






 本文介绍了基于推理的神经网络技术在自然语言处理中的应用,特别是word2vec中的CBOW和skip-gram模型。CBOW模型通过上下文预测目标词,而skip-gram则是反之。文中还讨论了神经网络的学习过程,包括权重更新和数据预处理,以及与基于计数方法的对比。
本文介绍了基于推理的神经网络技术在自然语言处理中的应用,特别是word2vec中的CBOW和skip-gram模型。CBOW模型通过上下文预测目标词,而skip-gram则是反之。文中还讨论了神经网络的学习过程,包括权重更新和数据预处理,以及与基于计数方法的对比。
与上章不同的是,本章介绍的方法是基于推理的方法,使用到神经网络。
1 基于推理的方法和神经网络
基于计数方法存在问题:在现实中,语料库量巨大,使用SVD来执行不现实。
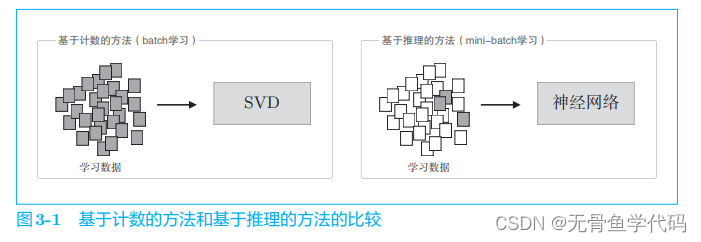
结论:基于计数方法要一次性处理全部数据;基于推理方法使用部分数据逐步学习。神经网络学习空余使用多台机器,多个GPU并行执行,加速学习过程。
推理 即 预测

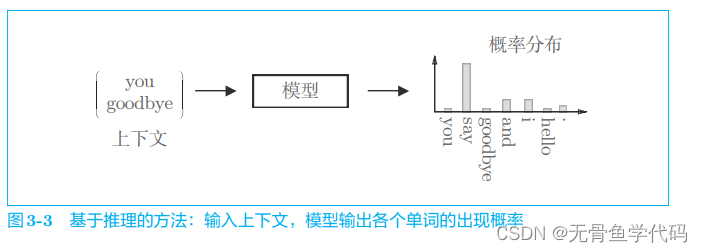
模型就是训练好的,训练时需要提供正确答案。类似于背课文,考你完形填空。
1.1 神经网络中处理单词方法
one-hot表示法:将单词转化为固定长度向量。

