








–https://arxiv.org/abs/2006.11239
**
留意更多动态,欢迎关注微信公众号:组学之心
**
Diffusion模型的设计理念
总结前文,生成模型的目标是根据给定的样本数据生成新的样本数据。而且,可以是跨模态的生成数据。
那怎么生成呢?
给定一批训练数据
X
X
X,假设它服从某种复杂的真实分布
p
(
x
)
p(x)
p(x)(你知道一道菜),训练数据可以视为从真实分布中采样得到的观测样本
x
x
x(你也知道了这做道菜的正宗材料和做法)。如果能从观测样本中估计出训练数据的真实分布(你自己去动手复刻这道菜),就可以从该分布中源源不断的采样生成新的样本(你任何时候都可以做出这道菜,即使没有老师傅的那么正宗)。
生成模型就是这么干的,它的作用就是在估计训练数据的真实分布,并将其假定为
q
(
x
)
q(x)
q(x)。在深度学习中,这个叫做拟合网络。
那怎么才能评价
q
(
x
)
q(x)
q(x)和真实分布
p
(
x
)
p(x)
p(x)差距大不大呢(你做的菜和老师傅做的菜味道差多少)?其中一种思路是用最大似然估计思想,要求所有的训练数据样本采样自
q
(
x
)
q(x)
q(x)的概率最大(你尽量让每道你做的菜被认为是老师傅做的菜的可能性最大)。所以生成模型的学习目标就是对训练数据样本的分布进行建模。
扩散Diffusion的思想来自非平衡力学。举个例子,第一墨水滴入水中,它会扩散开来,一开始刚刚滴入的时候认为是墨水的初始状态,它的概率分布描述很难很复杂;随着扩散的进行,墨水会和水混合,最后水的颜色变成墨水的颜色,此时墨水的概率分布变得简单均匀,此时可以轻松的用数学公式来描述它。非平衡热力学可以描述这滴墨水随着时间推移的扩散过程中每一个“时刻”状态的概率分布(Diffusion的前向过程),如果把这个过程反过来,就可以从简单的分布中逐步的推断出复杂的分布(Diffusion的逆向过程)。
仅有上面说到的条件还是很难从简单的分布推导复杂的分布。DDPM(最早的Diffusion模型)还做了个假设,假设扩散过程是马尔可夫过程(每一个时刻的状态概率分布 = 上一时刻的状态概率分布 + 当前时刻的高斯噪声),以及假设扩散过程的逆过程是高斯分布。
扩散模型预测的是噪声残差,要求逆过程中预测的噪音分布与前向过程中施加的噪声分布之间“距离”最小,其最终优化目标的函数:
L
s
i
m
p
l
e
=
E
x
0
,
ϵ
0
ˉ
[
∥
ϵ
0
ˉ
−
ϵ
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
0
ˉ
,
t
)
∥
2
]
L_{simple} = \mathbb{E}_{x_0, \bar{\epsilon_0}} \left[ \| \bar{\epsilon_0} - \epsilon_{\theta}(\sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \bar{\epsilon_0}, t) \|^2 \right]
Lsimple=Ex0,ϵ0ˉ[∥ϵ0ˉ−ϵθ(αˉtx0+1−αˉtϵ0ˉ,t)∥2]
所以在训练DDPM时,用一个MSE(均方误差)损失来最小化‘预测的噪音分布’和‘添加的在噪音分布’就可以实现最终的优化目标。
开始浅浅的实战一波
先用MNIST手写数字识别数据集来练手
1.环境准备
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #用GPU加速
print(f'Using device: {device}')
2.测试数据集
dataset = torchvision.datasets.MNIST(root='00dataset/', train=True,
download=True, transform=torchvision.transforms. ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
x, y = next(iter(train_dataloader))
print('Input shape:', x.shape) # torch.Size([8, 1, 28, 28]) (B,C,H,W)
print('Labels:', y) # tensor([5, 8, 2, 3, 6, 0, 6, 8])
用MNIST下载数据集并读入数据,每批次8张图片。MNIST数据集是灰度的28×28像素图片,所以是1通道,28,28。
加入噪声:amount=1的时候会得到一个存粹的噪声。
def Addnoise(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1) # 调整形状以便广播
return x * (1 - amount) + noise * amount
# 绘制输入数据
fig, axs = plt.subplots(2, 8, figsize=(12, 3))
fig.suptitle('Input and Add noise Data')
# 展示原始数据
for i in range(8):
axs[0, i].imshow(x[i, 0], cmap='Greys')
axs[0, i].axis('off')
axs[0, i].set_title(f'Label: {y[i].item()}')
# 添加噪声
amount = torch.linspace(0, 1, x.shape[0]) # 从左到右增加噪声量
noised_x = Addnoise(x, amount)
# 展示加噪声的数据
for i in range(8):
axs[1, i].imshow(noised_x[i, 0], cmap='Greys')
axs[1, i].axis('off')
axs[1, i].set_title(f'Amount: {amount[i].item():.2f}')
plt.tight_layout()
plt.savefig('00zuxuezhixin/Addnoise_mnist.png')
plt.show()

3.模型训练
3.1 UNet模型
在训练之前,需要一个模型,能够接收和输出相同shape的噪音图像。UNet网络是不错的选择。
class MinimalUNet(nn.Module):
"""A minimal UNet implementation."""
