








–https://arxiv.org/abs/2006.11239
留意后续更新,欢迎关注微信公众号:组学之心
Diffusion(扩散模型)原理
扩散模型的相关工作大都起源于 OpenAI 于 2020 年提出的降噪扩散概率模型(Denoising Diffusion Probabilistic Models,DDPM)。DDPM 包含前向过程(Forward Process)和逆向过程(Reverse Process)
- 前向过程,称为扩散过程(Diffusion Process),本质上是在输入图像数据的基础上逐步注入符合高斯分布的随机噪声,直至图像数据本身变为服从标准高斯分布的随机噪声。
- 而逆向过程,则是进行图像生成的推断过程,当给定一个服从标准高斯分布的噪声,逐步去除噪声从而还原图像。
1. DDPM 前向过程
前向过程如图中的虚线箭头所示的 q q q 过程,给定真实图像 x 0 ∼ q ( x 0 ) \mathbf{x}_0 \sim q(\mathbf{x}_0) x0∼q(x0) 和 T T T 个方差超参数 β = { β t ∈ ( 0 , 1 ) } t = 1 T \boldsymbol{\beta} = \{ \beta_t \in (0,1) \}_{t=1}^{T} β={βt∈(0,1)}t=1T,前向过程会逐步在图像中添加高斯噪声,得到图像集合 { x 1 , x 2 , . . . , x T } \{\mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_T\} {x1,x2,...,xT}。

前向过程是马尔可夫过程
每个时刻的状态只与前一时刻的状态相关,因此前向过程是一个马尔可夫过程。以第 t 步为例, t t t 仅与 x t x_t xt 和 x t − 1 x_{t-1} xt−1 相关,那么有:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N} \left( \mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I} \right) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(\mathbf{x}_{1:T} | \mathbf{x}_0) = \prod_{t=1}^{T} q(\mathbf{x}_t | \mathbf{x}_{t-1}) q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
对于一个高斯分布 N ( x ; μ θ , σ θ 2 I ) \mathcal{N}(x; \mu_\theta, \sigma_\theta^2 \mathbf{I}) N(x;μθ,σθ2I),如果要从中采样一个 x x x,利用重参数技巧,可以将采样写成:
x = μ θ + σ θ ⊙ ϵ , ϵ ∼ N ( 0 , I ) x = \mu_\theta + \sigma_\theta \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) x=μθ+σθ⊙ϵ,ϵ∼N(0,I)
因此,对于前向过程中的任意步骤的状态 x t x_t xt,可以表示为:
x t = 1 − β t x t − 1 + β t ϵ t − 1 = 1 − β t ( 1 − β t − 1 x t − 2 + β t − 1 ϵ t − 2 ) + β t ϵ t − 1 = ( 1 − β t ) ( 1 − β t − 1 ) x t − 2 + ( 1 − β t ) β t − 1 ϵ t − 2 + β t ϵ t − 1 \begin{aligned} x_t &= \sqrt{1 - \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon_{t-1} \\ &= \sqrt{1 - \beta_t} \left( \sqrt{1 - \beta_{t-1}} x_{t-2} + \sqrt{\beta_{t-1}} \epsilon_{t-2} \right) + \sqrt{\beta_t} \epsilon_{t-1} \\ &= \sqrt{(1 - \beta_t)(1 - \beta_{t-1})} x_{t-2} + \sqrt{(1 - \beta_t) \beta_{t-1}} \epsilon_{t-2} + \sqrt{\beta_t} \epsilon_{t-1} \end{aligned} xt=1−βtxt−1+βtϵt−1=1−βt(1−βt−1xt−2+βt−1ϵt−2)+βtϵt−1=(1−βt)(1−βt−1)xt−2+(1−βt)βt−1ϵt−2+βtϵt−1
其中, ϵ t − 1 , ϵ t − 2 ∼ N ( 0 , I ) \epsilon_{t-1}, \epsilon_{t-2} \sim \mathcal{N}(0, \mathbf{I}) ϵt−1,ϵt−2∼N(0,I)。此外,对于两个独立的高斯分布 X ∼ N ( μ X , σ X 2 I ) \mathbf{X} \sim \mathcal{N}(\mu_X, \sigma_X^2 \mathbf{I}) X∼N(μX,σX2I) 与 Y ∼ N ( μ Y , σ Y 2 I ) \mathbf{Y} \sim \mathcal{N}(\mu_Y, \sigma_Y^2 \mathbf{I}) Y∼N(μY,σY2I),它们的和仍然服从高斯分布,即 X + Y ∼ N ( μ X + μ Y , ( σ X 2 + σ Y 2 ) I ) X + Y \sim \mathcal{N}(\mu_X + \mu_Y, (\sigma_X^2 + \sigma_Y^2) \mathbf{I}) X+Y∼N(μX+μY,(σX2+σY2)I)。
因此上述公式的后一项可写为:
( 1 − β t ) β t − 1 + β t ϵ ˉ t − 2 , ϵ ˉ t − 2 ∼ N ( 0 , I ) \sqrt{(1 - \beta_t) \beta_{t-1} + \beta_t} \bar{\epsilon}_{t-2}, \quad \bar{\epsilon}_{t-2} \sim \mathcal{N}(0, \mathbf{I}) (1−βt)βt−1+βtϵˉt−2,ϵˉt−2∼N(0,I)
