







VAR code 下载地址:https://github.com/FoundationVision/VAR
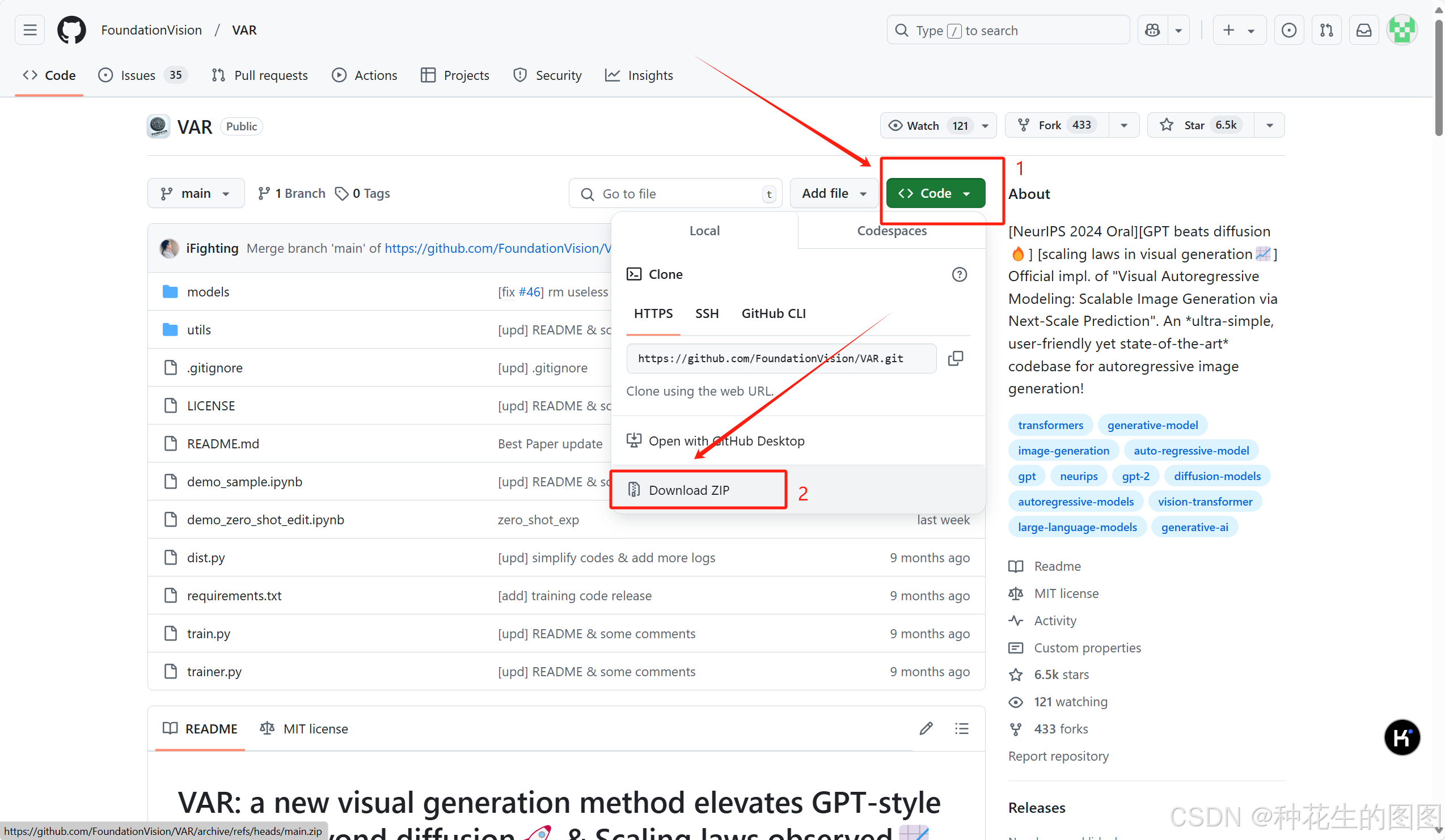
一、模型部署
本模型推理和训练使用的是 Autodl 云服务器,如果在本地部署,可以跳过此阶段看环境配置。
1、Autodl 云服务器
1、租服务器
Autodl 服务器地址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
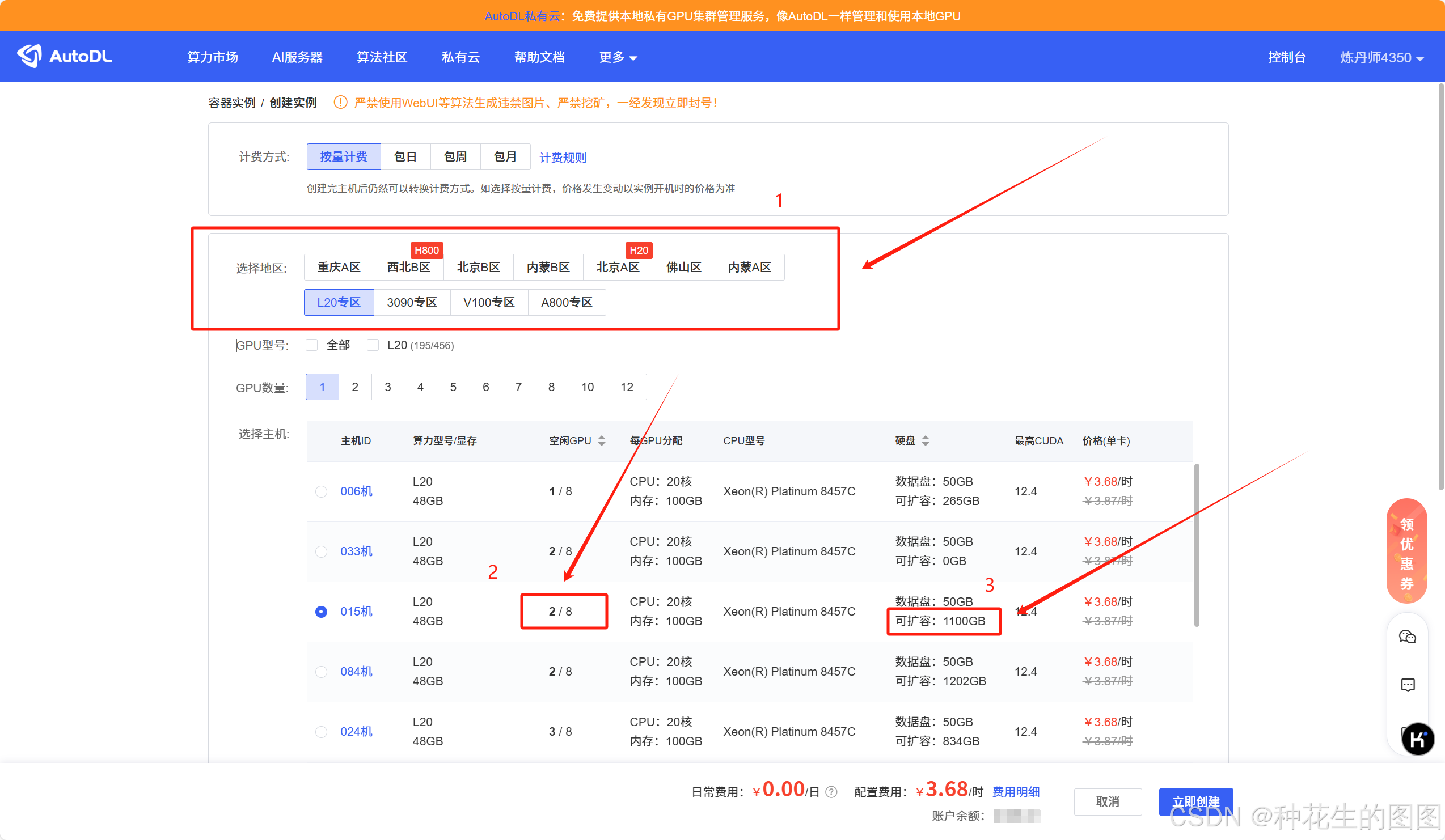
租服务器主要需要考虑的我感觉只有三点:
- 选择一个合适的地区。
- 选择一个空闲GPU 比较多的机器,如果空闲GPU 很少的话,你可能关机后再次开机会有没机器的情况,要等很久。
- 选择一个可扩容的机器,后期如果数据集和模型等比较大的话,可以扩容的机器会方便很多。
之后就是选择一个镜像,因为我习惯在云服务器也使用 conda 环境,所有这里的镜像就可以随便选择一下。
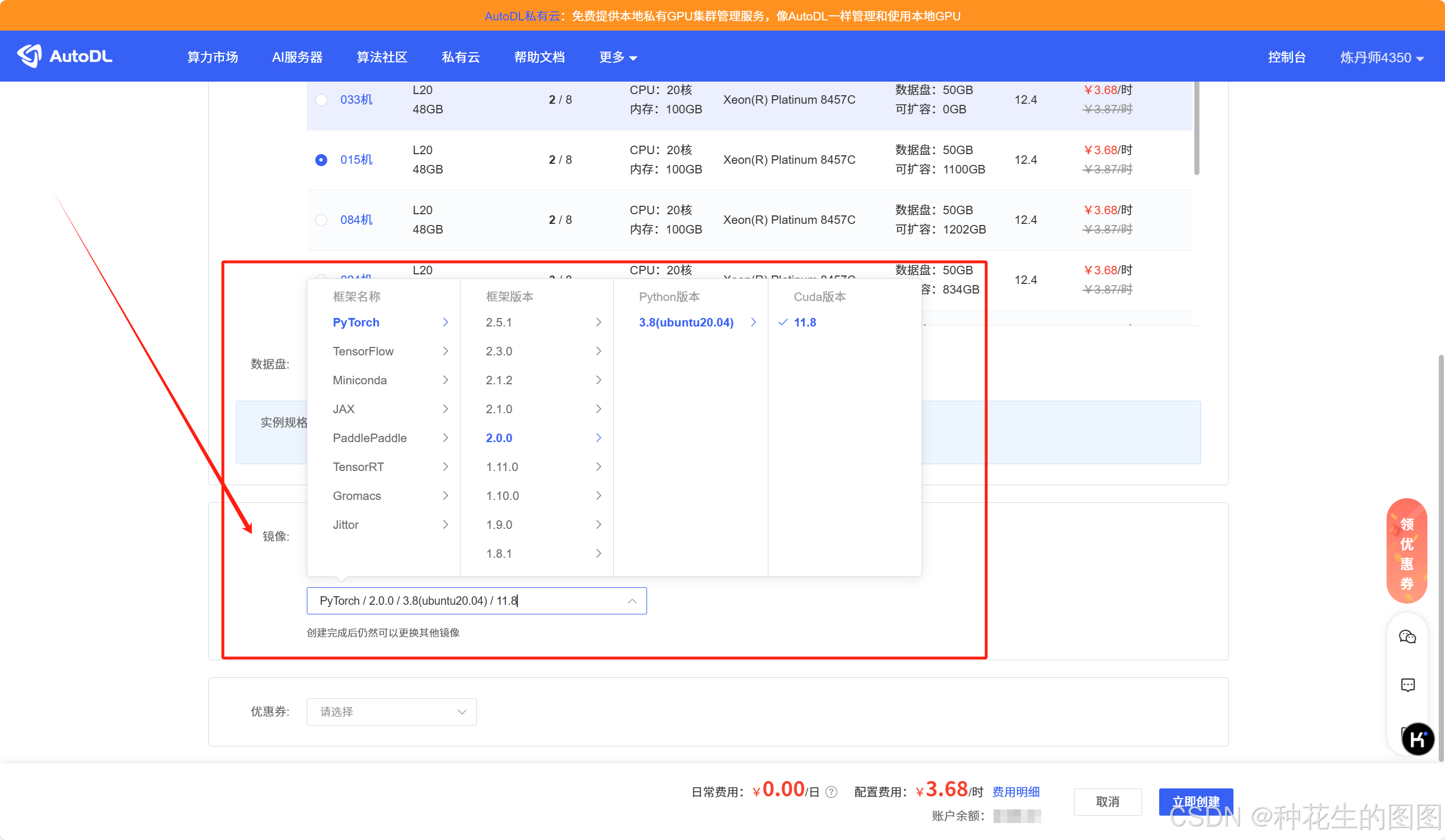
之后,点击“立即创建”,则成功创建出一个云服务器。

2、激活 conda 环境
详情请看这篇博客:Autodl目前遇到的相关问题及其解决方案_autodl conda-CSDN博客
2、模型上传
(1)复制登录指令

(2)打开xshell ,粘贴登录指令,将指令中的数字输入到端口号里面,指令中 @ 之前的全部删除。
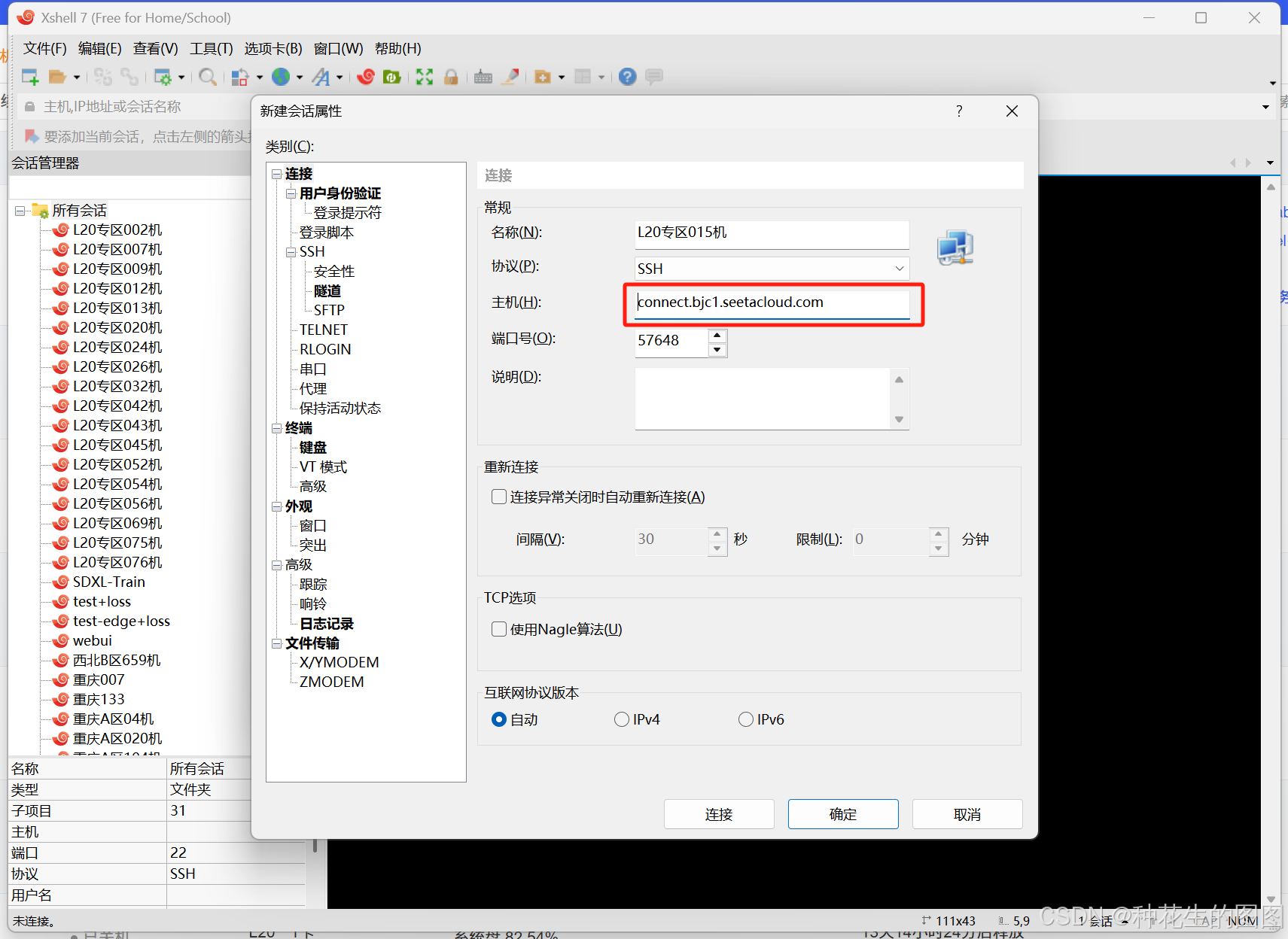
(3)登录名选择 root
(4)返回 Autodl ,复制密码

(5)粘贴密码
(6)连接成功后,点击
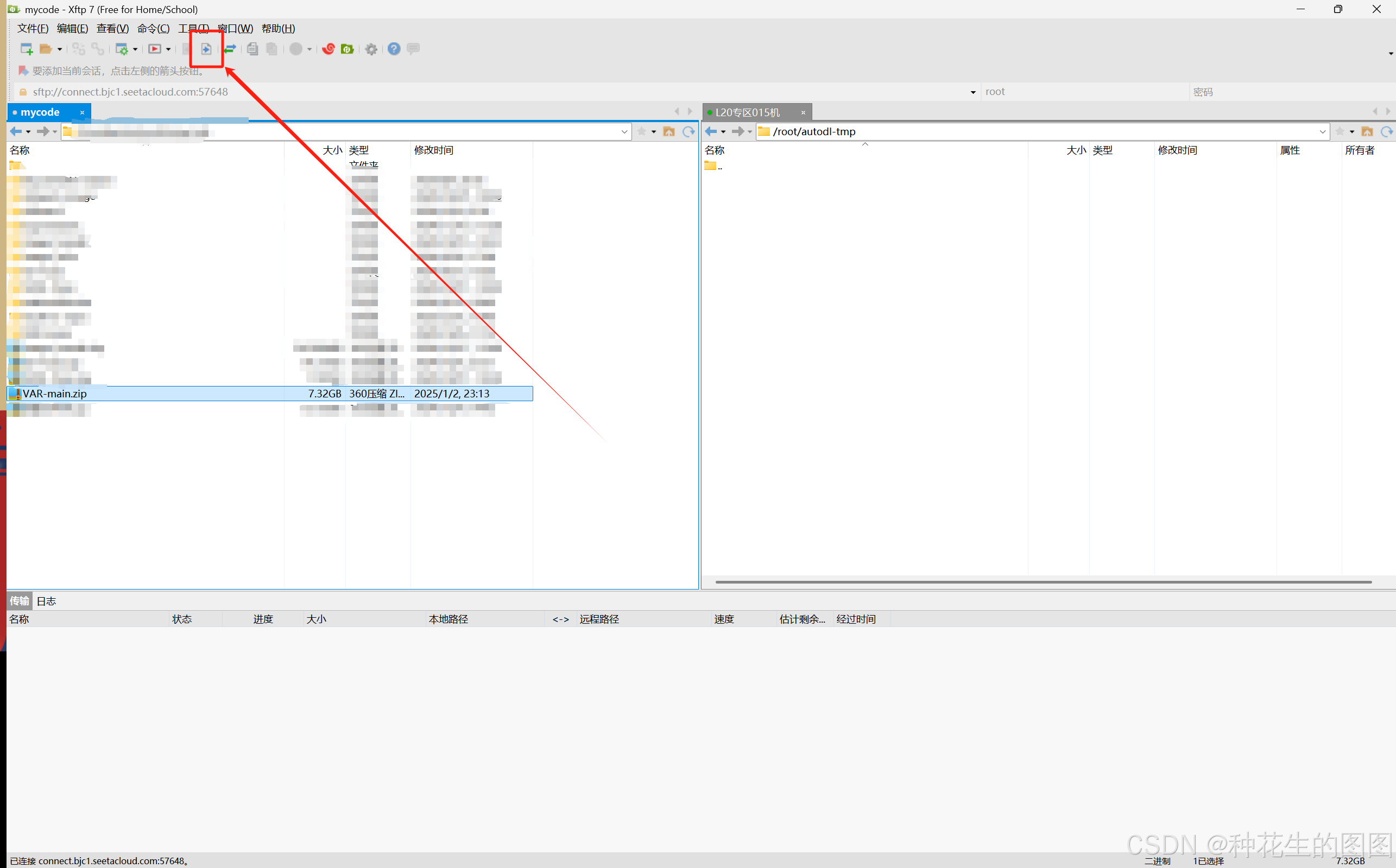
