通过名称发现服务
action="generate",
params={"prompt": prompt},
timeout=10 # 统一超时设置
)
return response.data["image_url"]
# 使用示例
agent_a = TextAgent()
image_url = agent_a.request_image("画一只坐在沙发上的猫")
代码量对比统计
| 功能模块 | 传统方式代码行数 | A2A方式代码行数 | 减少比例 |
| 通信初始化 | 15-20 | 3-5 | 75%↓ |
| 单次调用逻辑 | 10-15 | 3-5 | 70%↓ |
| 错误处理 | 8-12 | 0(SDK内置) | 100%↓ |
| 新增智能体调用 | 需新写模块 | 仅改参数 | 90%↓ |
数据来源:Google A2A官方基准测试
CopyA2A协议简化点如下:
服务发现:通过名称自动定位智能体B(无需维护URL)
协议内建:自动处理消息编码/加密/重试
统一错误:SDK内置标准错误类型(如AgentUnavailableError)
能力协商:自动匹配参数格式(如智能体B的输入规范)
所以用A2A来沟通不同AI智能体,开发和维护工作量小多了。
本节最后,需要说明的是,MCP和A2A协议并无魔法,实际只是把每种可能遇到的复杂底层编码封装起来,供用户调用而已。这一点和autosar CP的做法和思路如出一辙。
如果非要说不同,那就是MCP和A2A协议不会对一种新的数据源出售专门的软件包并收费,而autosar CP会正对每一种底层芯片制定专门的软件包并出售,要适配新的MCU芯片就必须买CP的特定软件包。
三、总结----自然而然的问题--MCP和A2A能否统一
抛开技术细节的障眼法,自然而然有一个问题。
既然MCP是让AI智能体统一接口访问任何数据源,而其他智能体其实也是数据源。那就让MCP把AI智能体当成一种特别的数据源好了,只不过是交互式的数据源而已。
那么直接通过MCP直接沟通各个AI智能体好了。所谓沟通无非是各个智能体交换数据或者指令(指令也是一种数据)。
一套协议能搞定的事情,为什么要搞两套协议?这样会浪费程序员宝贵的时间和精力。这种浪费包括学习成本和开发维护成本两方面。
目前来看,MCP和A2A这两个协议从编码角度讲,不能直接代替彼此或者融为一体,因为调用的基本库就不一样。如果绕开基本库去底层实现融合,那等于又变成了函数调用方式来逐一处理每一种特殊情况,得不偿失。
但从长远看,MCP和A2A这两个协议必然会融合成一个,原理很简单,无非是把智能体当做一种特殊的数据源来处理就好了。而且二者都是Server-Client架构,不存在结构不同的问题,合一后部署软件也更简单。
为什么笔者会如此肯定 MCP和A2A必然合一,或者说至少会出现一种合一的产品实例呢?
一个故事很有启发性。一个小男孩刚学算术,问他父亲,一位职业数学家:爸爸,什么是数学?
他父亲回答:数学就是,对任何一个结论,你能用三行证明,就绝对不要用五行。
确实如此,很多构成我们技术基础的定理定律结论和算法,最初版本都是笨拙冗长的。经过发明人自己或者后人不断迭代改进而越来越简短,越来越清晰,越来越逼近本质。改进必然意味着简化和清晰化,如果越搞越复杂,越搞思维成本越大越累,那就不是改进了。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