def __init__(self, in_channels=1, out_channels=1):
super(MinimalUNet, self).__init__()
self.down_layers = nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.SiLU()
self.pool = nn.MaxPool2d(2)
self.upsample = nn.Upsample(scale_factor=2)
def forward(self, x):
skips = []
for i, layer in enumerate(self.down_layers):
x = self.act(layer(x))
if i < len(self.down_layers) - 1:
skips.append(x)
x = self.pool(x)
for i, layer in enumerate(self.up_layers):
if i > 0:
x = self.upsample(x)
x += skips.pop()
x = self.act(layer(x))
return x
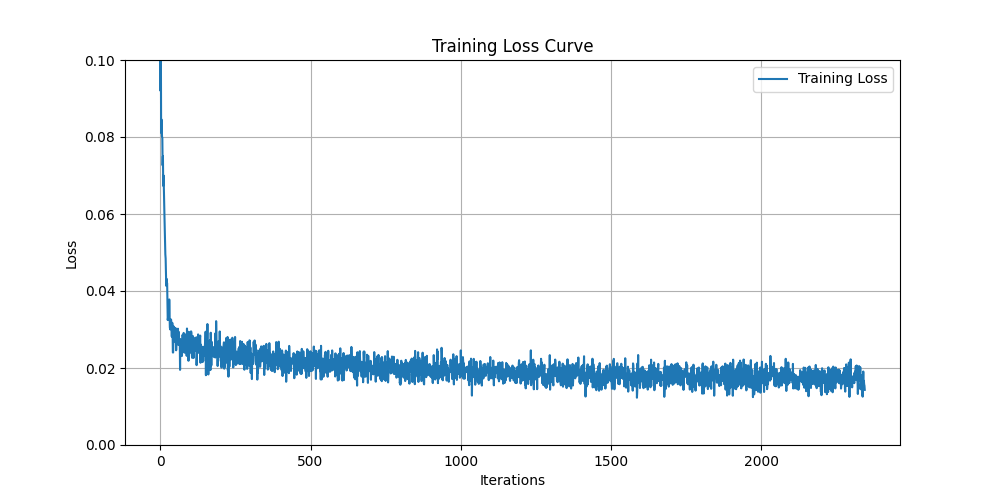
3.2 开始训练,并绘制训练集的损失值
train_dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
n_epochs = 5
net = MinimalUNet()
net.to(device)
# 损失函数和优化器
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# 记录每一epoch的损失值
losses = []
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = Addnoise(x, noise_amount)
# 获取模型的预测
pred = net(noisy_x)
loss = loss_fn(pred, x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:05f}')
# 绘制损失值曲线
plt.figure(figsize=(10, 5))
plt.plot(losses, label='Training Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.legend()
plt.grid(True)
plt.ylim(0, 0.1)
plt.savefig('00zuxuezhixin/training_loss_curve.png')
plt.show()
此时的损失为:
Finished epoch 0. Average loss for this epoch: 0.026267
Finished epoch 1. Average loss for this epoch: 0.020319
Finished epoch 2. Average loss for this epoch: 0.018795
Finished epoch 3. Average loss for this epoch: 0.017766
Finished epoch 4. Average loss for this epoch: 0.017344
3.3 查看不同程度的噪音数据和恢复效果
x, y = next(iter(train_dataloader))
x = x[:10] # 仅使用前10个样本进行绘图
# 添加不同程度的噪声
amount = torch.linspace(0, 1, x.shape[0]) # 从左到右增加噪声量
noised_x = Addnoise(x, amount)
# 获取模型预测
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
# 绘图
fig, axs = plt.subplots(3, 1, figsize=(14, 9))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x, nrow=10, padding=2, normalize=True).permute(1, 2, 0).numpy(), cmap='Greys')
axs[1].set_title('Add noise data')
axs[1].imshow(torchvision.utils.make_grid(noised_x, nrow=10, padding=2, normalize=True).permute(1, 2, 0).numpy(), cmap='Greys')
axs[2].set_title('Network Predictions')
axs[2].imshow(torchvision.utils.make_grid(preds, nrow=10, padding=2, normalize=True).permute(1, 2, 0).numpy(), cmap='Greys')