(7)选中 VAR-main ,点击上传即可
3、环境配置
(1)解压 VAR-main 模型
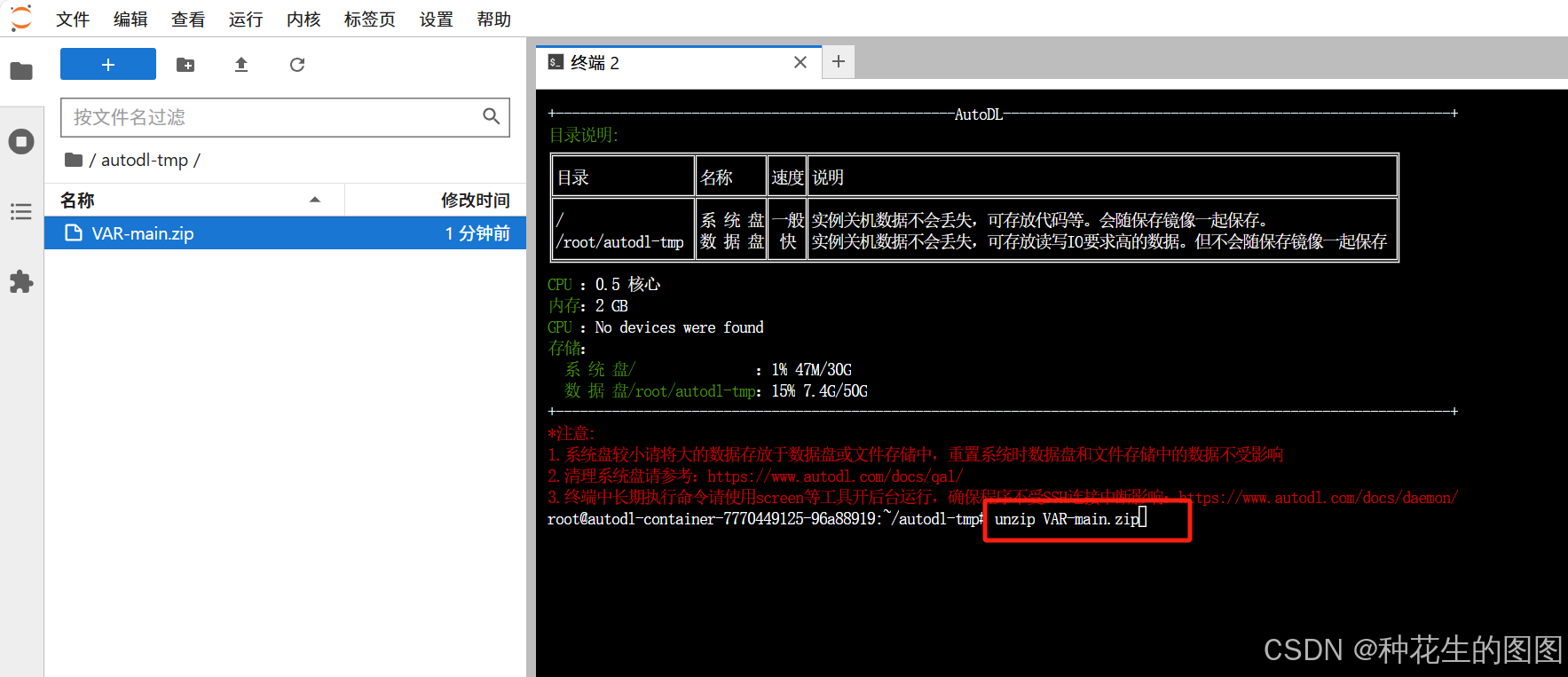
unzip VAR-main.zip(2) 创建 conda 环境
conda create -n VAR python=3.9(3)激活环境
conda activate VAR(4)进入到 VAR-mian 的文件夹里
cd VAR-main(5)下载环境
pip install -r requirements.txt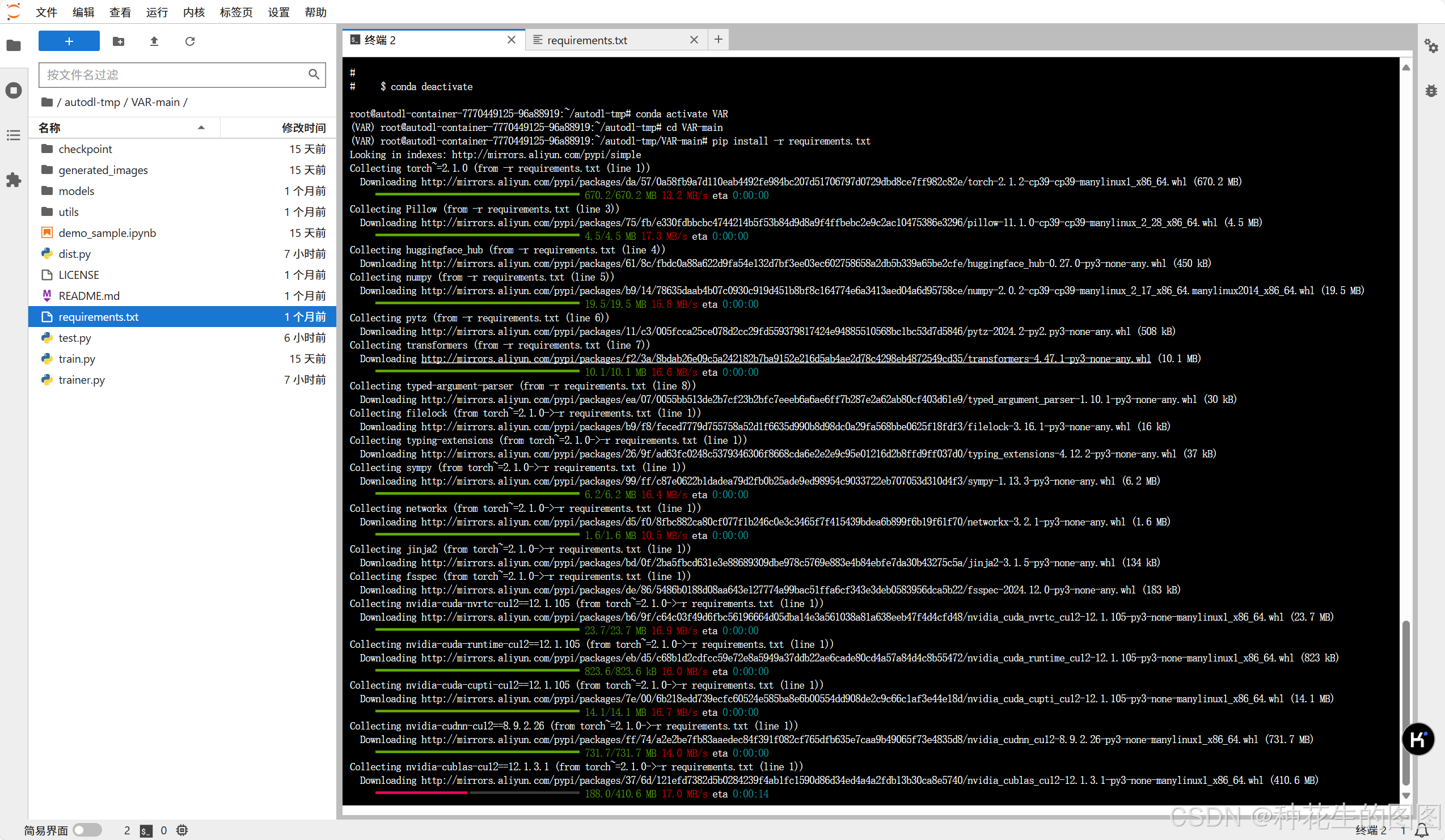
4、报错
(1)numpy 版本不匹配
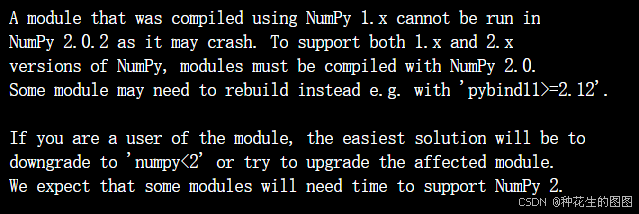
解决方案:降低 numpy 版本
pip install numpy==1.22.4(2)没有 torchvision
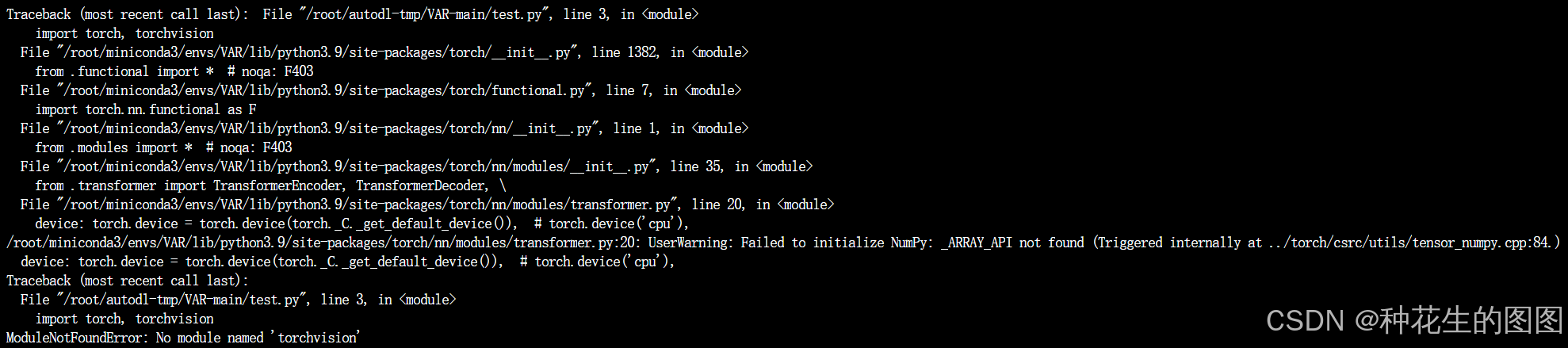
解决方案:重新下载一个torchvision
pip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple/二、推理
1、推理代码:
首先需要去 VAR 模型的 GitHub 仓库下载两个模型权重:
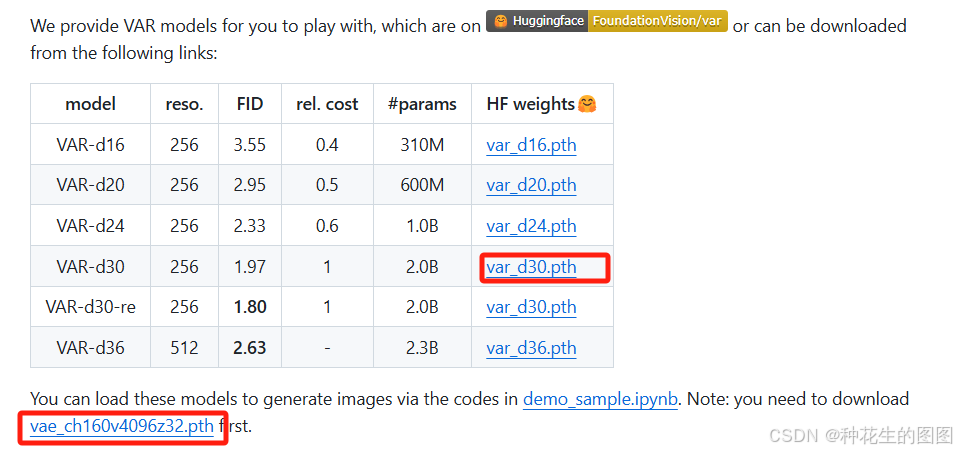
之后保存到本地,新建一个 checkpoint 文件夹用于存放模型
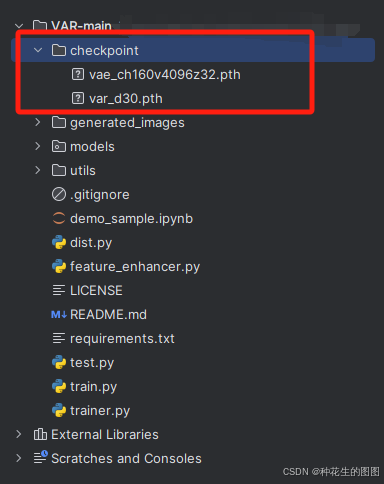
在推理代码中,更改 vae_ckpt 和 var_ckpt 的文件目录。点击运行即可运行程序。
vae_ckpt = './checkpoint/vae_ch160v4096z32.pth'