这样,神经网络输入层神经元个数就可以固定下来
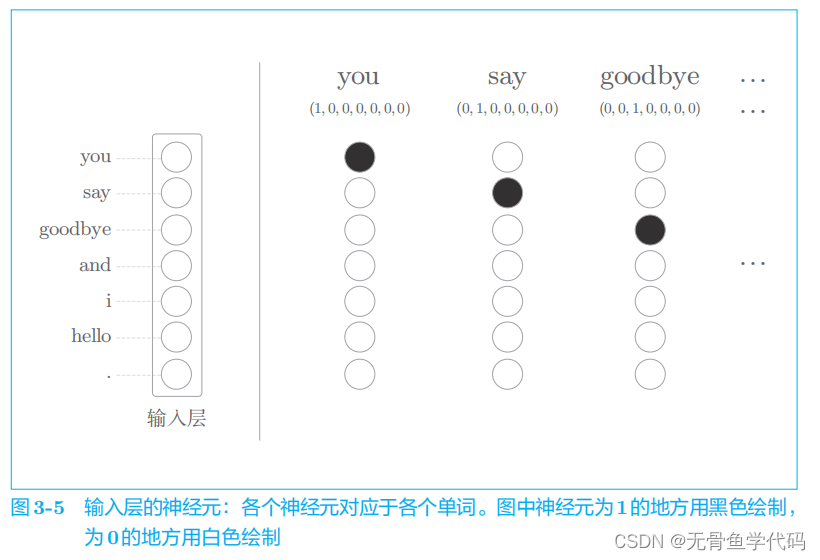
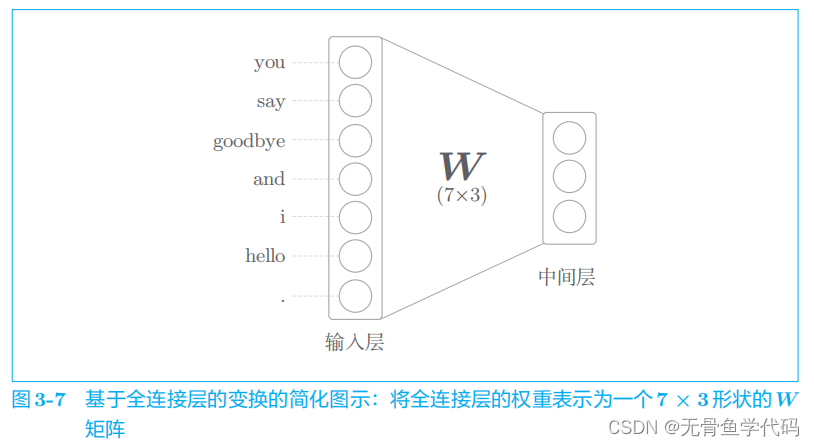
7个单词对应7个神经元。
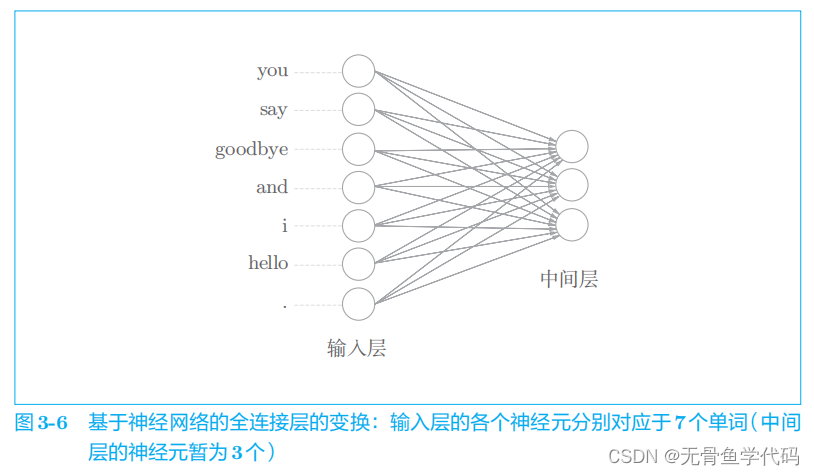
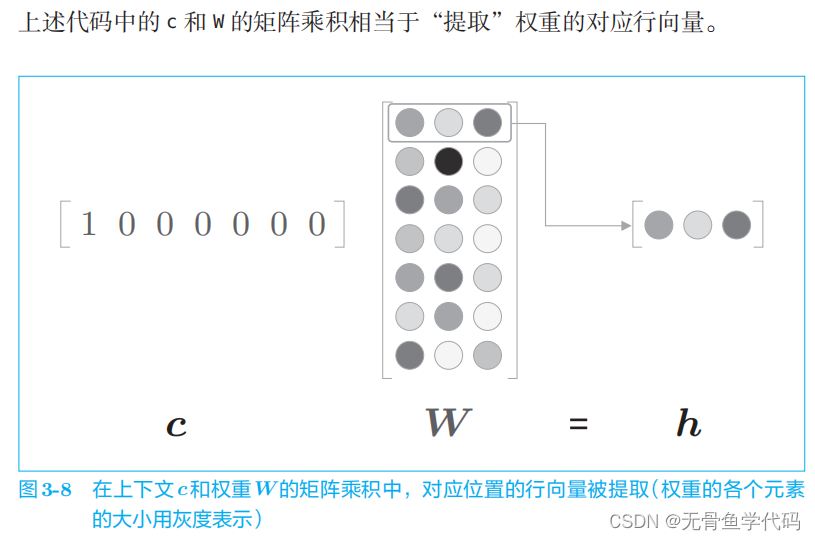
全连接层通过箭头连接所有节点。这些箭头拥有权重(参数),它们和输入层神经元的加权和成为中间层的神经元。另外,本章使用的全连接层将省略偏置。没有偏置的全连接层相当于在计算矩阵乘积。