将其代回到原公式中,得到:
x t = ( 1 − β t ) ( 1 − β t − 1 ) x t − 2 + ( 1 − β t ) β t − 1 + β t ϵ ˉ t − 2 x_t = \sqrt{(1 - \beta_t)(1 - \beta_{t-1})} x_{t-2} + \sqrt{(1 - \beta_t) \beta_{t-1} + \beta_t} \bar{\epsilon}_{t-2} xt=(1−βt)(1−βt−1)xt−2+(1−βt)βt−1+βtϵˉt−2
令
α
t
=
1
−
β
t
\alpha_t = 1 - \beta_t
αt=1−βt
α
ˉ
t
=
∏
i
=
1
T
α
i
\bar{\alpha}_t = \prod_{i=1}^{T} \alpha_i
αˉt=∏i=1Tαi,代入上述式,得到:
x t = a t a t − 1 x t − 2 + a t ( 1 − a t − 1 ) + 1 − a t ϵ ˉ t − 2 = a t a t − 1 x t − 2 + 1 − a t a t − 1 ϵ ˉ t − 2 = a ˉ t x 0 + 1 − a ˉ t ϵ ˉ 0 , ϵ ˉ t − 2 , … , ϵ ˉ 0 ∼ N ( 0 , I ) \begin{aligned} x_t &= \sqrt{a_t a_{t-1} x_{t-2}} + \sqrt{a_t (1 - a_{t-1})} + 1 - a_t \bar{\epsilon}_{t-2} \\ &= \sqrt{a_t a_{t-1} x_{t-2}} + \sqrt{1 - a_t a_{t-1} \bar{\epsilon}_{t-2}} \\ &= \sqrt{\bar{a}_t} x_0 + \sqrt{1 - \bar{a}_t} \bar{\epsilon}_0, \quad \bar{\epsilon}_{t-2}, \ldots, \bar{\epsilon}_0 \sim \mathcal{N}(0, I) \end{aligned} xt=atat−1xt−2+at(1−at−1)+1−atϵˉt−2=atat−1xt−2+1−atat−1ϵˉt−2=aˉtx0+1−aˉtϵˉ0,ϵˉt−2,…,ϵˉ0∼N(0,I)
至此,可以发现在给定方差超参数集合 β \beta β 的前提下,任意时刻的 x t x_t xt 都可以使用 x 0 x_0 x0 和 β \beta β 来表示,即:
q ( x t ∣ x 0 ) = N ( x t ; a ˉ t x 0 , ( 1 − a ˉ t ) I ) q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{a}_t} x_0, (1 - \bar{a}_t) I) q(xt∣x0)=N(xt;aˉtx0,(1−aˉt)I)
其中, a t = 1 − β t a_t = 1 - \beta_t at=1−βt, a ˉ t = ∏ i = 1 T a i \bar{a}_t = \prod_{i=1}^{T} a_i aˉt=∏i=1Tai, 且当 T → ∞ T \to \infty T→∞, a ˉ t = ∏ i = 1 T a i → 0 \bar{a}_t = \prod_{i=1}^{T} a_i \to 0 aˉt=∏i=1Tai→0, 从而 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)。即当前向过程的步数趋于无穷大时, x T x_T xT 最终将变为服从标准高斯分布的随机噪声。

如图所示为 DDPM 前向过程的简单示例,将
T
T
T 设置为 100,方差超参数
β
t
β_t
βt 从 0.0001 递增到 0.1,可以发现当步数增多,原始图像也逐渐变得难以辨认直到完全变为随机噪声
2. DDPM 逆向过程
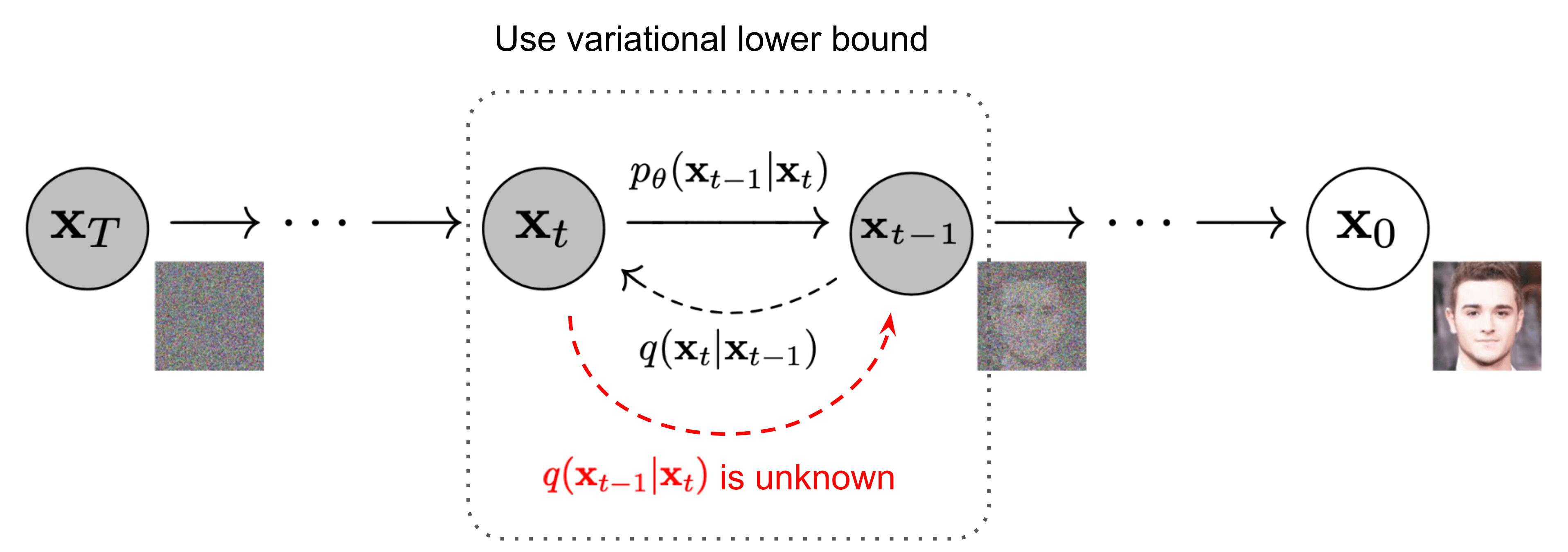
在前向过程中,通过
q
(
x
t
∣
x
t
−
1
)
q(x_t | x_{t-1})
q(xt∣xt−1) 逐步将真实图像
x
0
x_0
x0 变为标准高斯分布噪声
x
T
x_T
xT;反之,如果可以获取前向过程每一步的真实逆向分布 $q(x_{t-1} | x_t) $,那也可以从一个标准高斯分布
x
T
x_T
xT 逐步去除噪声还原得到原始图像
x
0
x_0
x0。
但实际上无法直接对真实逆向分布 q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt) 进行推断,DDPM 使用神经网络 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1} | x_t) pθ(xt−1∣xt) 对逆向分布进行预测。
逆向分布 p θ p_\theta pθ 可以表示为:
p θ ( x 0 : T ) = p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{0:T}) = p_{\theta}(x_T) \prod_{t=1}^{T} p_{\theta}(x_{t-1} \mid x_t) pθ(x0:T)=pθ(xT)t=1∏Tpθ(xt−1∣xt)
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_{\theta}(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
逆向过程中的贝叶斯推理
DDPM 模型的目标则是学习到正确的 μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t) 和 Σ θ ( x t , t ) \Sigma_\theta(x_t, t) Σθ(xt,t) 预测。虽然无法通过前向过程的分布 q ( x t ∣ x t − 1 ) q(x_t | x_{t-1}) q(xt∣xt−1) 去简单的推断出真实的逆向分布 q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt),但是可以将 x 0 x_0 x0(干净的图片数据)引入,根据贝叶斯公式,有:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t − 1 ) q ( x 0 ∣ x t − 1 ) q ( x t ∣ x t − 1 , x 0 ) q ( x 0 ) q ( x t ∣ x 0 ) q(x_{t-1} \mid x_t, x_0) = \frac{q(x_{t-1}) q(x_0 \mid x_{t-1}) q(x_t \mid x_{t-1}, x_0)}{q(x_0) q(x_t \mid x_0)} q(xt−1∣xt,x0)=q(x0)q(xt∣x0)q(xt−1)q(x0∣xt−1)q(xt∣xt−1,x0)
