





LMFusion: Adapting Pretrained Language Models for Multimodal Generation(翻译)
论文地址:[2412.15188] LMFusion: Adapting Pretrained Language Models for Multimodal Generation
摘要翻译
我们提出了 LMFusion,这是一个框架,用于为预训练的纯文本大语言模型 (LLM) 提供多模式生成功能,使它们能够理解和生成任意序列的文本和图像。 LMFusion 利用现有 Llama-3 的权重来自回归处理文本,同时引入额外的并行转换器模块来处理扩散图像。 在训练期间,来自每种模态的数据被路由到其专用模块:模态特定的前馈层、查询键值投影和标准化层独立处理每种模态,而共享的自注意力层允许跨文本和图像特征进行交互 。 通过冻结文本特定模块并仅训练图像特定模块,LMFusion 保留了纯文本 LLM 的语言能力,同时发展了强大的视觉理解和生成能力。 与从头开始预训练多模态生成模型的方法相比,我们的实验表明,LMFusion 仅使用 50% 的 FLOP 即可将图像理解提高 20%,图像生成提高 3.6%,同时保持 Llama-3 的语言能力。 我们还证明该框架可以适应具有多模式生成能力的现有视觉语言模型。 总体而言,该框架不仅利用了纯文本法学硕士的现有计算投资,而且还实现了语言和视觉功能的并行开发,为高效的多模式模型开发提供了一个有希望的方向。
1 Introduce
在过去的几年里,我们看到多模态生成模型取得了重大进展,能够理解和生成任意序列中的交错文本和图像(Dong 等人,2023;Koh 等人,2024;Lin 等人,2024b)。 Transfusion (Zhou et al., 2024)、Chameleon (Team, 2024) 和 Unified-IO (Lu et al., 2022, 2024) 等模型展示了无缝处理图像和文本模式的统一架构的潜力。 然而,这些模型通常从头开始训练,需要大量的计算资源才能熟练掌握所有模式。 即使掌握单一模态,计算成本也是巨大的——训练像 Llama-3(Dubey 等人,2024 年)这样最先进的纯文本大型语言模型 (LLM) 需要训练超过 15 万亿个令牌。
考虑到这些计算需求,我们研究了一种可重用和适应现有预训练 LLM 的替代范式(Ge et al., 2023;Sun et al., 2023;Wu et al., 2024)。 我们解决了一个基本的研究问题:如何保留预训练的法学硕士的纯文本性能,同时为他们配备视觉理解和生成能力? 我们的实验表明,对多模式数据上预训练的纯文本法学硕士进行天真的微调会导致其语言处理能力显着下降。
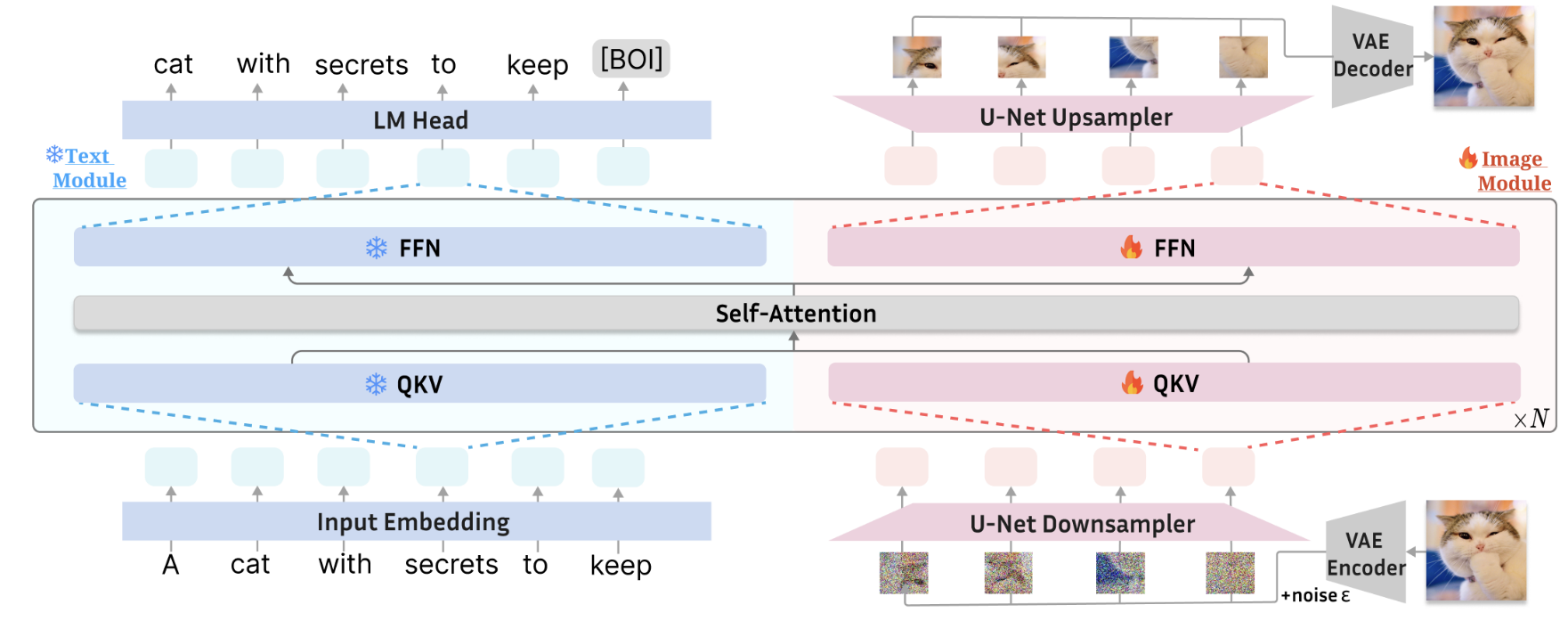