2 简单的word2vec
2.1 CBOW模型的推理
CBOW
模型是根据上下文预测目标词的神经网络(“目标词”是指中间的单词,它周围的单词是“上下文”)。
这个上下文用
['you', 'goodbye']
这样的单词列表表示。我们将其转换为 one-hot
表示,以便
CBOW
模型可以进行处理。
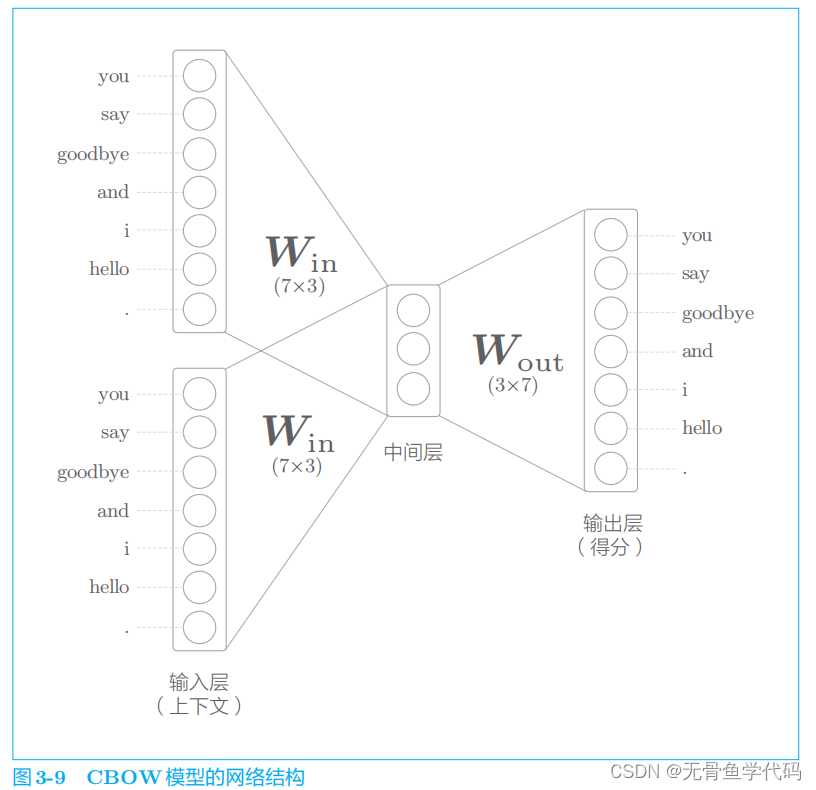
这里,因为我们对上下文仅考虑两个单词,所以输入层有两个。如果对上下文考虑 N
个单词,则输入层会有
N
个。
中间层的神经元是各个输入层经全连接层变换后得到的值的“平均”,1/2
(
h
1
