






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:[Pytorch实战 | 第J2周:Resnet-50V2
- 🍖 原作者:K同学啊|接辅导、项目定制
🏡 我的环境:
● 语言环境:Python 3.8
● 编译器:Pycharm
● 深度学习环境:Pytorch
一、 前期准备
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. 导入数据
本地数据集位于./data/bird_photos/目录下
import os,PIL,random,pathlib
data_dir = './data/bird_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]

f = []
for root, dirs, files in os.walk(data_dir):
for name in files:
f.append(os.path.join(root, name))
print("图片总数:",len(f))

train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder("./data/7-data/",transform=train_transforms)
total_data.class_to_idx

3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break

4. 显示图片信息
#%%
import matplotlib.pyplot as plt
# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(80, 20))
for i, imgs in enumerate(X[:20]):
# 维度缩减X
npimg = imgs.numpy().transpose((1, 2, 0))
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')

二、手动搭建Resnet-50V2模型
1.模型

2.代码
#%%
''' Residual Block '''
class Block2(nn.Module):
def __init__(self, in_channel, filters, kernel_size=3, stride=1, conv_shortcut=False):
super(Block2, self).__init__()
self.preact = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True)
)
self.shortcut = conv_shortcut
if self.shortcut:
self.short = nn.Conv2d(in_channel, 4*filters, 1, stride=stride, padding=0, bias=False)
elif stride>1:
self.short = nn.MaxPool2d(kernel_size=1, stride=stride, padding=0)
else:
self.short = nn.Identity()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, filters, 1, stride=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv3 = nn.Conv2d(filters, 4*filters, 1, stride=1, bias=False)
def forward(self, x):
x1 = self.preact(x)
if self.shortcut:
x2 = self.short(x1)
else:
x2 = self.short(x)
x1 = self.conv1(x1)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x = x1 + x2
return x
class Stack2(nn.Module):
def __init__(self, in_channel, filters, blocks, stride=2):
super(Stack2, self).__init__()
self.conv = nn.Sequential()
self.conv.add_module(str(0), Block2(in_channel, filters, conv_shortcut=True))
for i in range(1, blocks-1):
self.conv.add_module(str(i), Block2(4*filters, filters))
self.conv.add_module(str(blocks-1), Block2(4*filters, filters, stride=stride))
def forward(self, x):
x = self.conv(x)
return x
''' 构建ResNet50V2 '''
class ResNet50V2(nn.Module):
def __init__(self,
include_top=True, # 是否包含位于网络顶部的全链接层
preact=True, # 是否使用预激活
use_bias=True, # 是否对卷积层使用偏置
input_shape=[224, 224, 3],
classes=1000,
pooling=None): # 用于分类图像的可选类数
super(ResNet50V2, self).__init__()
self.conv1 = nn.Sequential()
self.conv1.add_module('conv', nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=use_bias, padding_mode='zeros'))
if not preact:
self.conv1.add_module('bn', nn.BatchNorm2d(64))
self.conv1.add_module('relu', nn.ReLU())
self.conv1.add_module('max_pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = Stack2(64, 64, 3)
self.conv3 = Stack2(256, 128, 4)
self.conv4 = Stack2(512, 256, 6)
self.conv5 = Stack2(1024, 512, 3, stride=1)
self.post = nn.Sequential()
if preact:
self.post.add_module('bn', nn.BatchNorm2d(2048))
self.post.add_module('relu', nn.ReLU())
if include_top:
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
self.post.add_module('flatten', nn.Flatten())
self.post.add_module('fc', nn.Linear(2048, classes))
else:
if pooling=='avg':
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
elif pooling=='max':
self.post.add_module('max_pool', nn.AdaptiveMaxPool2d((1, 1)))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.post(x)
return x
model = ResNet50V2().to(device)
''' 显示网络结构 '''
3. 统计模型参数量以及其他指标
import torchsummary as summary
summary.summary(model, (3, 224, 224))