= q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 , x 0 ) q ( x t ∣ x 0 ) = \frac{q(x_{t-1} \mid x_0) q(x_t \mid x_{t-1}, x_0)}{q(x_t \mid x_0)} =q(xt∣x0)q(xt−1∣x0)q(xt∣xt−1,x0)
将 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0) 的均值和方差表示为 μ ~ t ( x t , x 0 ) \tilde{\mu}_t(x_t, x_0) μ~t(xt,x0) 和 β ~ t \tilde{\beta}_t β~t,即:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β ~ t I ) q(x_{t-1} \mid x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I) q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
逆向过程中的马尔科夫链推理
还记得刚刚提到前向过程是马尔可夫链吗?关键点是任一时间步的 x t x_t xt 都可以使用 x 0 x_0 x0 和 β \beta β来表示,那么可以将(11)中的每一分项分别表示为如下形式:
q ( x t ∣ x t − 1 , x 0 ) = q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}, x_0) = q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) q(xt∣xt−1,x0)=q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) q(x_{t-1} \mid x_0) = \mathcal{N}(x_{t-1}; \sqrt{\bar{\alpha}_{t-1}} x_0, (1 - \bar{\alpha}_{t-1}) I) q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t \mid x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
化简 q ( x t ∣ x t − 1 , x 0 ) q(x_t \mid x_{t-1}, x_0) q(xt∣xt−1,x0)
对于一元高斯分布 x ∼ N ( μ , σ 2 ) x \sim \mathcal{N}(\mu, \sigma^2) x∼N(μ,σ2),其概率密度函数为 f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) f(x)=2πσ1exp(−2σ2(x−μ)2)。将上述每一分项高斯分布的概率密度函数的指数部分代入,有:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t − 1 ∣ x 0 ) q ( x t ∣ x t − 1 , x 0 ) q ( x t ∣ x 0 ) q(x_{t-1} \mid x_t, x_0) = \frac{q(x_{t-1} \mid x_0) q(x_t \mid x_{t-1}, x_0)}{q(x_t \mid x_0)} q(xt−1∣xt,x0)=q(xt∣x0)q(xt−1∣x0)q(xt∣xt−1,x0)
∝ exp ( − ( x t − 1 − α ˉ t − 1 x 0 ) 2 2 ( 1 − α ˉ t − 1 ) ) exp ( − ( x t − 1 − β t x t − 1 ) 2 2 β t ) exp ( − ( x t − α ˉ t x 0 ) 2 2 ( 1 − α ˉ t ) ) \propto \frac{\exp\left( -\frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{2(1 - \bar{\alpha}_{t-1})} \right) \exp\left( -\frac{(x_t - \sqrt{1 - \beta_t} x_{t-1})^2}{2 \beta_t} \right)}{\exp\left( -\frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{2(1 - \bar{\alpha}_t)} \right)} ∝exp(−2(1−αˉt)(xt−αˉtx0)2)exp(−2(1−αˉt−1)(xt−1−αˉt−1x0)2)exp(−2βt(xt−1−βtxt−1)2)
= exp ( − 1 2 ( ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 + ( x t − 1 − β t x t − 1 ) 2 β t − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = \exp\left( -\frac{1}{2} \left( \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{1 - \bar{\alpha}_{t-1}} + \frac{(x_t - \sqrt{1 - \beta_t} x_{t-1})^2}{\beta_t} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1 - \bar{\alpha}_t} \right) \right) =exp(−21(1−αˉt−1(xt−1−αˉt−1x0)2+βt(xt−1−βtxt−1)2−1−αˉt(xt−αˉtx0)2))
