







1.VGGNet
VGGNet由牛津大学和DeepMind公司提出
获得ImageNet LSVRC-2014亚军
比较常用的是VGG-16,结构规整,具有很强的拓展性
1.1 和AlexNet比较
相较于AlexNet,VGG-16网络模型中的卷积层均使用3*3的卷积核,且均为步长为1的卷积,池化层均使用2*2的池化核,步长为2
优势/创新:
-
更深的网络结构: VGG-16比AlexNet更深,具有16层的卷积层和全连接层,而不是AlexNet的8层。这种更深的结构有助于提取更复杂、更抽象的特征,从而提高了模型的性能。
-
统一的卷积核尺寸: VGG-16网络中的所有卷积层都使用了相同尺寸的卷积核(通常是3x3),而AlexNet则使用了不同尺寸的卷积核。这种统一的卷积核尺寸简化了网络结构,使得它更容易理解和实现,并且具有更好的参数共享特性。
-
更小的卷积步长和填充: VGG-16网络使用了更小的卷积步长和填充,这意味着特征图的尺寸在经过卷积层后几乎没有缩小。这有助于保留更多的空间信息。
-
使用更多的卷积层: VGG-16在网络中使用了更多的卷积层,这使得网络可以学习更多层次、更丰富的特征表示。这有助于提高模型的泛化能力和性能。
-
模型简单而有效: 尽管VGG-16相对于AlexNet更深,但它的结构非常简单和规整,易于理解和实现。这种简单性使得VGG-16成为了一个广泛应用于各种计算机视觉任务的基准模型。
1.2 网络结构
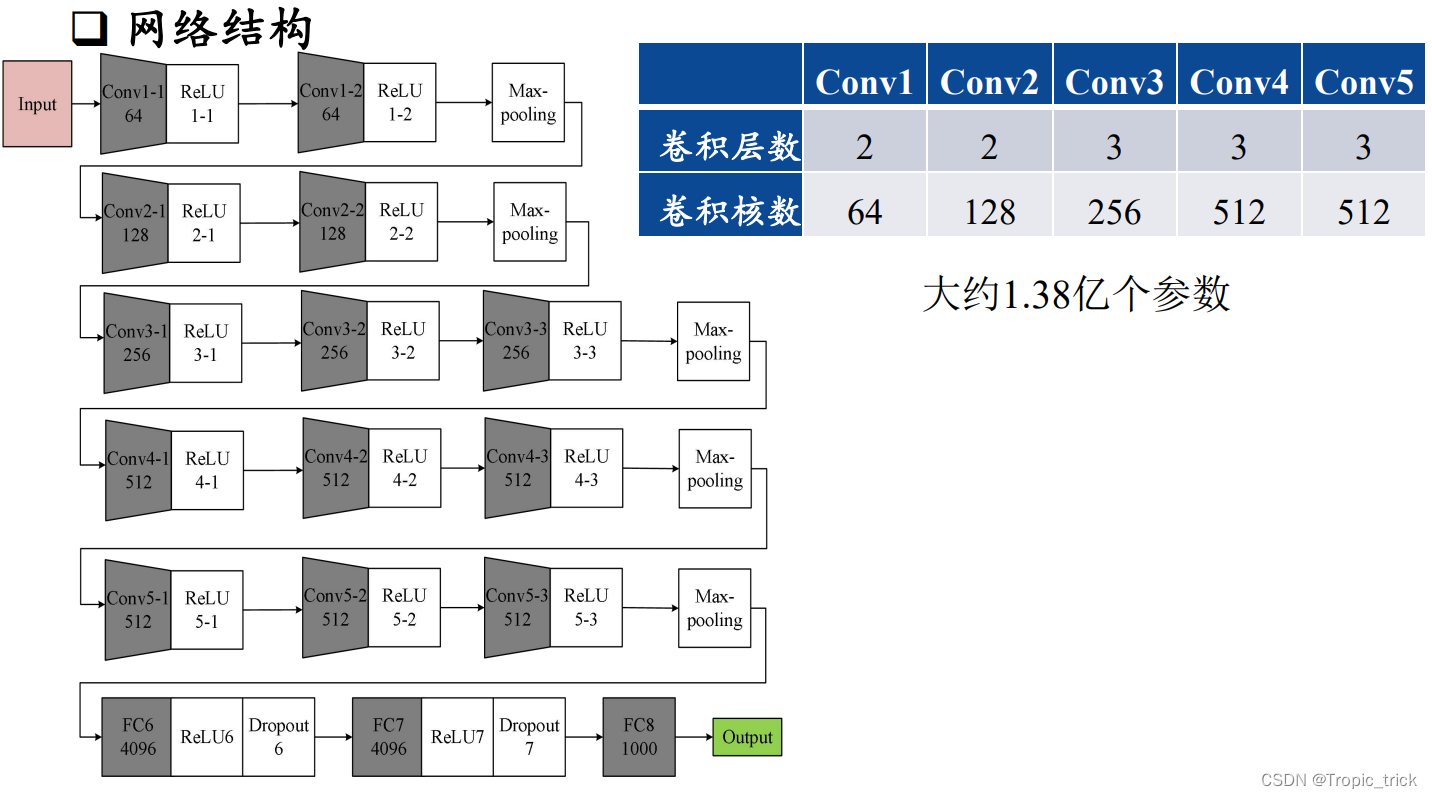
两个卷积核大小为3*3的卷积层串联后的感受野尺寸为5*5, 相当于单个卷积核大小为5*5的卷积层,两者参数数量比值为(2*3*3)/(5*5)=72% ,两个卷积核大小为3*3的卷积层参数量更少
此外,两个的卷积层串联可使用两次ReLU激活函数,而一 个卷积层只使用一次。激活函数可以提高模型的学习能力。

1.3 代码参考

2.Inception Net
Google公司2014年提出,获得ImageNet LSVRC-2014冠军
文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。看得更广/深。
深度:层数更深,采用了22层,在不同深度处增加了两个loss来避免上述提到的梯度消失问题
宽度:Inception Module包含4个分支,在卷积核3x3、5x5 之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用
1×1的卷积的作用:
可以跨通道组织信息, 来提高网络的表达能力; 可以对输出通道进行升维和降维

2.1 Inception Net v1

2.2 Inception Net v4
去掉了全连接层:

去掉全连接层有什么好处呢?
①参数数量减少: 全连接层的参数数量非常庞大,尤其是当连接到高维特征图时。这会导致参数数量极多,增加过拟合的风险,有更好的泛化能力。全连接层容易记住训练数据,导致在测试数据上的表现较差。
②计算效率提高:去掉全连接层减少了计算负担和内存需求。卷积层在参数效率上更优,并且可以在不同空间位置共享权重,使其在计算上更高效。
③全局平均池化(GAP):Inception-v4用全局平均池化(Global Average Pooling, GAP)替代全连接层。GAP通过取平均值将每个特征图缩减为一个值,有效地总结了图像的整个空间域中的特征存在情况。这不仅提高了模型的可解释性,还进一步降低了过拟合风险。
④空间不变性:GAP通过总结特征图提供了一定程度的空间不变性,这意味着网络对输入图像中的平移和对象位置的微小变化更具鲁棒性。
⑤简化架构:去掉全连接层简化了网络的整体架构,使其更容易训练和调优,更容易理解和调试。
⑥增强迁移学习能力

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