+
h
2
)
。
输出层的神经元是各个单词的得分,它的值越大,说明对应单词的出现概率就越高。
中间层的神经元数量比输入层少这一点很重要。中间层需要将预测单词所需的信息压缩保存,从而产生密集的向量表示。
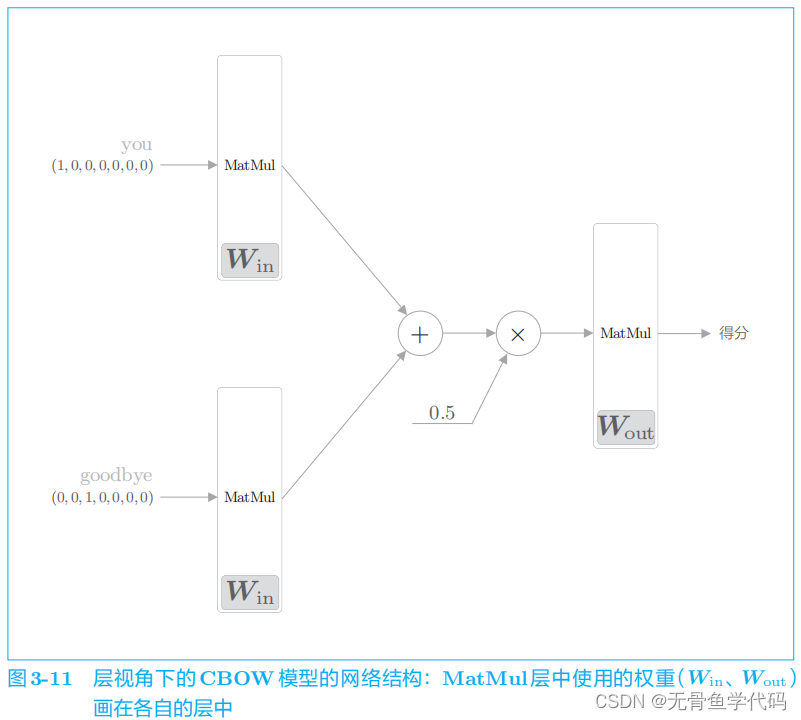
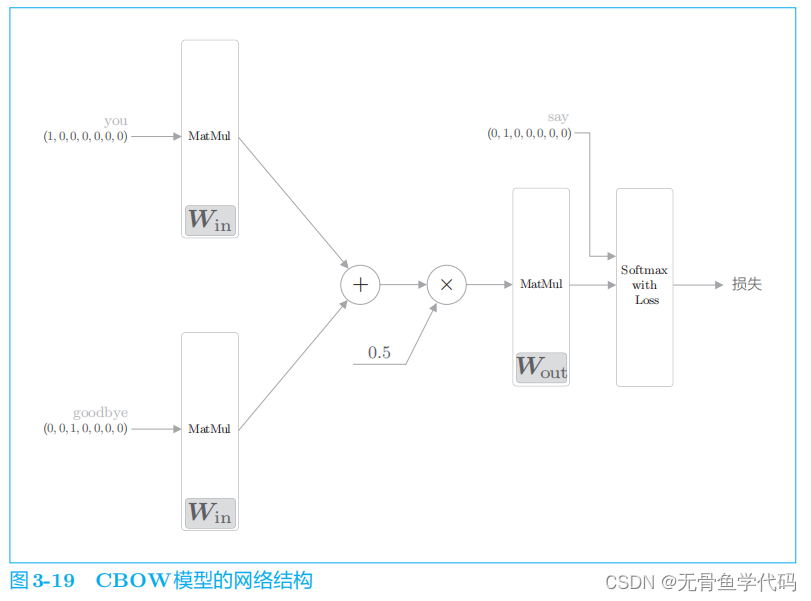
CBOW
模型一开始有两个
MatMul
层,这两个层的输出被加在一起。然后,对这个相加后得到的值乘以 0
.
5
求平均,可以得到中间层的神经元。最后,将另一个 MatMul
层应用于中间层的神经元,输出得分。