为了应对这一挑战,我们引入了 LMFusion,这是一个框架,通过基于 Transfusion(Zhou 等人,2024)的配方,增强了预训练的纯文本 Llama-3(Dubey 等人,2024)的多模式功能。 借鉴最近关于模态分离的并行工作(Shen 等人,2023;Chen 等人,2023;Liang 等人,2024;Liu 等人,2024a),LMFusion 集成了为语言处理而预训练的原始 Llama 模块,同时 引入额外的专用变压器模块用于视觉理解和生成任务。 如图 1 所示,我们采用特定于模态的查询键值 (QKV) 投影和前馈网络 (FFN) 分别处理文本和图像数据,同时仍然允许联合自注意力层中的跨模态交互 。 通过冻结文本模块,同时微调图像模块,我们保留了预训练的LLMs的纯语言能力,同时为视觉理解和生成的学习提供了一个良好的开端。 与从头开始预训练多模态生成模型相比,这种方法避免了在训练过程中包含纯文本数据的需要,从而显着降低了计算需求。
为了评估我们方法的有效性,我们在受控环境中进行了全面的实验,比较 LMFusion 和 Transfusion。 具体来说,我们使用预训练的 Llama-3 8B 模型(Dubey 等人,2024)初始化 LMFusion 架构,并继续对与 Transfusion 中相同的图像数据进行训练(Zhou 等人,2024)。 与 Transfusion 相比,LMFusion 在图像理解方面提高了 20%,在图像生成方面提高了 3.6%,同时仅使用 50% 的 FLOP。 它还保留了 Llama-3 的纯文本性能,比 Transfusion 高出 11.6%。 图 2 显示了 LMFusion 生成的图像。 此外,我们进一步证明该框架可以适应具有多模式生成能力的现有视觉语言模型(例如 LLaVA)。
通过消融研究,我们分析了 LMFusion 的关键架构决策:将不同模态数据的自注意力和 FFN 分开,同时冻结预训练语言模态的权重。 我们表明,对多模态数据(无分离)的密集预训练LLMs进行天真的微调会导致其原始语言能力的灾难性遗忘。 此外,深度分离被证明比浅层分离(仅使用特定于模态的 FFN)更有效,两种方法都优于没有分离的模型。
总体而言,LMFusion 具有以下主要特征: (1) 计算重用:在开发多模式生成模型时,它利用纯文本LLMs的现有计算投入(这里指的是预训练好的LLMs的模型)。 这消除了对纯文本数据进行重新训练的需要,从而显着降低了计算需求。 (2) 性能保存和迁移:它完全保留了预训练的LLM强大的纯文本性能,并有助于在多模态生成设置中更好地学习图像理解和生成。
2 Background: Transfusion
Transfusion (Zhou et al., 2024) 是一个统一的多模态模型,通过联合预测语言中的下一个标记和扩散图像,能够执行文本生成、图像理解和图像生成任务。给定多模态输入( x t x t , x i m g x^{txt},x^{img} xtxt,ximg),给定多模态输入( x t x t , x i m g x^{txt},x^{img} xtxt,ximg),Transfusion 模型联合学习,在 x t x t x^{txt} xtxt 上进行语言建模(第 2.1 节),在 x i m g x^{img} ximg 上进行图像扩散(第 2.2 节)。其架构与标准 Transformer(Vaswani 等人,2017)相同,并具有附加的 U-Net 结构(Ronneberger 等人,2015),可在扩散前后向下和向上投影图像表示。
2.1 Language Modeling
给定一系列离散语言标记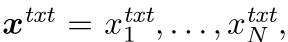 语言模型 θ 表示其联合概率:
语言模型 θ 表示其联合概率: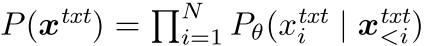 ,该公式设置了一个自回归任务,其中每个标记
x
i
t
x
t
x^{txt}_i
xitxt都是根据其前面的标记
x
<
i
t
x
t
x^{txt}_{<i}
x<itxt 来预测的。语言模型是通过最小化 Pθ 和观察到的数据分布之间的交叉熵来学习的,这通常称为 LM 损失。
,该公式设置了一个自回归任务,其中每个标记
x
i
t
x
t
x^{txt}_i
xitxt都是根据其前面的标记
x
<
i
t
x
t
x^{txt}_{<i}
x<itxt 来预测的。语言模型是通过最小化 Pθ 和观察到的数据分布之间的交叉熵来学习的,这通常称为 LM 损失。
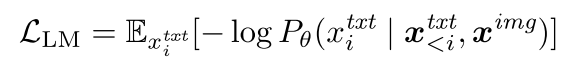
或者,如果语言标记之前存在图像数据(例如图像标题数据),则 Transfusion 将 x i m g x^{img} ximg的表示添加为目标的附加条件。 下面介绍了表示 x i m g x^{img} ximg的更多细节。
2.2 Image Diffusion
给定原始图像,Transfusion 首先使用预训练和冻结的 VAE 标记器将图像编码为连续潜在表示 x i m g x^{img} ximg序列(Kingma,2013)。 然后,它采用去噪扩散概率模型(即 DDPM)来学习反转在前向过程中添加的逐渐噪声添加过程(Ho 等人,2020)。 在前向扩散过程中,高斯噪声 ϵ ∼ N ( 0 , I ) ϵ ∼ N(0, I) ϵ∼N(0,I)通过 T 个步骤添加到图像表示 x i m g x^{img} ximg 中,创建一系列噪声图像表示 x 0 , x 1 , . . . , x T x_0, x_1, ..., x_T x0,x1,...,xT。 具体来说,在每个步骤 t,噪声图像表示由下式给出:
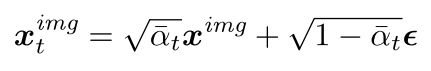
这里 α ˉ t \barα_t αˉt 遵循常见的余弦方法(Nichol 和 Dhariwal,2021)。
在相反的过程中,具有参数 θ 的扩散模型 ϵ θ ( ⋅ ) ϵθ(·) ϵθ(⋅) 学习在给定时间步 t 处的噪声数据 x t i m g x^{img}_t xtimg 和上下文 x t x t x^{txt} xtxt的情况下预测添加的噪声 ϵ,该上下文 x t x t x^{txt} xtxt可以包括文本提示,例如图像扩散的标题:1
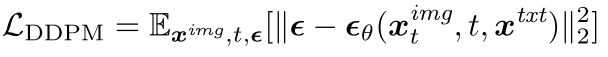
Transfusion 架构包含 U-Net 下采样器和上采样器,以减少 x i m g x^{img} ximg 的维度。 U-Net 下采样器在主 Transformer 模块之前将图像转换为更少的块,而上采样器在 Transformer 之后将它们投影回 x i m g x^{img} ximg 的原始维度。
2.3 Training Objective
在训练期间,Transfusion 被优化以预测文本输入 x t x t x^{txt} xtxt上的 LM 损失和图像输入 x i m g x^{img} ximg上的扩散损失。 使用超参数 λ 组合这两个损失:
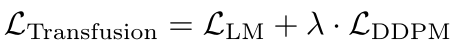
3 LMFusion
Transfusion 的一个显着特点是,它具有与主流 LLM(例如 Llama (Touvron et al., 2023))相同的架构,同时能够通过端到端的方式同时进行文本生成、图像理解和图像生成。 训练(公式 4)。
Zhou 等人(2024)从头开始训练了 Transfusion 模型,使用了language-only 和图像-描述数据。然而,从头训练这样一个模型需要大量的计算资源,而且它在language-only 任务上的表现仍然落后于预训练的纯文本大语言模型(LLMs)。在本研究中,我们的目标是有效地调整预训练的纯文本 LLM,以处理图像理解和生成任务。具体而言,我们基于一个开放权重的 LLM——Llama-3(Dubey 等人,2024),并继续训练该模型,使其能够处理这两种模态。由于 Transfusion 模型在语言建模和图像扩散目标上使用共享参数,关键挑战在于如何在优化新图像能力的同时,防止 Llama-3 在文本-only 任务上的强大表现下降。
3.1 Model Architecture
为了应对上述挑战,我们提出了 LMFusion,这是一个框架,它将预训练的纯文本 Llama 模型与用于视觉生成和理解的专用图像转换器相结合,使每种模态能够通过独立的权重进行处理。 通过冻结文本模块,同时微调视觉模块,我们保留了其纯语言功能,同时促进了视觉理解和生成的学习。
LMFusion 是一个仅包含解码器的模型,由 N 个转换器层组成。 如图 1 所示,设计的核心是特定于模态的注意力层和前馈网络 (FFN),每个层仅处理来自其相应模态的数据。不失一般性,我们在下面以单个变压器层的配置来描述 LMFusion,将残差连接和层归一化直接折叠到自注意力和 FFN 中。模型的输入是文本标记
x
t
x
t
x^{txt}
xtxt 和噪声图像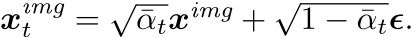
我们使用蓝色表示特定于文本的模块,使用红色表示特定于图像的模块。
输入投影 输入文本标记 x t x t x^{txt} xtxt由线性嵌入层投影到 中的文本隐藏状态 h i n t x t h^{txt}_{in} hintxt序列。 噪声图像 x t i m g x^{img}_t xtimg 通过 U-Net 下采样器投影到一系列图像表示 h i n i m g h^{img}_{in} hinimg 。
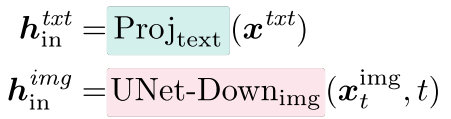
然后将文本隐藏状态 h t x t h_{txt} htxt 或图像隐藏状态 h i m g h_{img} himg 输入到下面的注意力层中。
特定于模态的自注意力我们为每种模态创建单独的注意力矩阵。 具体来说,文本隐藏状态 h i n t x t h^{txt}_{in} hintxt 和图像隐藏状态 h i n i m g h^{img}_{in} hinimg 通过单独的 Q、K、V 矩阵转换为各自的查询、键和值。 预注意力层归一化也是特定于模态的,并被折叠到 QKV 函数中。