= exp ( − 1 2 ( ( 1 1 − α ˉ t − 1 + 1 − β t β t ) x t − 1 2 − ( 2 α ˉ t − 1 x 0 1 − α ˉ t − 1 + 2 1 − β t x t β t ) x t − 1 + C ( x t , x 0 ) ) ) = \exp\left( -\frac{1}{2} \left( \left( \frac{1}{1 - \bar{\alpha}_{t-1}} + \frac{1 - \beta_t}{\beta_t} \right) x_{t-1}^2 - \left( 2 \frac{\sqrt{\bar{\alpha}_{t-1}} x_0}{1 - \bar{\alpha}_{t-1}} + 2 \frac{\sqrt{1 - \beta_t} x_t}{\beta_t} \right) x_{t-1} + C(x_t, x_0) \right) \right) =exp(−21((1−αˉt−11+βt1−βt)xt−12−(21−αˉt−1αˉt−1x0+2βt1−βtxt)xt−1+C(xt,x0)))
其中, C ( x t , x 0 ) C(x_t, x_0) C(xt,x0)为与 x t − 1 x_{t-1} xt−1无关项的组合,可以忽略。此外,一元高斯分布概率密度函数的指数部分可以展开:
exp ( − ( x − μ ) 2 2 σ 2 ) = exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \exp \left( -\frac{(x-\mu)^2}{2\sigma^2} \right) = \exp \left( -\frac{1}{2} \left( \frac{1}{\sigma^2} x^2 - \frac{2\mu}{\sigma^2} x + \frac{\mu^2}{\sigma^2} \right) \right) exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2))
1 σ 2 \frac{1}{\sigma^2} σ21和 2 μ σ 2 \frac{2\mu}{\sigma^2} σ22μ分别对应公式中的:
1 β ~ t = ( 1 1 − α ˉ t − 1 + 1 − β t β t ) = 1 − α ˉ t ( 1 − α ˉ t − 1 ) β t \frac{1}{\tilde{\beta}_t} = \left( \frac{1}{1 - \bar{\alpha}_{t-1}} + \frac{1 - \beta_t}{\beta_t} \right) = \frac{1 - \bar{\alpha}_t}{(1 - \bar{\alpha}_{t-1}) \beta_t} β~t1=(1−αˉt−11+βt1−βt)=(1−αˉt−1)βt1−αˉt
2 μ ~ t ( x t , x 0 ) β ~ t = ( 2 α ˉ t − 1 x 0 1 − α ˉ t − 1 + 2 1 − β t x t β t ) \frac{2\tilde{\mu}_t(x_t, x_0)}{\tilde{\beta}_t} = \left( 2 \frac{\sqrt{\bar{\alpha}_{t-1}} x_0}{1 - \bar{\alpha}_{t-1}} + 2 \frac{\sqrt{1 - \beta_t} x_t}{\beta_t} \right) β~t2μ~t(xt,x0)=(21−αˉt−1αˉt−1x0+2βt1−βtxt)
因此可以求得 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0)的均值 μ ~ t ( x t , x 0 ) \tilde{\mu}_t(x_t, x_0) μ~t(xt,x0)和方差 β ~ t \tilde{\beta}_t β~t:
μ ~ t ( x t , x 0 ) = α ˉ t − 1 β t x 0 + ( 1 − α ˉ t − 1 ) α t x t 1 − α ˉ t , β ~ t = ( 1 − α ˉ t − 1 ) β t 1 − α ˉ t \tilde{\mu}_t(x_t, x_0) = \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t x_0 + (1 - \bar{\alpha}_{t-1}) \sqrt{\alpha_t} x_t}{1 - \bar{\alpha}_t}, \quad \tilde{\beta}_t = \frac{(1 - \bar{\alpha}_{t-1}) \beta_t}{1 - \bar{\alpha}_t} μ~t(xt,x0)=1−αˉtαˉt−1βtx0+(1−αˉt−1)αtxt,β~t=1−αˉt(1−αˉt−1)βt
引入前向过程中已得到的 x t = α ˉ t x 0 + 1 − α ˉ t ϵ 0 ˉ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \bar{\epsilon_0} xt=αˉtx0+1−αˉtϵ0ˉ, ϵ 0 ˉ ∼ N ( 0 , I ) \bar{\epsilon_0} \sim \mathcal{N}(0, I) ϵ0ˉ∼N(0,I),可以得到 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ 0 ˉ ) x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}} \left( x_t - \sqrt{1 - \bar{\alpha}_t} \bar{\epsilon_0} \right) x0=αˉt1(xt−1−αˉtϵ0ˉ),代入上述公式中有:
μ ~ t ( x t , x 0 ) = 1 α t ( x t − β t 1 − α ˉ t ϵ 0 ˉ ) \tilde{\mu}_t(x_t, x_0) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \bar{\epsilon_0} \right) μ~t(xt,x0)=αt1(xt−1−αˉtβtϵ0ˉ)