注意:
多个输入层共享权重
2.2 CBOW模型的学习
我们介绍的
CBOW
模型在输出层输出了各个单词的得分。通过对这些得分应用 Softmax
函数,可以获得概率(图
3
-
12
)。这个概率表示哪个单词会出现在给定的上下文(周围单词)中间。
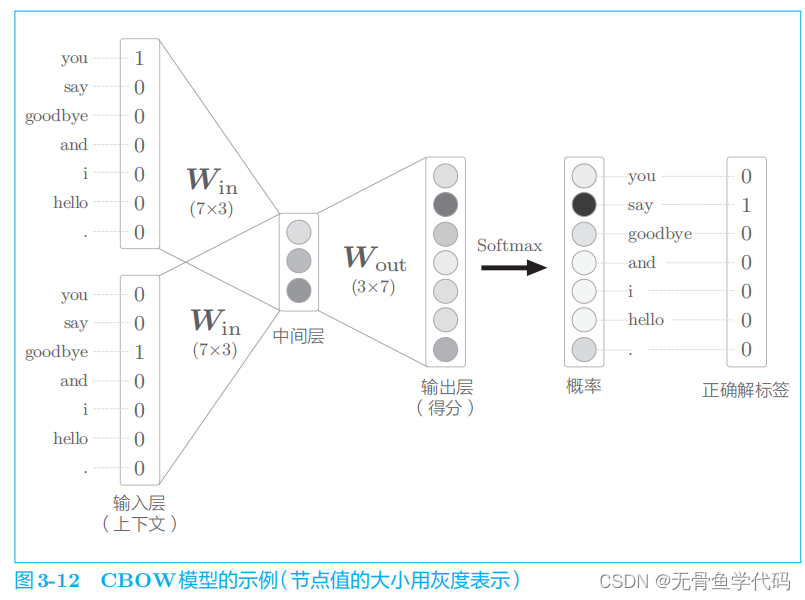
如果网络具有“良好的权重”,那么在表示概率的神经元中,对应正确解的神经元的得分应该更高。
CBOW
模型的学习就是调整权重,以使预测准确。
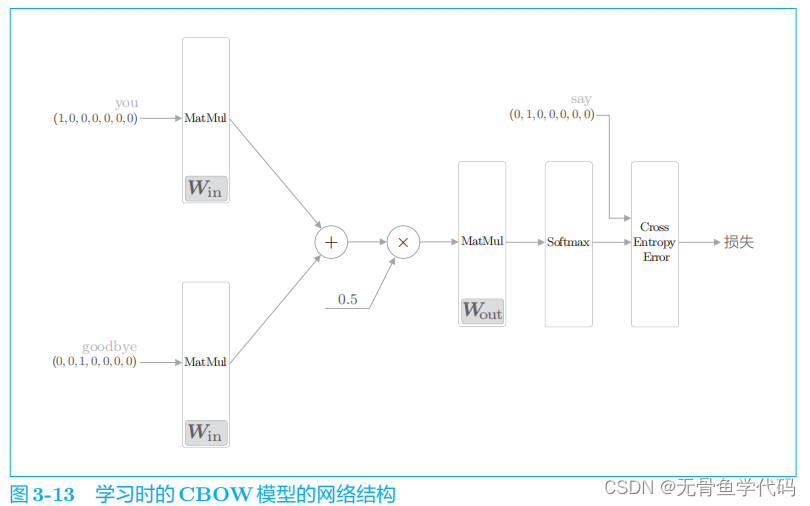
使用
Softmax
函数将得分转化为概率,再求这些概率和监督标签之间的交叉熵误差,并将其作为损失进行学习。
