






yolov5s 的三个检测层分别检测小、中、大目标。
若输入图像尺寸=640X640,
# P3/8 对应的检测特征图大小为80X80,用于检测大小在8X8以上的目标。
# P4/16对应的检测特征图大小为40X40,用于检测大小在16X16以上的目标。
# P5/32对应的检测特征图大小为20X20,用于检测大小在32X32以上的目标。
如果你的数据集有一部分是由小目标组成的,常见的改进方法是额外地添加一个检测层,最后用四层结构进行预测,这类方法可以参考这篇博客:目标检测算法——YOLOv5改进|增加小目标检测层_小目标 yolov5-CSDN博客
但是如果你的数据集是只有小目标的,比如wideface这些公开数据集,目标大小普遍在8x8及以下,而P5对应的检测特征图大小为20X20,用于检测大小在32X32以上的目标,这一层就显得多余了,不仅不会带来精度的提升,反而增加了计算量和推理速度。所以我们在额外添加一个小目标检测层的同时,再把用于检测大目标的检测层删除。方法也非常简单,就是在原来四层结构的基础上删除p5层及对应一些的结构。下图是原来的四层结构。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 6 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P2
[-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P3
[-1, 3, C3, [256, False]], # 24 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 27 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 30 (P5/32-large)
[[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]本文的结构:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors: 3 # AutoAnchor evolves 3 anchors per P output layer
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head with (P2, P3, P4, P5) outputs
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P2
[-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P3
[-1, 3, C3, [256, False]], # 24 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 27 (P4/16-medium)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
]我们来看看改进前后的对比效果:
yolov5s模型检测图:

本文模型检测图:

可以看到我们的模型检测出了yolov5s漏检的许多目标(蓝色箭头区域所示),对密集的小目标场景更加友好,且保留了三层检测层结构,在提高小目标检测精度的同时还减少了参数量,提升了推理速度,但是带来了计算复杂度的小幅增加,如图下图。本人选取了1/3的widerface数据集进行训练,效果对比yolov5s,map50提升了3%左右,有兴趣的伙伴可以尝试。
原yolov5s模型:

本文模型:
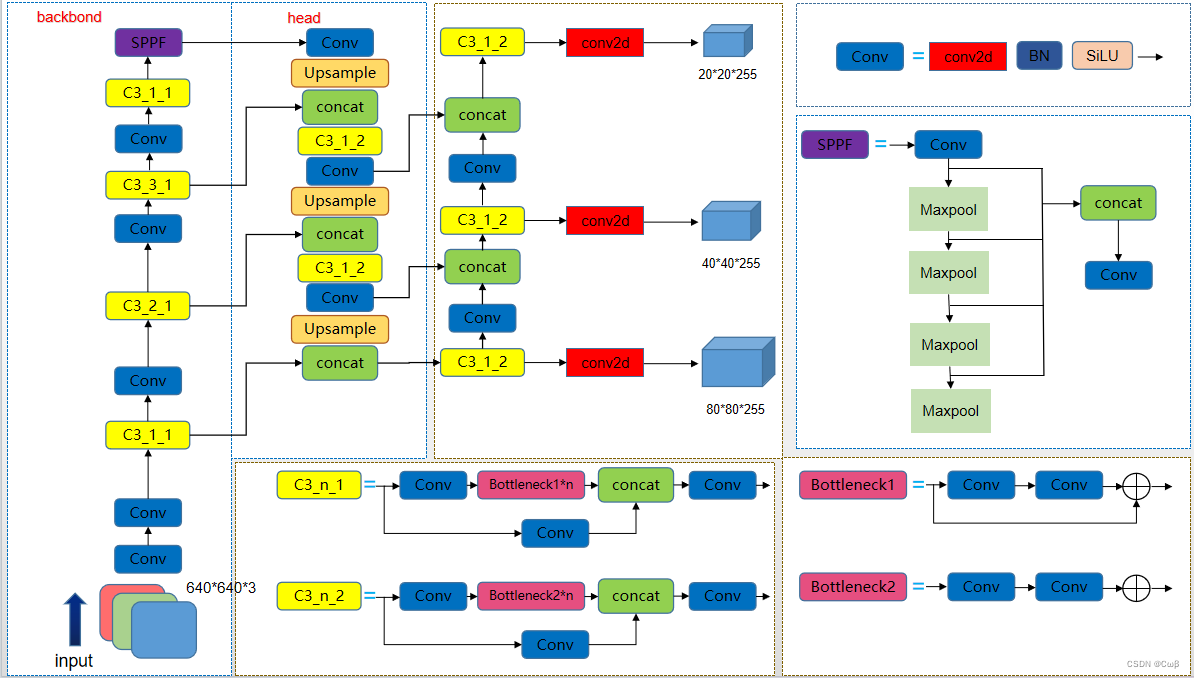
改进后的网络结构示意图如下:















 1253
1253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