var_ckpt = f'./checkpoint/var_d{MODEL_DEPTH}.pth'其中,模型是通过标签进行生成图像,修改不同的标签数值,可以生成不同的图像
class_labels = (980, 980, 437, 437) # 类别标签,指定每个样本的标签(用于条件生成)推理代码如下 :
import os
import os.path as osp
import torch, torchvision
import random
import numpy as np
import PIL.Image as PImage, PIL.ImageDraw as PImageDraw
# 通过禁用默认的参数初始化方法来提高速度
setattr(torch.nn.Linear, 'reset_parameters', lambda self: None) # 禁用 Linear 层的参数初始化
setattr(torch.nn.LayerNorm, 'reset_parameters', lambda self: None) # 禁用 LayerNorm 层的参数初始化
# 导入模型构建函数
from models import VQVAE, build_vae_var
MODEL_DEPTH = 30 # TODO: =====>请指定模型的深度<=====
assert MODEL_DEPTH in {16, 20, 24, 30} # 确保模型深度是合法的(16, 20, 24, 30)
# 指定本地文件路径(假设权重文件下载到当前目录)
vae_ckpt = './checkpoint/vae_ch160v4096z32.pth'
var_ckpt = f'./checkpoint/var_d{MODEL_DEPTH}.pth'
# 如果 VAE 或 VAR 的检查点文件不存在,则从 Hugging Face 下载
# 若文件已存在,本行代码会被跳过
if not osp.exists(vae_ckpt):