- 虽然去除了 x 0 x_0 x0的影响,但是引入了一个新的变量 ϵ 0 ˉ \bar{\epsilon_0} ϵ0ˉ,它在前向过程中为标准高斯分布采样的噪声,但是在逆向过程中无法得知其真实值,DDPM引入一个参数化的神经网络模型 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t, t) ϵθ(xt,t)去预测噪声 ϵ 0 ˉ \bar{\epsilon_0} ϵ0ˉ, θ \theta θ表示模型的参数。
现在已经可以确定DDPM需要学习的逆向过程 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1} \mid x_t) pθ(xt−1∣xt)的分布:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_{\theta}(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_t, t), \Sigma_{\theta}(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) \mu_{\theta}(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) \right) μθ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))
Σ θ ( x t , t ) = β ~ t = ( 1 − α ˉ t − 1 ) β t 1 − α ˉ t ≈ β t \Sigma_{\theta}(x_t, t) = \tilde{\beta}_t = \frac{(1 - \bar{\alpha}_{t-1}) \beta_t}{1 - \bar{\alpha}_t} \approx \beta_t Σθ(xt,t)=β~t=1−αˉt(1−αˉt−1)βt≈βt
- DDPM 逆向过程可总结为:在给定 x t x_t xt的前提下,首先预测高斯噪声 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t, t) ϵθ(xt,t),然后计算 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1} \mid x_t) pθ(xt−1∣xt)的均值 μ θ ( x t , t ) \mu_{\theta}(x_t, t) μθ(xt,t)和方差 Σ θ ( x t , t ) \Sigma_{\theta}(x_t, t) Σθ(xt,t),最后通过重参数技巧计算得到 x t − 1 x_{t-1} xt−1完成一步推断,循环进行直至得到 x 0 x_0 x0。
3. DDPM 的损失函数设计
DDPM 使用最大似然估计作为优化目标,损失函数为:
L = E q ( x 0 ) [ − log p θ ( x 0 ) ] L = \mathbb{E}_{q(x_0)}[-\log p_{\theta}(x_0)] L=Eq(x0)[−logpθ(x0)]
应用变分下限 (Variational Lower Bound, VLB) 优化负对数似然,在原始损失函数 L L L的基础上,引入一项KL散度 D K L ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) D_{KL}(q(x_{1:T} \mid x_0) \parallel p_{\theta}(x_{1:T} \mid x_0)) DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))。KL散度的值非负,所以满足下列不等式:
E q ( x 0 ) [ − log p θ ( x 0 ) ] ≤ E q ( x 0 ) [ − log p θ ( x 0 ) + D K L ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) ] \mathbb{E}_{q(x_0)}[-\log p_{\theta}(x_0)] \leq \mathbb{E}_{q(x_0)}[-\log p_{\theta}(x_0) + D_{KL}(q(x_{1:T} \mid x_0) \parallel p_{\theta}(x_{1:T} \mid x_0))] Eq(x0)[−logpθ(x0)]≤Eq(x0)[−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))]
其中,KL 散度的定义如下:
D K L ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) = ∑ q ( x 1 : T ∣ x 0 ) ⋅ log ( q ( x 1 : T ∣ x 0 ) p θ ( x 1 : T ∣ x 0 ) ) D_{KL}(q(x_{1:T} \mid x_0) \parallel p_{\theta}(x_{1:T} \mid x_0)) = \sum q(x_{1:T} \mid x_0) \cdot \log \left( \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{1:T} \mid x_0)} \right) DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=∑q(x1:T∣x0)⋅log(pθ(x1:T∣x0)q(x1:T∣x0))
= E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 1 : T ∣ x 0 ) ] = \mathbb{E}_{q(x_{1:T} \mid x_0)} \left[ \log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{1:T} \mid x_0)} \right] =Eq(x1:T∣x0)[logpθ(x1:T∣x0)q(x1:T∣x0)]
将其代入到上述公式中,并应用贝叶斯公式进行化简,有:
E q ( x 0 ) [ − log p θ ( x 0 ) ] \mathbb{E}_{q(x_0)}[-\log p_{\theta}(x_0)] Eq(x0)[−logpθ(x0)]
