






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
·文本的输入处理中,transformer会将输入文本序列的每个词转化为一个词向量,我们通常会选择一个合适的长度作为输入文本序列的最大长度如果一个句子达不到这个长度就用0填充,超出就做截断。
·self- attention机制可以让模型不仅仅关注当前位置的词,还关注句子中其他位置相关的词。
·transformer解码器预测了组概率,就可以将这组概率与正确的概率做对比,然后用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
目标的概率分布:
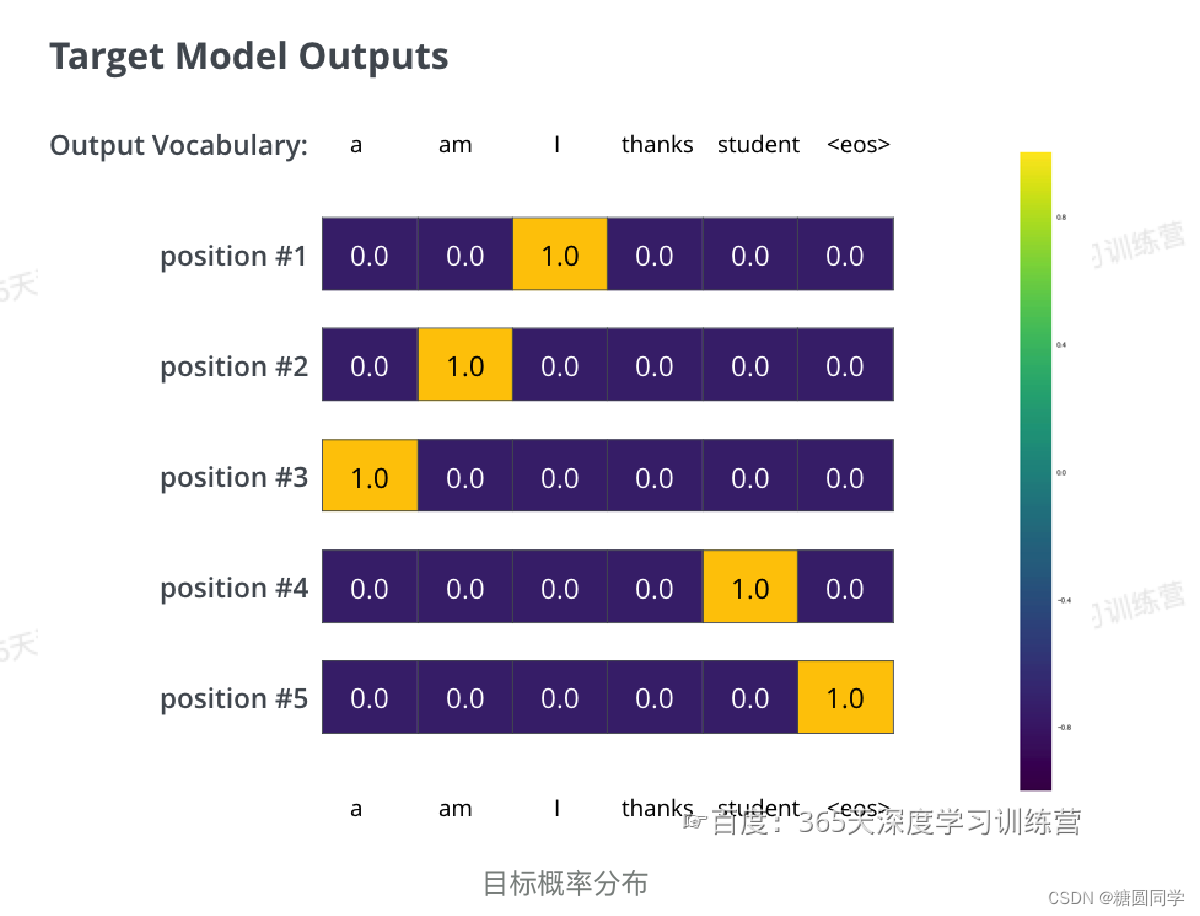
经过长期的训练后,希望输出的概率分布如下图所示:
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