print(f"VAE checkpoint not found locally. Please download it: {vae_ckpt}")
if not osp.exists(var_ckpt):
print(f"VAR checkpoint not found locally. Please download it: {var_ckpt}")
# 构建 VAE 和 VAR 模型
patch_nums = (1, 2, 3, 4, 5, 6, 8, 10, 13, 16)
device = 'cuda' if torch.cuda.is_available() else 'cpu' # 如果 GPU 可用,则使用 GPU 否则使用 CPU
if 'vae' not in globals() or 'var' not in globals(): # 如果 VAE 或 VAR 模型尚未定义
vae, var = build_vae_var(
V=4096, Cvae=32, ch=160, share_quant_resi=4, # hard-coded VQVAE hyperparameters
device=device, patch_nums=patch_nums,
num_classes=1000, depth=MODEL_DEPTH, shared_aln=False,
)
# 加载模型的检查点文件
vae.load_state_dict(torch.load(vae_ckpt, map_location='cpu'), strict=True)
var.load_state_dict(torch.load(var_ckpt, map_location='cpu'), strict=True)
# 将模型设置为评估模式(禁用 dropout 和 batch normalization 等训练特性)
vae.eval(), var.eval()
for p in vae.parameters(): p.requires_grad_(False) # 禁用 VAE 模型参数的梯度计算
for p in var.parameters(): p.requires_grad_(False) # 禁用 VAR 模型参数的梯度计算
print(f'prepare finished.') # 输出准备完成的消息
# 设置一些参数
seed = 0 # 随机种子,确保实验的可重复性
torch.manual_seed(seed) # 设置 PyTorch 的随机种子
num_sampling_steps = 250 # 采样步数,用于生成图像时的迭代次数
cfg = 4 # Classifier-Free Guidance (CFG) 强度,决定条件引导的权重
class_labels = (980, 980, 437, 437) # 类别标签,指定每个样本的标签(用于条件生成)
more_smooth = False # 设置是否使用平滑输出(True 表示使用,False 表示不使用)
# 设置随机种子,确保实验的可重复性
torch.manual_seed(seed) # 设置 PyTorch 随机种子
random.seed(seed) # 设置 Python 的随机模块种子
np.random.seed(seed) # 设置 NumPy 的随机种子
torch.backends.cudnn.deterministic = True # 使用确定性算法(确保每次运行的结果相同)
torch.backends.cudnn.benchmark = False # 禁用 cudnn 优化,因为我们不需要提高计算性能