≤ E q ( x 0 ) [ − log p θ ( x 0 ) + E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 1 : T ∣ x 0 ) ] ] \leq \mathbb{E}_{q(x_0)}\left[-\log p_{\theta}(x_0) + \mathbb{E}_{q(x_{1:T} \mid x_0)}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{1:T} \mid x_0)}\right]\right] ≤Eq(x0)[−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x1:T∣x0)q(x1:T∣x0)]]
= E q ( x 0 ) [ − log p θ ( x 0 ) + E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] ] = \mathbb{E}_{q(x_0)}\left[-\log p_{\theta}(x_0) + \mathbb{E}_{q(x_{1:T} \mid x_0)}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{0:T})/p_{\theta}(x_0)}\right]\right] =Eq(x0)[−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]]
= E q ( x 0 ) [ − log p θ ( x 0 ) + E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) + log p θ ( x 0 ) ] ] = \mathbb{E}_{q(x_0)}\left[-\log p_{\theta}(x_0) + \mathbb{E}_{q(x_{1:T} \mid x_0)}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{0:T})} + \log p_{\theta}(x_0)\right]\right] =Eq(x0)[−logpθ(x0)+Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]]
= E q ( x 0 ) [ E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] ] = \mathbb{E}_{q(x_0)}\left[\mathbb{E}_{q(x_{1:T} \mid x_0)}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{0:T})}\right]\right] =Eq(x0)[Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]]
= E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = L V L B = \mathbb{E}_{q(x_{0:T})}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{0:T})}\right] = L_{VLB} =Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]=LVLB
此时,DDPM 的优化目标可以从最小化 L L L转换为最小化 L V L B L_{VLB} LVLB,由前向过程和逆向过程的介绍可知 q ( x 1 : T ∣ x 0 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T} \mid x_0) = \prod_{t=1}^{T} q(x_t \mid x_{t-1}) q(x1:T∣x0)=∏t=1Tq(xt∣xt−1), p θ ( x 0 : T ) = p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{0:T}) = p_{\theta}(x_T) \prod_{t=1}^{T} p_{\theta}(x_{t-1} \mid x_t) pθ(x0:T)=pθ(xT)∏t=1Tpθ(xt−1∣xt),代入上面的公式可进一步推导得出:
L V L B L_{VLB} LVLB
= E q ( x 0 : T ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] = \mathbb{E}_{q(x_{0:T})}\left[\log \frac{q(x_{1:T} \mid x_0)}{p_{\theta}(x_{0:T})}\right] =Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]
= E q ( x 0 : T ) [ log ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ] = \mathbb{E}_{q(x_{0:T})}\left[\log \frac{\prod_{t=1}^{T} q(x_t \mid x_{t-1})}{p_{\theta}(x_T) \prod_{t=1}^{T} p_{\theta}(x_{t-1} \mid x_t)}\right] =Eq(x0:T)[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 1 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=1}^{T} \log \frac{q(x_t \mid x_{t-1})}{p_{\theta}(x_{t-1} \mid x_t)}\right] =Eq(x0:T)[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=2}^{T} \log \frac{q(x_t \mid x_{t-1})}{p_{\theta}(x_{t-1} \mid x_t)} + \log \frac{q(x_1 \mid x_0)}{p_{\theta}(x_0 \mid x_1)}\right] =Eq(x0:T)[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) p θ ( x t − 1 ∣ x t ) q ( x t − 1 ∣ x 0 ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=2}^{T} \log \left(\frac{q(x_{t-1} \mid x_t, x_0) q(x_t \mid x_0)}{p_{\theta}(x_{t-1} \mid x_t) q(x_{t-1} \mid x_0)}\right) + \log \frac{q(x_1 \mid x_0)}{p_{\theta}(x_0 \mid x_1)}\right] =Eq(x0:T)[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣x0)q(xt−1∣xt,x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + ∑ t = 2 T log q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=2}^{T} \log \frac{q(x_{t-1} \mid x_t, x_0)}{p_{\theta}(x_{t-1} \mid x_t)} + \sum_{t=2}^{T} \log \frac{q(x_t \mid x_0)}{q(x_{t-1} \mid x_0)} + \log \frac{q(x_1 \mid x_0)}{p_{\theta}(x_0 \mid x_1)}\right] =Eq(x0:T)[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log ∏ t = 2 T q ( x t ∣ x 0 ) q ( x t − 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=2}^{T} \log \frac{q(x_{t-1} \mid x_t, x_0)}{p_{\theta}(x_{t-1} \mid x_t)} + \log \prod_{t=2}^{T} \frac{q(x_t \mid x_0)}{q(x_{t-1} \mid x_0)} + \log \frac{q(x_1 \mid x_0)}{p_{\theta}(x_0 \mid x_1)}\right] =Eq(x0:T)[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logt=2∏Tq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]
= E q ( x 0 : T ) [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[-\log p_{\theta}(x_T) + \sum_{t=2}^{T} \log \frac{q(x_{t-1} \mid x_t, x_0)}{p_{\theta}(x_{t-1} \mid x_t)} + \log \frac{q(x_T \mid x_0)}{q(x_1 \mid x_0)} + \log \frac{q(x_1 \mid x_0)}{p_{\theta}(x_0 \mid x_1)}\right] =Eq(x0:T)[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]
= E q ( x 0 : T ) [ log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) 1 p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) ] = \mathbb{E}_{q(x_{0:T})}\left[\log \frac{q(x_T \mid x_0) q(x_1 \mid x_0)}{q(x_1 \mid x_0) p_{\theta}(x_0 \mid x_1)} \frac{1}{p_{\theta}(x_T)} + \sum_{t=2}^{T} \log \frac{q(x_{t-1} \mid x_t, x_0)}{p_{\theta}(x_{t-1} \mid x_t)}\right] =Eq(x0:T)[logq(x1∣x0)pθ(x0∣x1)q(xT∣x0)q(x1∣x0)pθ(xT)1+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)]
= E q ( x 0 : T ) [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x t , x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[\log \frac{q(x_T \mid x_0)}{p_{\theta}(x_T)} + \sum_{t=2}^{T} \log \frac{q(x_{t-1} \mid x_t, x_0)}{p_{\theta}(x_{t-1} \mid x_t)} - \log p_{\theta}(x_0 \mid x_1)\right] =Eq(x0:T)[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]
= E q ( x 0 : T ) [ D K L ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) − log p θ ( x 0 ∣ x 1 ) ] = \mathbb{E}_{q(x_{0:T})}\left[D_{KL}(q(x_T \mid x_0) \parallel p_{\theta}(x_T)) + \sum_{t=2}^{T} D_{KL}(q(x_{t-1} \mid x_t, x_0) \parallel p_{\theta}(x_{t-1} \mid x_t)) - \log p_{\theta}(x_0 \mid x_1)\right] =Eq(x0:T)[DKL(q(xT∣x0)∥pθ(xT))+t=2∑TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−logpθ(x0∣x1)]