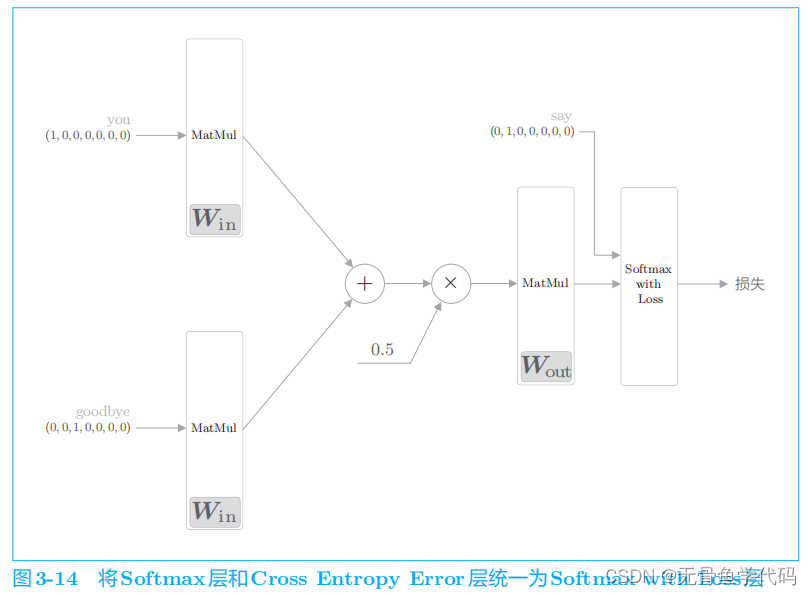
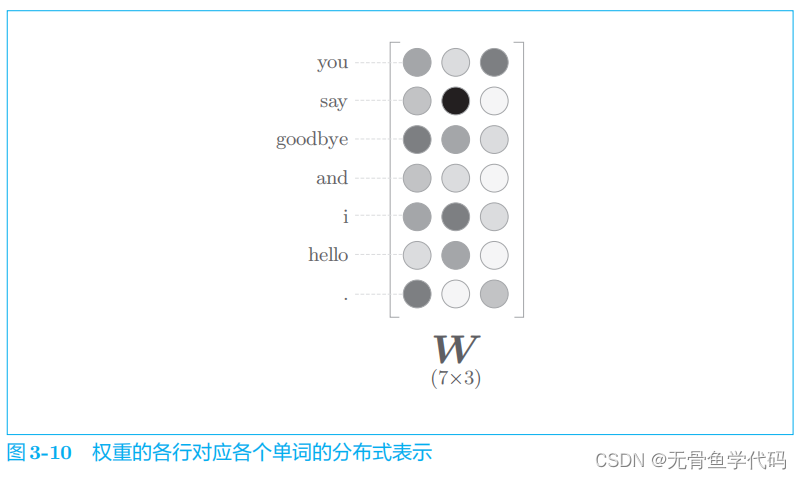
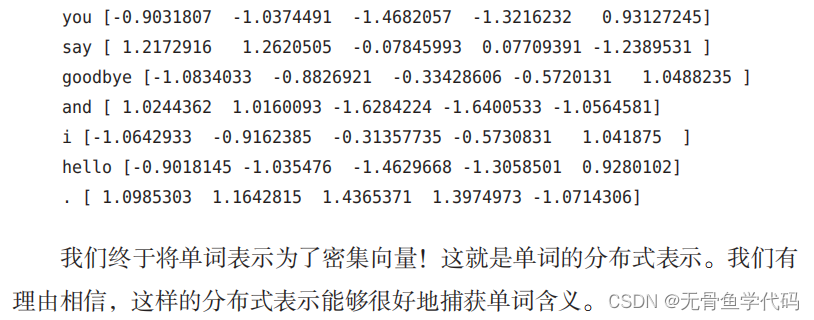
2.3 word2vec的权重和分布式表示
word2vec
中使用的网络有两个权重,分别是输入侧的全连接层的权重(W
in
)和输出侧的全连接层的权重(
W
out
)。
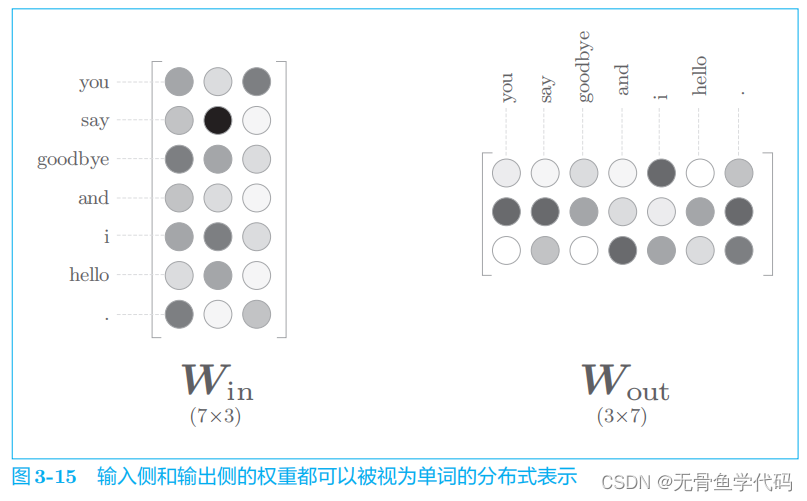
仅使用输入侧的权重
W
in
作为最终的单词的分布式表示
3 学习数据准备
“
You say goodbye and I say hello.
”
3.1 上下文和目标词