# 配置使用 TF32 计算(仅适用于支持 TF32 的硬件,如 A100)
tf32 = True # 设置是否启用 TF32
torch.backends.cudnn.allow_tf32 = bool(tf32) # 设置 cudnn 允许使用 TF32
torch.backends.cuda.matmul.allow_tf32 = bool(tf32) # 设置 CUDA 计算允许使用 TF32
torch.set_float32_matmul_precision('high' if tf32 else 'highest') # 设置浮点数矩阵乘法精度
# 采样过程
B = len(class_labels) # B 是样本的数量(即类标签的数量)
label_B: torch.LongTensor = torch.tensor(class_labels, device=device) # 将类标签转换为张量,并放置到指定设备上
# 使用推理模式进行采样
with torch.inference_mode(): # 禁用梯度计算,提升推理速度
with torch.autocast('cuda', enabled=True, dtype=torch.float16, cache_enabled=True): # 使用混合精度(bfloat16 或 float16)
# 使用自回归推理与 Classifier-Free Guidance (CFG)
recon_B3HW = var.autoregressive_infer_cfg(
B=B, # 样本数量
label_B=label_B, # 类别标签
cfg=cfg, # CFG 强度
top_k=900, # 限制采样的候选个数,决定生成过程的多样性
top_p=0.95, # 限制采样的累积概率,进一步控制生成多样性
g_seed=seed, # 随机种子,确保结果的可重复性
more_smooth=more_smooth # 是否要求更平滑的输出(可控制生成图像的平滑度)
)
# 保存图像
output_dir = 'generated_images' # 保存图像的文件夹
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 保存每张生成的图像
for idx, img_tensor in enumerate(recon_B3HW):
img = img_tensor.permute(1, 2, 0).mul(255).byte().cpu().numpy()
pil_img = PImage.fromarray(img)
image_filename = os.path.join(output_dir, f'generated_image_{idx+1}.png')
pil_img.save(image_filename)
print(f"Image {idx+1} saved at: {image_filename}")
# 显示图像
chw = torchvision.utils.make_grid(recon_B3HW, nrow=1, padding=0, pad_value=1.0)
chw = chw.permute(1, 2, 0).mul_(255).cpu().numpy()
chw = PImage.fromarray(chw.astype(np.uint8))
chw.show()
生成四张效果图:




三、Train
1、构建数据集
格式如下:
├── train/ # 训练集
│ ├── n01440764/ # 类别1的文件夹(对应标签索引0)
│ │ ├── image1.JPEG
│ │ └── image2.JPEG
│ ├── n01443537/ # 类别2的文件夹(对应标签索引1)
│ └── ...