三、训练模型
1. 编写训练和测试函数
见之前文章
## 2.正式训练
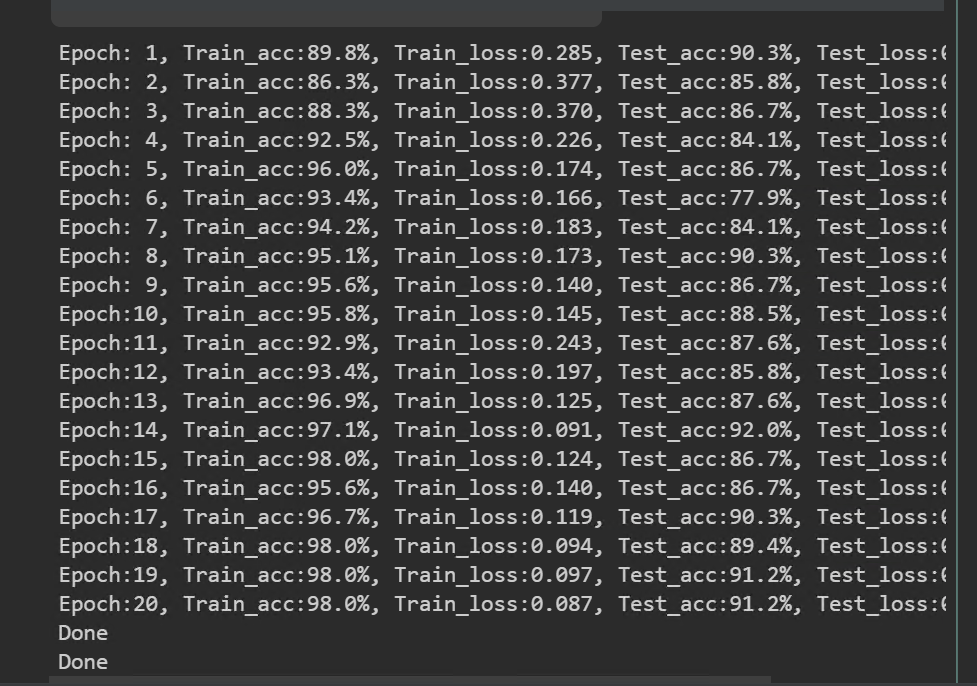
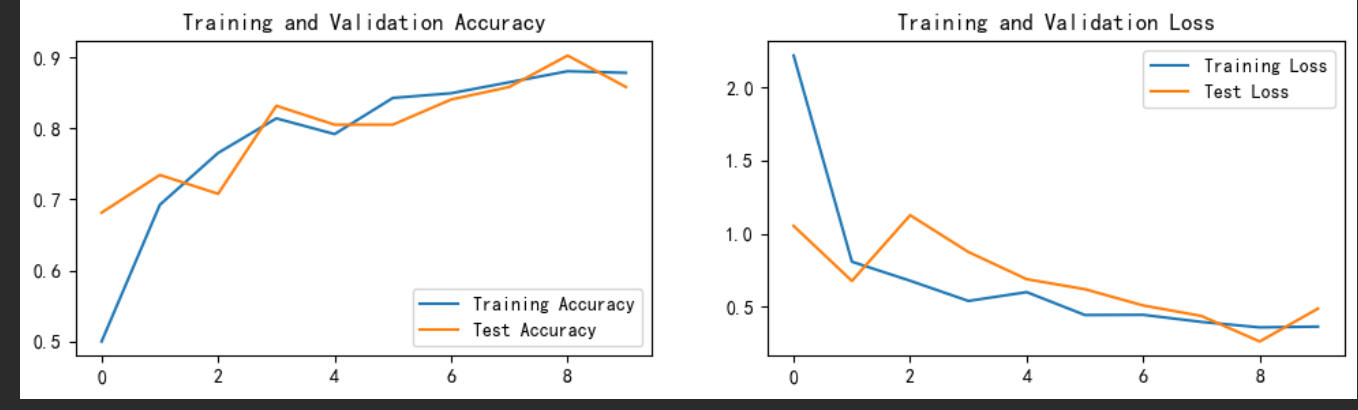
## 3.指定图片预测
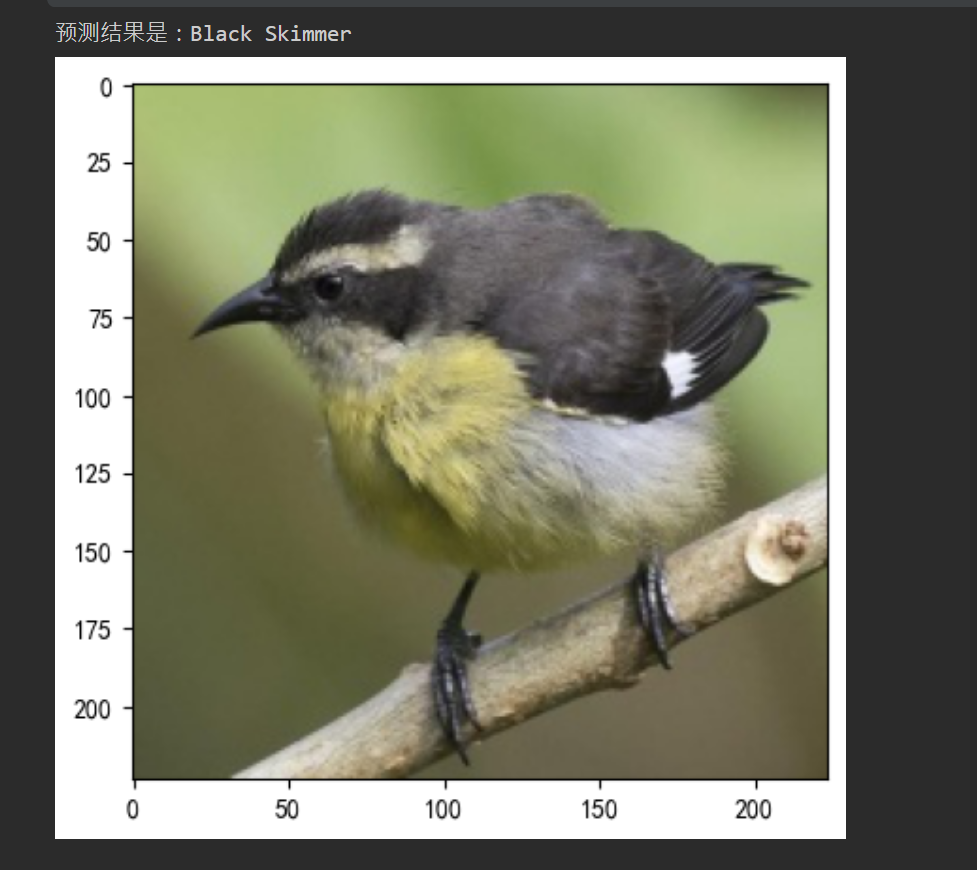
## 4.模型评估
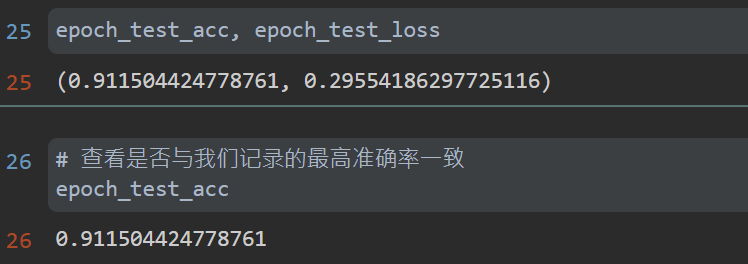















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