将语料库的文本转化成单词
ID

从单词
ID
列表
corpus
生成
contexts
和
target



这样就从语料库生成了上下文和目标词,后面只需将它们赋给
CBOW模型即可。不过,因为这些上下文和目标词的元素还是单词 ID
,所以还需要将它们转化为 one-hot
表示。
3.2 转化为one-hot表示

到目前为止的数据预处理总结一下:


4 CBOW模型的实现
SimpleCBOW
类的初始化方法


最后,我们实现反向传播
backward()
。
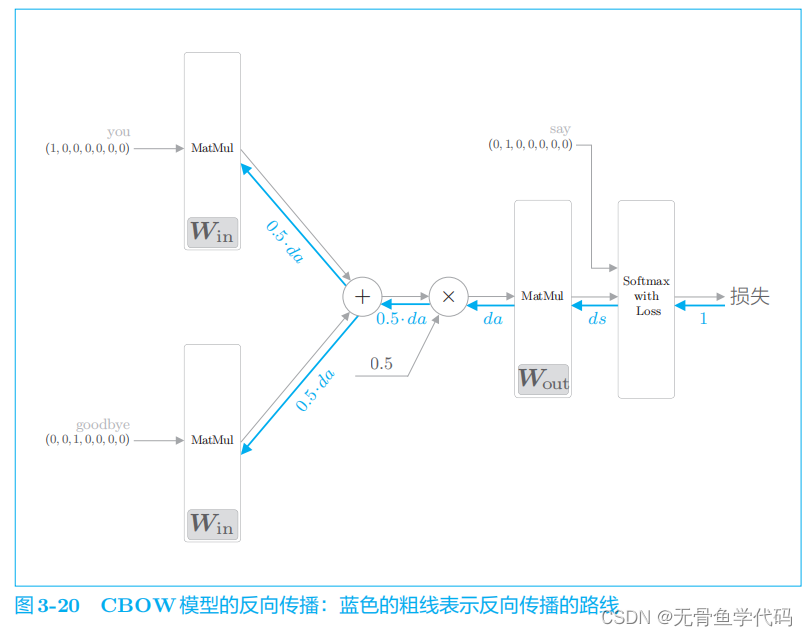

因此,通过先调用
forward()
函数,再调用 backward()
函数,
grads
列表中的梯度被更新。
CBOW
模型的学习,首先,给神经网络准备好学习数据。然后,求梯度,并逐步更新权重参数。
调用
Trainer
类来执行学习过程
5 word2vec的补充说明
5.1 概率


5.2 skip-gram模型
skip-gram
是反转了
CBOW
模型处理的上下文和目标词的模型。

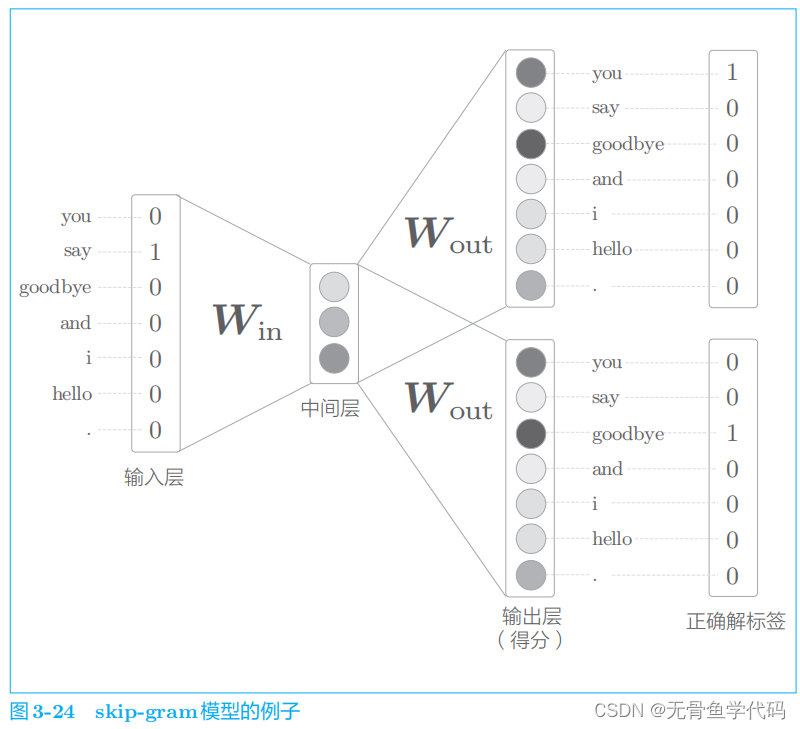
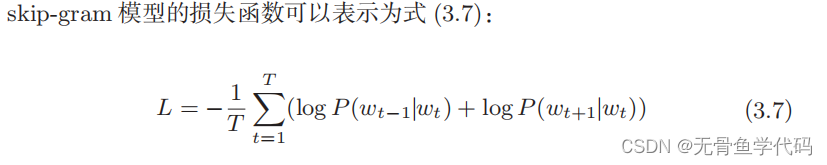
从单词的分布式表示的准确度来看,在大多数情况下,skip-grm
模型的结果更好。
就学习速度而言,CBOW 模型比
skip-gram
模型要快。

5.3 基于计数和基于推理
基于计数的方法通过对整个语料库的统计数据进行一次学习来获得单词的分布式表示,而基于推
理的方法则反复观察语料库的一部分数据进行学习(
mini-batch
学习)。
添加新词并更新单词的分布式表示,基于推理比基于计数优秀。
基于推理可实现复杂类推操作。
但有研究表明,就单词相似性的定量评价而言,基于推理的方法和基于计数的方法难分上下。















 2137
2137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