└── val/ # 验证集
├── n01440764/ # 类别结构同训练集(用于验证准确性)
├── n01443537/
└── ...2、修改数据集路径
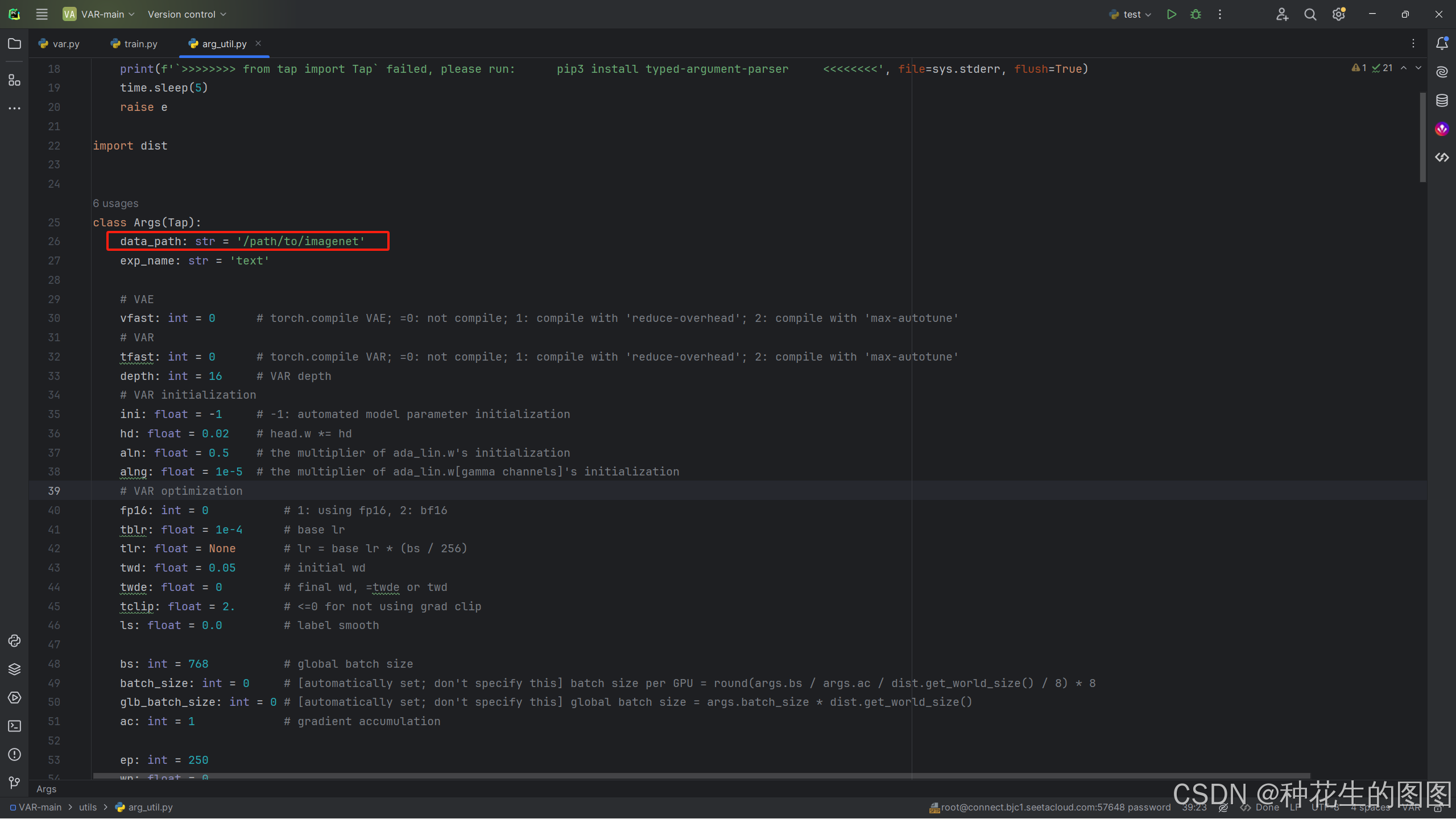
找到文件 utils/arg_util.py
修改成你自己数据集的路径
3、训练
命令如下:
# d16, 256x256
torchrun --nproc_per_node=8 train.py \
--depth=16 --bs=768 --ep=200 --fp16=1 --alng=1e-3 --wpe=0.1
# d20, 256x256
torchrun --nproc_per_node=8 train.py \
--depth=20 --bs=768 --ep=250 --fp16=1 --alng=1e-3 --wpe=0.1
# d24, 256x256
torchrun --nproc_per_node=8 train.py \
--depth=24 --bs=768 --ep=350 --tblr=8e-5 --fp16=1 --alng=1e-4 --wpe=0.01
# d30, 256x256
torchrun --nproc_per_node=8 train.py \
--depth=30 --bs=1024 --ep=350 --tblr=8e-5 --fp16=1 --alng=1e-5 --wpe=0.01 --twde=0.08
# d36-s, 512x512 (-s means saln=1, shared AdaLN)
torchrun --nproc_per_node=8 train.py \
--depth=36 --saln=1 --pn=512 --bs=768 --ep=350 --tblr=8e-5 --fp16=1 --alng=5e-6 --wpe=0.01 --twde=0.08torchrun \
--nproc_per_node=8 \ # 每个节点的 GPU 数量
train.py \ # 训练脚本
--depth=16 \ # 模型深度
--bs=768 \ # 全局批次大小(batch_size)
--ep=200 \ # 训练轮数(epochs)
--fp16=1 \ # 启用混合精度训练
--alng=1e-3 \ # 学习率(lr)
--wpe=0.1 # 权重衰减(weight decay)
















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