plt.tight_layout()
plt.savefig('00zuxuezhixin/network_predictions.png')
plt.show()

可以看到,对于噪音较低的输入,模型的预测效果很好。反之则效果很差,噪音量上升,模型能够获得的信息开始减少。
4.采样过程
扩散模型在高噪音的时候预测效果不好,我们可以将它输入模型中获得新的预测结果,如果新的预测结果比上一次要好一些(噪音更少),那可以借助这个输出再次输入到模型中,进行迭代。通过迭代过程逐步去噪图像,并展示每一步的输入图像和模型预测的图像。
4.1 逐步去噪过程的可视化
借助逐步去噪的方式从随机噪声生成图像,并可视化整个过程的每一步。
n_steps = 5
x = torch.rand(8, 1, 28, 28).to(device) # 从随机噪声开始生成输入图像,形状为[8, 1, 28, 28]
step_history = [x.detach().cpu()] # 保存每一步的输入图像
pred_output_history = [] # 保存每一步的模型预测
for i in range(n_steps):
with torch.no_grad(): # 推理阶段不需要计算梯度
pred = net(x) # 预测去噪后的图像
pred_output_history.append(pred.detach().cpu())
mix_factor = 1/(n_steps - i) # 确定当前步骤的混合因子
x = x*(1-mix_factor) + pred*mix_factor # 按混合因子更新输入图像
step_history.append(x.detach().cpu())
fig, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)
axs[0,0].set_title('x (model input)')
axs[0,1].set_title('model prediction')
for i in range(n_steps):
axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i], nrow=8, padding=2, normalize=True).permute(1, 2, 0))
axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i], nrow=8, padding=2, normalize=True).permute(1, 2, 0))
plt.tight_layout()
plt.savefig('00zuxuezhixin/sampling_5.png')
plt.show()
左侧是每个阶段模型输入的可视化结果,右侧是去噪后的结果

4.2 调整n_steps为40以进行完整的去噪过程
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0],)).to(device) * (1-(i/n_steps))
with torch.no_grad():
pred = net(x)
mix_factor = 1/(n_steps - i)
x = x*(1-mix_factor) + pred*mix_factor
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8, padding=2, normalize=True).permute(1, 2, 0))
plt.savefig('00zuxuezhixin/sampling_40.png')
plt.show()

5.优化
5.1 换更深的UNet网络
可以用Diffusers库中的UNet2DModel模型,模型架构比MinimalUNet复杂,前者有多个RestNet层、引入了注意力机制、上采样和下采样模块具有可学习的参数、还可以对时间步进行调节。因此,能够更好的处理噪音图像。这些模块都封装在了diffusers库中的UNet2DModel中。
from diffusers import DDPMScheduler, UNet2DModel
net = UNet2DModel(
sample_size=28, # 图像的尺寸
in_channels=1,
out_channels=1,
layers_per_block=2, # 每个UNet块ResNet层数
block_out_channels=(32, 64, 64),
down_block_types=(
"DownBlock2D", # ResNet下采样模块
"AttnDownBlock2D", # 有自注意力机制的ResNet下采样模块
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # 有自注意力机制的ResNet上采样模块