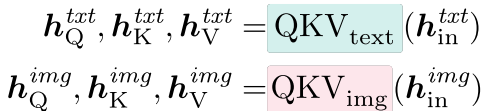
我们通过将图像和文本模态中的查询、键和值连接成统一的序列来实现跨模态注意力。 然后使用每种模态的单独的 O 权重将文本和图像标记位置处的注意力加权值投影回隐藏状态维度。
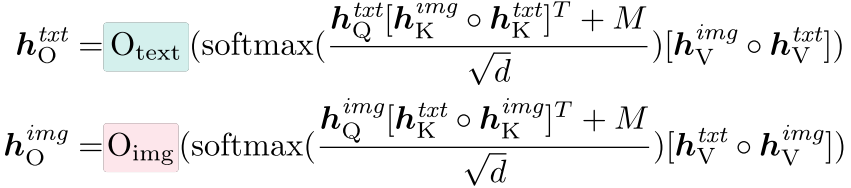
其中 ◦ ◦ ◦ 表示串联。 M 表示与 Transfusion (Zhou et al., 2024) 中相同的混合注意掩模,其中因果掩模应用于文本标记,双向掩模应用于图像标记。 这种设计允许在模态内部和跨模态进行自我关注,从而鼓励跨模态集成。
特定于模态的前馈网络 在注意力层之后,我们采用特定于模态的 FFN 来分别处理文本和图像数据。 FFN 前层归一化也是特定于模态的,并折叠在 FFN 函数中。
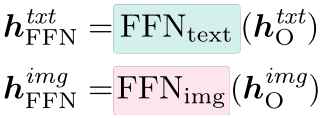
输出投影最后,经过 N 层自注意力和 FFN 后,生成的隐藏状态要么通过语言模型的输出层投影到文本中的对数,要么通过 U-Net 上采样器投影到图像中的预测噪声。
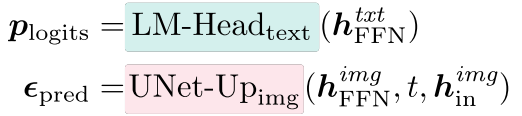
与 Transfusion 相同,输出
p
l
o
g
i
t
s
p_{logits}
plogits 和 $ϵ_{pred} $分别通过语言建模损失(公式 1)和 DDPM 损失(公式 3)。 文本模块中的所有参数以及图像模块中的自注意力和 FFN 参数都是从预训练的 Llama 模型初始化的。 在优化过程中,我们将文本和图像参数组的学习率解耦:文本学习率
η
t
e
x
t
η_{text}
ηtext 用于  ,图像学习率
η
i
m
g
η_{img}
ηimg 用于
,图像学习率
η
i
m
g
η_{img}
ηimg 用于 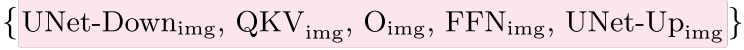 为了保持模型在纯文本基准上的性能,我们在主要实验中使用
η
t
e
x
t
η_{text}
ηtext = 0(冻结文本模块)。
为了保持模型在纯文本基准上的性能,我们在主要实验中使用
η
t
e
x
t
η_{text}
ηtext = 0(冻结文本模块)。
为了保持模型在纯文本基准上的性能,我们在主要实验中使用 η t e x t η_{text} ηtext = 0(冻结文本模块)。
[外链图片转存中…(img-TaWqinkc-1736321859871)]
图 1 LMFusion 概述。 它使用特定于模态的 FFN 和 QKV 投影来分别处理文本和图像数据:文本“A cat with Secrets to keep”进入文本模块,而猫的图像块进入图像模块。 在自注意力层中,文本和图像表示可以关注跨模态边界的所有先前上下文。 这两个模块都是从 Llama-3 初始化的,其中文本模块被冻结以保留语言功能,而图像模块则根据图像数据进行训练。 层归一化和残差连接被折叠到 QKV 和 FFN 模块中。 特殊的 BOI 令牌将序列中的不同模式分开。

















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