DDPM 对上述优化目标进行了简化,只考虑公式中计算分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0)与 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t-1} \mid x_t) pθ(xt−1∣xt)之间的KL散度部分:
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β ~ t I ) q(x_{t-1} \mid x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I) q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x − t , t ) , Σ θ ( x t , t ) ) = N ( x t − 1 ; μ θ ( x − t , t ) , β ~ t I ) p_{\theta}(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_{-t}, t), \Sigma_{\theta}(x_t, t)) = \mathcal{N}(x_{t-1}; \mu_{\theta}(x_{-t}, t), \tilde{\beta}_t I) pθ(xt−1∣xt)=N(xt−1;μθ(x−t,t),Σθ(xt,t))=N(xt−1;μθ(x−t,t),β~tI)
因此:
L t = D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) L_t = D_{KL}(q(x_{t-1} \mid x_t, x_0) \parallel p_{\theta}(x_{t-1} \mid x_t)) Lt=DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))
= [ 1 2 β t ∥ μ ~ t ( x t , x 0 ) − μ θ ( x − t , t ) ∥ 2 ] = \left[ \frac{1}{2 \beta_t} \| \tilde{\mu}_t(x_t, x_0) - \mu_{\theta}(x_{-t}, t) \|^2 \right] =[2βt1∥μ~t(xt,x0)−μθ(x−t,t)∥2]
= E x 0 , ϵ 0 ˉ [ 1 2 β t ∥ 1 α t ( x t − β t 1 − α ˉ t ϵ 0 ˉ ) − 1 α t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = \mathbb{E}_{x_0, \bar{\epsilon_0}} \left[ \frac{1}{2 \beta_t} \| \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \bar{\epsilon_0} \right) - \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_{\theta}(x_t, t) \right) \|^2 \right] =Ex0,ϵ0ˉ[2βt1∥αt1(xt−1−αˉtβtϵ0ˉ)−αt1(xt−1−αˉtβtϵθ(xt,t))∥2]
= E x 0 , ϵ 0 ˉ [ β t 2 2 β t α t ( 1 − α ˉ t ) ∥ ϵ 0 ˉ − ϵ θ ( x t , t ) ∥ 2 ] = \mathbb{E}_{x_0, \bar{\epsilon_0}} \left[ \frac{\beta_t^2}{2 \beta_t \alpha_t (1 - \bar{\alpha}_t)} \| \bar{\epsilon_0} - \epsilon_{\theta}(x_t, t) \|^2 \right] =Ex0,ϵ0ˉ[2βtαt(1−αˉt)βt2∥ϵ0ˉ−ϵθ(xt,t)∥2]
= E x 0 , ϵ 0 ˉ [ β t 2 2 β t α t ( 1 − α ˉ t ) ∥ ϵ 0 ˉ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ 0 ˉ , t ) ∥ 2 ] = \mathbb{E}_{x_0, \bar{\epsilon_0}} \left[ \frac{\beta_t^2}{2 \beta_t \alpha_t (1 - \bar{\alpha}_t)} \| \bar{\epsilon_0} - \epsilon_{\theta}(\sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \bar{\epsilon_0}, t) \|^2 \right] =Ex0,ϵ0ˉ[2βtαt(1−αˉt)βt2∥ϵ0ˉ−ϵθ(αˉtx0+1−αˉtϵ0ˉ,t)∥2]
DDPM 进一步对 L t L_t Lt进行简化,得到:
L s i m p l e = E x 0 , ϵ 0 ˉ [ ∥ ϵ 0 ˉ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ 0 ˉ , t ) ∥ 2 ] L_{simple} = \mathbb{E}_{x_0, \bar{\epsilon_0}} \left[ \| \bar{\epsilon_0} - \epsilon_{\theta}(\sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \bar{\epsilon_0}, t) \|^2 \right] Lsimple=Ex0,ϵ0ˉ[∥ϵ0ˉ−ϵθ(αˉtx0+1−αˉtϵ0ˉ,t)∥2]
由此可见:DDPM 最终损失函数的核心就是最小化采样的真实噪声 ϵ 0 ˉ \bar{\epsilon_0} ϵ0ˉ与模型所预测噪声 ϵ θ \epsilon_{\theta} ϵθ之间的均方误差损失。
下一篇推文来用代码实战一下怎么做一个DDPM模型。

















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