"UpBlock2D", # ResNet上采样模块
),
)
可以把它替换掉MinimalUNet就可以使用。
5.2 设定噪音调度器
查看输入和噪音在不同迭代周期中是怎么量化和叠加的
# 初始化调度器
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
sqrt_alphas_cumprod = noise_scheduler.alphas_cumprod.cpu() ** 0.5
sqrt_one_minus_alphas_cumprod = (1 - noise_scheduler.alphas_cumprod.cpu()) ** 0.5
plt.figure(figsize=(10, 6))
plt.plot(sqrt_alphas_cumprod, label=r"${\sqrt{\bar{\alpha}_t}}$")
plt.plot(sqrt_one_minus_alphas_cumprod, label=r"$\sqrt{(1 - \bar{\alpha}_t)}$")
plt.legend(fontsize="x-large")
plt.xlabel('Timesteps')
plt.ylabel('Value')
plt.title('Alphas Cumulative Products')
plt.grid(True)
plt.tight_layout()
plt.savefig('00zuxuezhixin/alphas_cumulative_products.png')
plt.show()
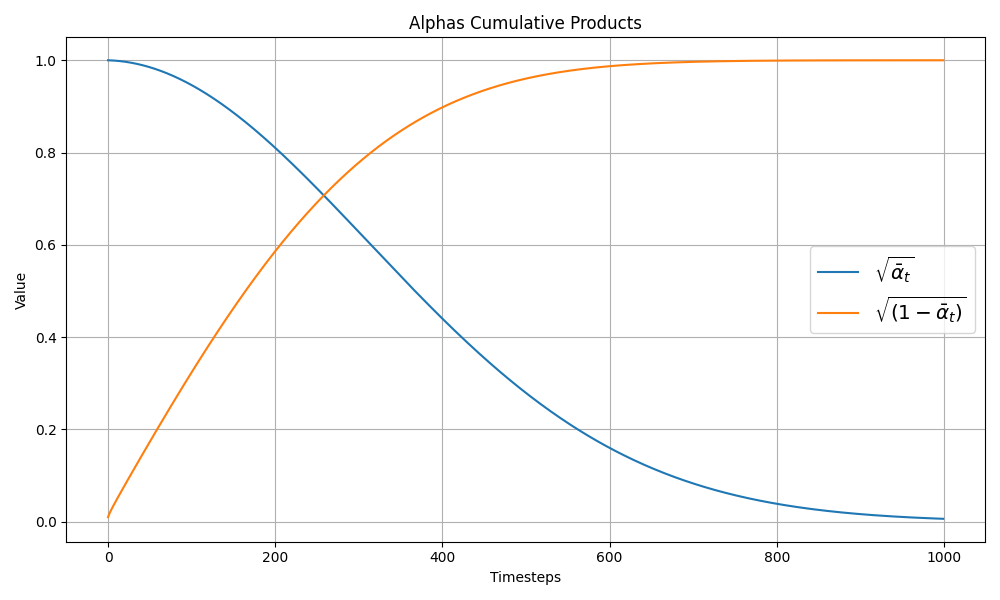
一开始如输入绝大部分是输入本身(蓝色线),随着时刻前进,噪音成分越来越多,输入成分越来越少,而且不是线性过程。
设定噪音调度器 + UNet2DModel代码实操:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = torchvision.datasets.MNIST(root='00dataset/', train=True, download=True, transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=128, shuffle=True)
model = UNet2DModel(
sample_size=28, # 图像的尺寸
in_channels=1,
out_channels=1,
layers_per_block=2, # 每个UNet块ResNet层数
block_out_channels=(32, 64, 64),
down_block_types=(
"DownBlock2D", # ResNet下采样模块
"AttnDownBlock2D", # 有自注意力机制的ResNet下采样模块
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # 有自注意力机制的ResNet上采样模块
"UpBlock2D", # ResNet上采样模块
),
)
n_epochs = 5
model.to(device)
# 损失函数和优化器
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
# 创建调度器
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
# 记录每一epoch的损失值
losses = []
for epoch in range(n_epochs):
for xb, _ in train_dataloader:
xb = xb.to(device)
noise = torch.randn_like(xb).to(device)
timesteps = torch.randint(0, 999, (xb.size(0),), device=device).long()
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
pred_noise = model(noisy_xb, timesteps).sample
loss = loss_fn(pred_noise, noise)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss:.5f}')
需要进一步调节epoch的数目,学习率等参数来优化。噪音调度器也是一个热门的研究方向,有Linear Schedule、Cosine Schedule、Sqrt Schedule、Adaptive Schedule、Mutual Information Schedule、Spindle Schedule等等,能更好的优化模型性能。

















 6371
6371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











